
大规模微服务利器:eBPF 与 Kubernetes

Linux 内核是一切的坚实基础,例如,内核提供了 cgroup、namespace 等特性。
Kubernetes CNI 插件串联起了关键路径(critical path)上的组件。例如,从网络的 视角看,包括:
广义的 Pod 连通性:一个容器创建之后,CNI 插件会给它创建网络设备,移动到容 器的网络命名空间。
IPAM:CNI 向 IPAM 发送请求,为容器分配 IP 地址,然后配置路由。
Kubernetes 的 Service 处理和负载均衡功能。
网络策略的生效(network policy enforcement)。
监控和排障。
容器的部署密度越来越高(increasing Pod density)。
容器的生命周期越来越短(decreasing Pod lifespan)。甚至短到秒级或毫秒级。
https://www.cncf.io/wp-content/uploads/2020/03/CNCF_Survey_Report.pdf
https://www.cncf.io/wp-content/uploads/2020/03/CNCF_Survey_Report.pdf

So I can work with crazy people, that’s not the problem. They just need to sell their crazy stuff to me using non-crazy arguments, and in small and well-defined pieces. When I ask for killer features, I want them to lull me into a safe and cozy world where the stuff they are pushing is actually useful to mainline people first.
In other words, every new crazy feature should be hidden in a nice solid “Trojan Horse” gift: something that looks obviously good at first sight.
Linus Torvalds,
https://lore.kernel.org/lkml/alpine.LFD.2.00.1001251002430.3574@localhost.localdomain/
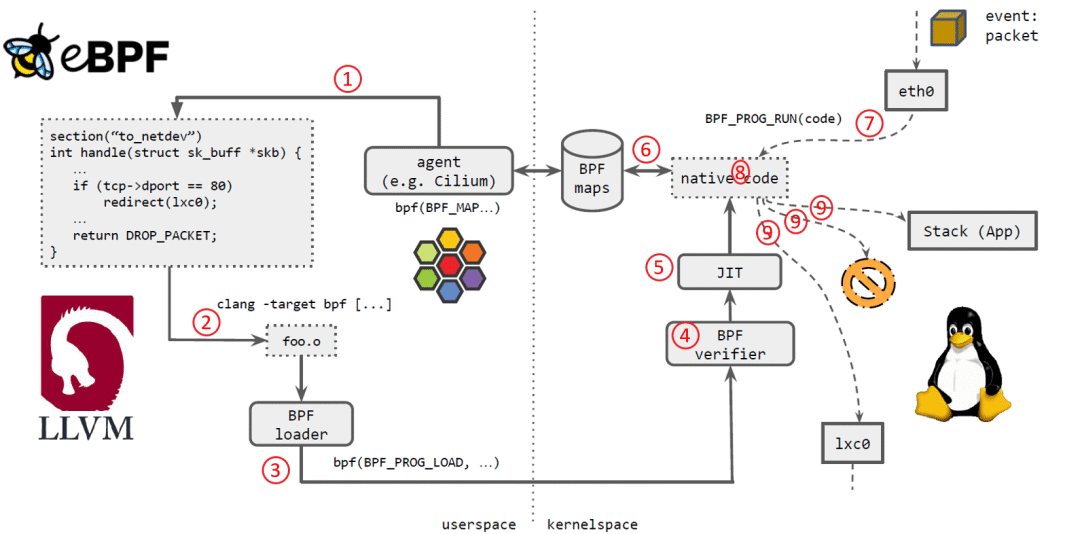
Cilium agent 生成 eBPF 程序。
用 LLVM 编译 eBPF 程序,生成 eBPF 对象文件(object file,*.o)。
用 eBPF loader 将对象文件加载到 Linux 内核。
校验器(verifier)对 eBPF 指令会进行合法性验证,以确保程序是安全的,例如 ,无非法内存访问、不会 crash 内核、不会有无限循环等。
