
在 Kubernetes 上构建大规模 Flink 自服务平台
在 Instacart,我们有一些需要低延迟的数据管道,每年处理超过两万亿的事件。这些事件帮助我们的工程和产品团队做出更好的决策,并深入了解业务。为了利用这些实时事件来扩展我们的业务,我们在 2021 年底采用了 Apache Flink 作为我们的实时分布式处理引擎。Flink 提供了低延迟、高吞吐量、强保证、状态管理和简单重放等优秀的特性。
 到目前为止,我们已经使用 Flink 满足了一系列的需求:
到目前为止,我们已经使用 Flink 满足了一系列的需求:
实时决策,如欺诈/垃圾邮件检测
实时数据增强,如分类数据管道
机器学习实时特性生成
我们实验平台的 OLAP 事件摄取
Flink 平台如何帮助我们处理数据和事件
Flink 平台作为我们核心的流式计算引擎,在处理数据和事件方面提供了巨大的帮助。它使我们能够以高可扩展性和可靠性实时处理和分析大量数据。Flink 的流式架构使我们能够在数据一到达系统时就处理它,而不必等待收集大批数据。例如我们将其用作实时事件路由,这使用户能够在几毫秒内将事件从单个事件摄取 Kafka Topic 路由到他们自己的子 Kafka Topic。此外,Flink 的分布式架构使我们能够并行处理大量数据,作为我们的 OLAP 数据加载服务,我们可以实现远超单台机器能处理的吞吐量。最后,Flink 丰富的连接器和 API 库使我们能够与各种数据源/接收器和应用程序集成,使我们能够以以前无法实现的方式从数据中获得结果。
#02
在 EMR 上扩展 Flink 平台的挑战
当我们开始使用 Flink 作为流式计算引擎时,我们在 AWS EMR 集群上部署了所有的 Flink 作业。在 EMR 集群上运行 Flink 是一个很好的起点,因为 EMR 集群默认带有 Flink 和 Hadoop 等大数据框架。在过去的 10 个月里,我们接入了超过 50 个产品团队运行他们的 Flink 管道。在数据基础设施团队内部,我们增加了 500 个 Flink 数据摄取管道。为了满足高需求,我们需要将作业所有权委托给产品团队,并使我们的平台可以自助。然而在 EMR 上运行 Flink 无法满足如此高的需求,此外,缺乏原生工具使 Flink 在 EMR 上的自助运行变得困难。
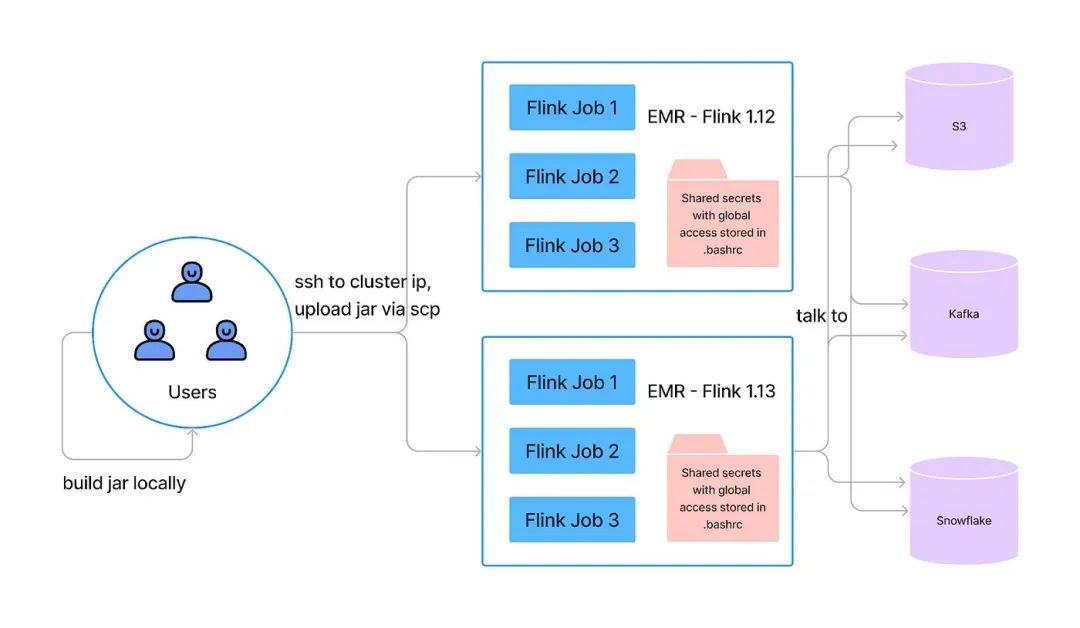
下图展示了在 EMR 上的 Flink 流程,它有几个主要问题:
缺乏服务的私密或配置管理,没有服务级别的资源隔离。
AWS 权限模型只能应用于 EMR 的集群级别,所以为了加速服务接入,所有服务都在运行全局权限。
用户必须通过 SSH 与集群节点进行交互进行作业管理。集群上没有安装安全和审计工具。
EMR 或作业失败恢复机制没有良好的自动扩展机制支持。因此,Flink 服务操作负担较高。
单个 EMR 集群不支持多个 Flink 版本,我们的 Flink 服务运行在 Flink 1.12 到 Flink 1.15 之间。因此,我们必须管理大约 75 个 EMR 集群。
没有 CI/CD 支持。在 EMR 上运行的 Flink 不是容器化的,所以它不能与 Instacart 标准的 CI/CD 管道集成。
随
着我们托管的 Flink 作业数量的增加,上述主要问题对我们的实时数据管道构成了可靠性威胁,并限制了我们的团队操作/支持能力。