对象文件被即时编译(JIT)为能直接在底层平台(例如 x86)运行的 native code。
如果要在内核和用户态之间共享状态,BPF 程序可以使用 BPF map,这种一种共享存储 ,BPF 侧和用户侧都可以访问。
BPF 程序就绪,等待事件触发其执行。对于这个例子,就是有数据包到达网络设备时,触发 BPF 程序的执行。
BPF 程序对收到的包进行处理,例如 mangle。最后返回一个裁决(verdict)结果。
根据裁决结果,如果是 DROP,这个包将被丢弃;如果是 PASS,包会被送到更网络栈的 更上层继续处理;如果是重定向,就发送给其他设备。
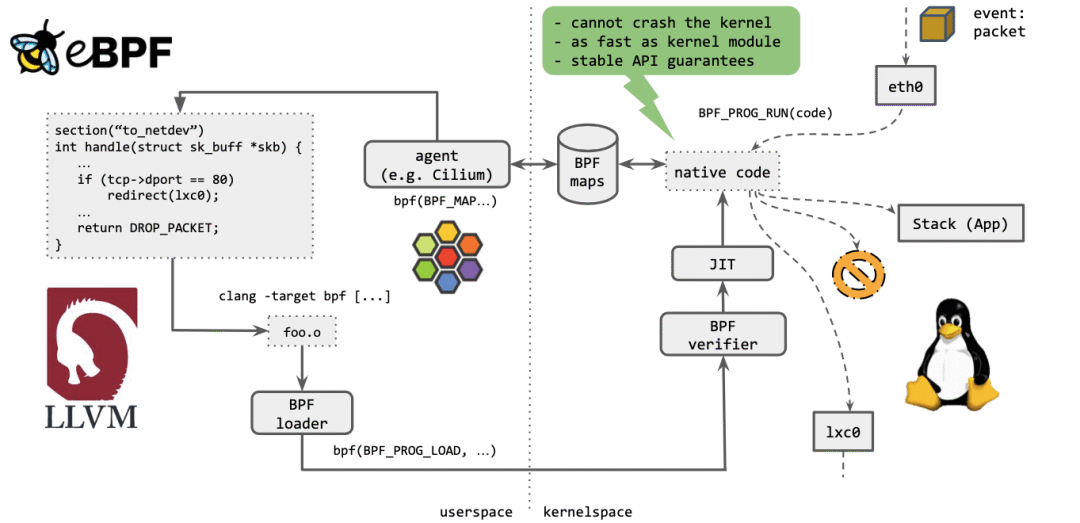
最重要的一点:不能 crash 内核。
执行起来,与内核模块(kernel module)一样快。
提供稳定的 API。
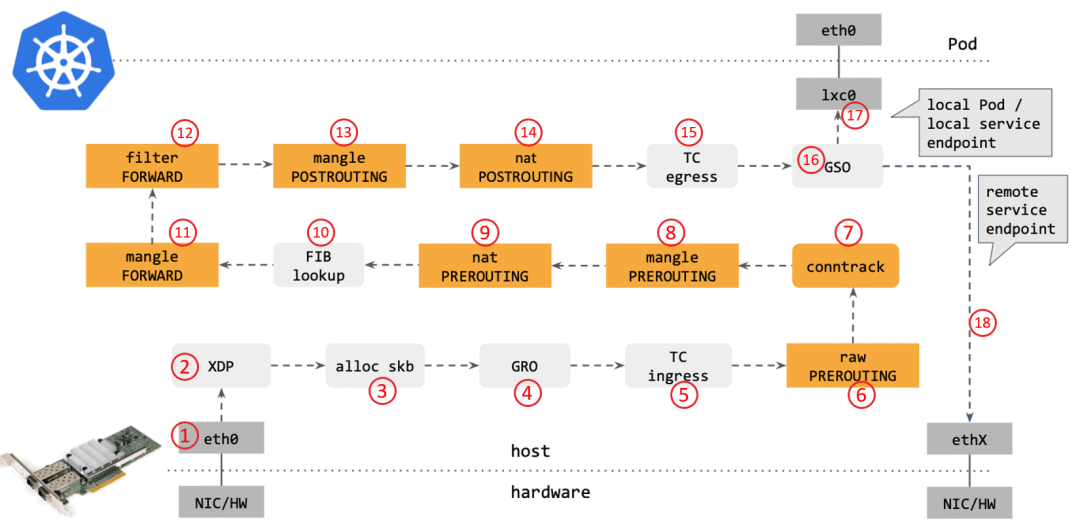
网卡收到一个包(通过 DMA 放到 ring-buffer)。
包经过 XDP hook 点。
内核给包分配内存,此时才有了大家熟悉的 skb(包的内核结构体表示),然后 送到内核协议栈。
包经过 GRO 处理,对分片包进行重组。
包进入 tc(traffic control)的 ingress hook。接下来,所有橙色的框都是 Netfilter 处理点。
Netfilter:在 PREROUTING hook 点处理 raw table 里的 iptables 规则。
包经过内核的连接跟踪(conntrack)模块。
Netfilter:在 PREROUTING hook 点处理 mangle table 的 iptables 规则。
Netfilter:在 PREROUTING hook 点处理 nat table 的 iptables 规则。
进行路由判断(FIB:Forwarding Information Base,路由条目的内核表示,译者注) 。接下来又是四个 Netfilter 处理点。
Netfilter:在 FORWARD hook 点处理 mangle table 里的iptables 规则。
Netfilter:在 FORWARD hook 点处理 filter table 里的iptables 规则。
Netfilter:在 POSTROUTING hook 点处理 mangle table 里的iptables 规则。
Netfilter:在 POSTROUTING hook 点处理 nat table 里的iptables 规则。
包到达 TC egress hook 点,会进行出方向(egress)的判断,例如判断这个包是到本 地设备,还是到主机外。
对大包进行分片。根据 step 15 判断的结果,这个包接下来可能会:发送到一个本机 veth 设备,或者一个本机 service endpoint, 或者,如果目的 IP 是主机外,就通过网卡发出去。


当时有 OpenvSwitch(OVS)、tc(Traffic control),以及内核中的 Netfilter 子系 统(包括 iptables、ipvs、nftalbes 工具),可以用这些工具对 datapath 进行“编程”:。
BPF 当时用于 tcpdump,在内核中尽量前面的位置抓包,它不会 crash 内核;此 外,它还用于 seccomp,对系统调用进行过滤(system call filtering),但当时 使用的非常受限,远不是今天我们已经在用的样子。
此外就是前面提到的 feature creeping 问题,以及 tc 和 netfilter 的代码重复问题,因为这两个子系统是竞争关系。
OVS 当时被认为是内核中最先进的数据平面,但它最大的问题是:与内核中其他网 络模块的集成不好。此外,很多核心的内核开发者也比较抵触 OVS,觉得它很怪。
tc、OVS、netfilter 可以对 datapath 进行“编程”:但前提是 datapath 知道你想做什 么(but only if the datapath knows what you want to do)。
只能利用这些工具或模块提供的既有功能。
eBPF 能够让你创建新的 datapahth(eBPF lets you create the datapath instead)。
描述 eBPF 的 RFC 引起了广泛讨论,但普遍认为侵入性太强了(改动太大)。
另外,当时 nftables (inspired by BPF) 正在上升期,它是一个与 eBPF 有点类似的 BPF 解释器,大家不想同时维护两个解释器。
用一个扩展(extended)指令集逐步、全面替换原来老的 BPF 解释器。
自动新老 BPF 转换:in-kernel translation。
后续 patch 将 eBPF 暴露给 UAPI,并添加了 verifier 代码和 JIT 代码。
更多后续 patch,从核心代码中移除老的 BPF。
networking
tracing
XDP 合并到内核,支持在驱动的 ingress 层 attach BPF 程序。
nfp 最为第一家网卡及驱动,支持将 eBPF 程序 offload 到 cls_bpf & XDP hook 点。
通过 eBPF 实现高效的 label-based policy、NAT64、tunnel mesh、容器连通性。
整个 datapath & forwarding 逻辑全用 eBPF 实现,不再需要 Docker 或 OVS 桥接设备。
Netflix on eBPF for tracing: ‘Linux BPF superpowers’
Facebook 公布了生产环境 XDP+eBPF 使用案例(DDoS & LB)
用 XDP/eBPF 重写了原来基于 IPVS 的 L4LB,性能 10x。
eBPF 经受住了严苛的考验:从 2017 开始,每个进入 facebook.com 的包,都是经过了 XDP & eBPF 处理的。
Cloudflare 将 XDP+BPF 集成到了它们的 DDoS mitigation 产品。
成功将其组件从基于 Netfilter 迁移到基于 eBPF。
到 2018 年,它们的 XDP L4LB 完全接管生产环境。