 Kubernetes(也称为 K8s)是一个开源的容器编排平台,它使我们能够轻松地部署、扩展和管理应用程序和服务。通过 K8s,我们现在可以轻松管理应用程序,同时也可以利用其内置的容错和自动扩展能力。此外,它提供了大量的支持良好的工具。内置的容错和自动扩展使得我们能够快速地对负载变化做出反应,同时也确保了应用程序始终在最佳状态下运行。利用 Kubernetes 工具可以帮助我们以最小的工作以标准的方式部署应用程序。Flink 在 2019 年引入了对 Kubernetes 的官方支持,这种方法近年来越来越受欢迎。Flink 社区在 2022 年初也正式推出了他们的 Flink K8s Operator 项目,这大大减少了人工运维负担和维护成本。下面是我们在 EKS(Amazon Elastic Kubernetes Service)上的 Flink 平台工作流:
Kubernetes(也称为 K8s)是一个开源的容器编排平台,它使我们能够轻松地部署、扩展和管理应用程序和服务。通过 K8s,我们现在可以轻松管理应用程序,同时也可以利用其内置的容错和自动扩展能力。此外,它提供了大量的支持良好的工具。内置的容错和自动扩展使得我们能够快速地对负载变化做出反应,同时也确保了应用程序始终在最佳状态下运行。利用 Kubernetes 工具可以帮助我们以最小的工作以标准的方式部署应用程序。Flink 在 2019 年引入了对 Kubernetes 的官方支持,这种方法近年来越来越受欢迎。Flink 社区在 2022 年初也正式推出了他们的 Flink K8s Operator 项目,这大大减少了人工运维负担和维护成本。下面是我们在 EKS(Amazon Elastic Kubernetes Service)上的 Flink 平台工作流: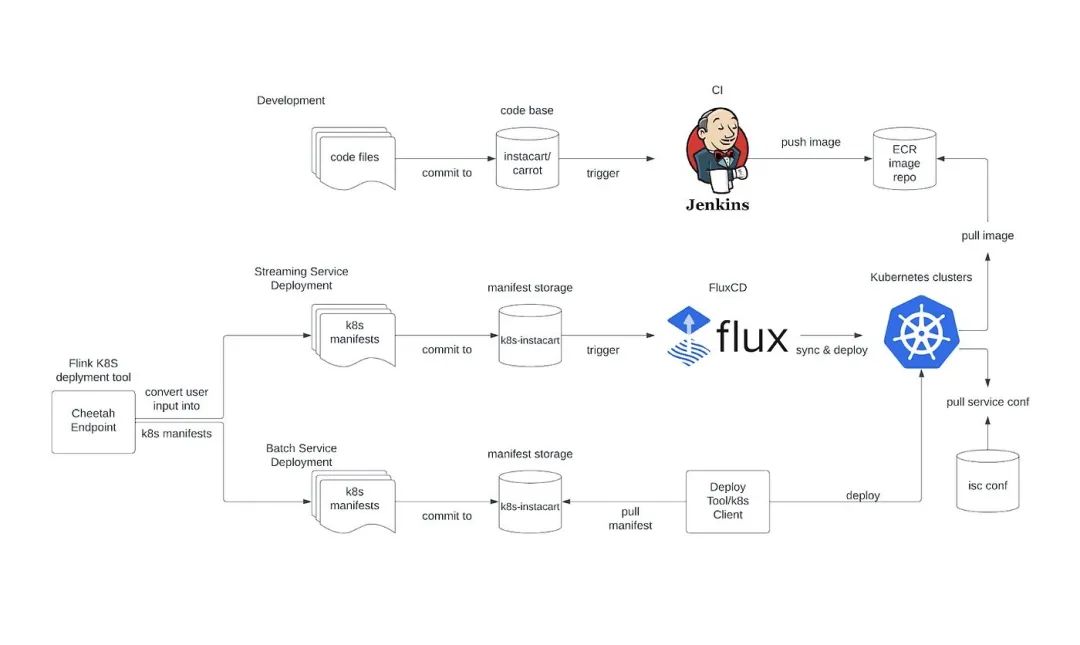
新的服务配置/接入是通过一个端点(Cheetah Endpoint)请求完成的,并由 Instacart Flink K8S 自定义控制器提供支持。Instacart Flink CRD 是 Instacart Flink 部署的抽象,它包含了所有需要的权限、Kubernetes 资源和一个默认的 Flink 部署配置。自定义控制器接受我们的 Cheetah Endpoint 的这个 CRD,然后将其部署到 Kubernetes 集群,并定期重新同步它们的状态。
开发流程与 Instacart 的标准 CI 流程集成,这个流程自动构建应用程序镜像并将它们推送到我们的 ECR(Amazon Elastic Container Registry)仓库。
部署流程采用了 GitOps 的思想,它是通过 FluxCD 集成完成的,FluxCD 会持续监控我们的 K8s 清单仓库的变化。
服务的配置和 Secret 由 Instacart 的配置管理器(isc conf)管理。它提供了一个很好的用户界面,可以通过精确名称匹配或正则表达式进行搜索/创建/替换。
服务管理,如故障恢复、检查点恢复和运行状态检查,是由 Flink K8s Operator 完成的。
每个服务都在其自己的命名空间和服务账户上运行。服务的权限与命名空间和服务账户对绑定。
Flink 的 UI 可以通过 NGINX ingress 访问,日志被持久化在 Datadog 中。
Karpenter 用于集群节点管理。在引入 Karpenter 之前,必须为我们的多租户集群分配多个节点组,以满足某些复杂的 Flink 部署资源隔离需求,因为这些大型复杂的 Flink 部署的运行状态变化显著地干扰了它们运行的节点组的节点分配。Karpenter 通过引入即时节点的概念,从一开始就分配合适大小的节点,为 Flink 任务提供了更好的装箱,而且由于它直接通过 EC2 Fleet API 调用操作节点,它比当前基于自动扩展的托管节点组+集群自动扩展器有更好、更精细的对机器的控制。
#03
影响和学习
之前我们有一个 8 页的 Flink 管道接入指南,其中有几个手动步骤使过程容易出错,这大大降低了我们开发人员的生产力,并增加了我们的数据平台工程师的支持时间。通过使用 Kubernetes 技术和我们自己开发的 Instacart Flink K8s Operator,我们将 Flink 部署模型(AWS 权限、Kafka 权限、默认 Flink 设置)编码成一个简单的模型。这将新的 Flink 管道接入时间从一周减少到几分钟。
减少了运营成本。通过工具和自动化,如 CI/CD、NGINX 控制器、Lacework、Teleport,我们能够以最小的开发努力显著减少我们的运维、支持和故障排除工作,同时也提供了良好的用户开发体验。总的来说,它为我们节省了大约 50 周的开发工作,减少了 20% 的工程工作在运维和支持上,以及 15% 的开发生产力。
基础设施成本节省。通过利用智能自动扩展机制,以及像节点亲和性这样的能力,我们能够在单个混合节点类型的集群上调度具有不同资源模式的负载。这在生产实例上节省了 50% 以上的基础设施成本,在开发实例上节省了 70%,在 EBS 卷上节省了 40%。
自动故障恢复,即使在流量高峰期也没有任何事故。通过部署 Flink K8s Operator,我们能够实现自动故障恢复,无需人工干预。每年将大约 30 个关键警报减少到 0,这尤其有影响,因为许多这些关键警报都是在夜间发生的。
我们对 Kubernetes 和 Kubernetes 工具所实现的成就感到非常兴奋。
整个 Flink 服务的接入和运维应该简化,不涉及 K8s 的细节。我们平台上大部分用户都不了解 Kubernetes,所以我们应该尽可能地将 K8s 的细节抽象出来。
建立我们的实时系统时,重要的是要有平台思维和统一的技术和工具。短期解决方案与异构技术使平台效率低下,难以扩展和操作。而 Kubernetes 目前是提供这种统一的最突出的解决方案。它提供了一种我们过去需要超过 3 个系统来管理的所有需要的东西的管理方式。Flink 的路线图上 Kubernetes 的支持正在迅速迭代,这是使 Flink 更加云原生的一大步。我们在 2022 年见证了 Flink K8s Operator 的重大演变,启用了大量的新特性。
#04
致谢
特别感谢 Luiz Soares,他是我们的云基础团队的主要工程师,他为在 EKS 上运行的 Flink 平台设置了所有基础设施,并在整个项目中提供了宝贵的建议。还有 Ben Bader,他帮助在 Kubernetes 之上构建了 Flink 开发者体验工具,使得自助服务体验顺畅。向我们的基础设施工程师致敬,他们直接为这个项目做出了贡献:Christopher Cope,Francois Campbell,Greg Lyons,Han Li,Jocelyn De La Rosa,Justin Poole,Peerakit Somsuk,Shen Zhu,Xiaobing Xia。感谢许多其他工程师为的贡献使这个项目能够成功,另外也要感谢 Instacart Cloud 团队和 Build and Deploy 团队的支持!
原文链接:https://tech.instacart.com/building-a-flink-self-serve-platform-on-kubernetes-at-scale-c11ef19aef10