扩展阅读:http://arthurchiao.art/blog/cloudflare-arch-and-bpf-zh/
eBPF patch 合并到 bpf & bpf-next kernel trees on git.kernel.org
拆分 eBPF 邮件列表:bpf@vger.kernel.org (archive at: lore.kernel.org/bpf/)
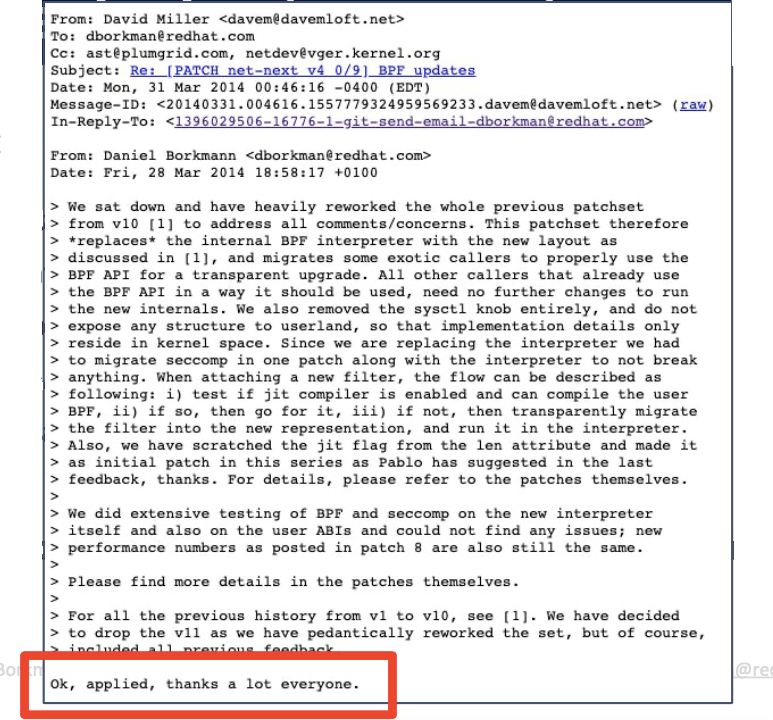
eBPF PR 经内核网络部分的 maintainer David S. Miller 提交给 Linus Torvalds
Kubernetes CNI
Identity-based L3-L7 policy
ClusterIP Services
DPDK 需要重写网卡驱动,需要额外维护用户空间的驱动代码。
AF_XDP 在复用内核网卡驱动的情况下,能达到与 DPDK 一样的性能。
Google 贡献了 BPF LSM(安全),部署在了他们的数据中心服务器上。
BPF verifier 防护 Spectre 漏洞(2018 年轰动世界的 CPU bug):even verifying safety on speculative program paths。
主流云厂商开始通过 SRIOV 支持 XDP:AWS(ena driver),Azure(hv_netvsc driver)……
Cilium 1.8 支持基于 XDP 的 Service 负载均衡和 host network policies。
Facebook 开发了基于 BPF 的 TCP 拥塞控制模块。
Microsoft 基于 BPF 重写了将他们的 Windows monitoring 工具。

347 个贡献者,贡献了 4,935 个 patch 到 BPF 子系统。
BPF 内核邮件列表日均 50 封邮件(高峰经常超过日均 100)。
23,395 mails since mailing list git archive was added in Feb 2019
每天合并 4 个新 patch。patch 接受率 30% 左右。
30 个程序(different program),27 种 BPF map 类型,141 个 BPF helpers,超过 3,500 个测试。
2 个 BPF kernel maintainers & team of 6 senior core reviewers。
主要贡献来自:Isovalent(Cilium),Facebook and Google
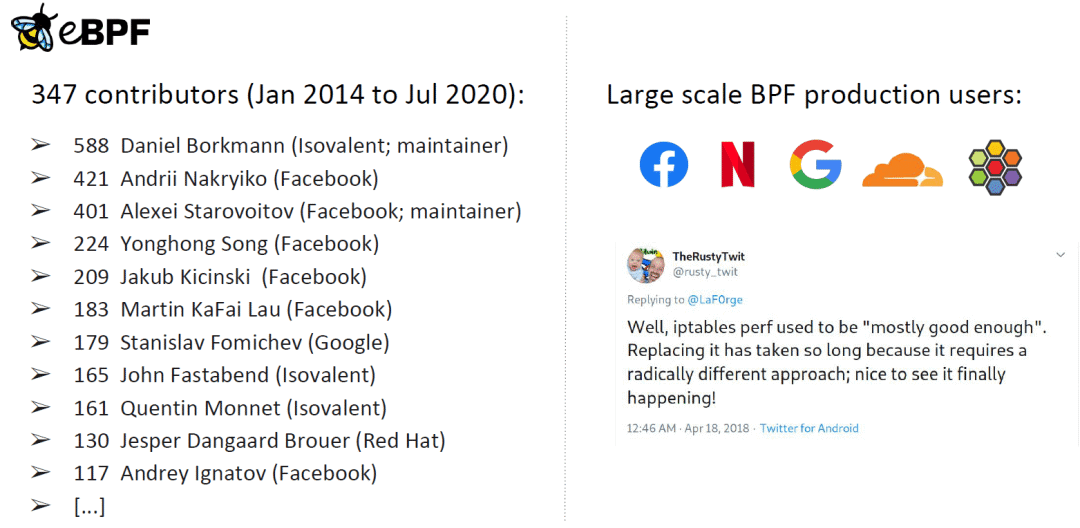
Facebook:L4LB、DDoS、tracing。
Netflix:BPF 重度用户,例如生产环境 tracing。
Google:Android、服务器安全以及其他很多方面。
Cloudflare:L4LB、DDoS。
Cilium
$ kubectl -n kube-system delete ds kube-proxy
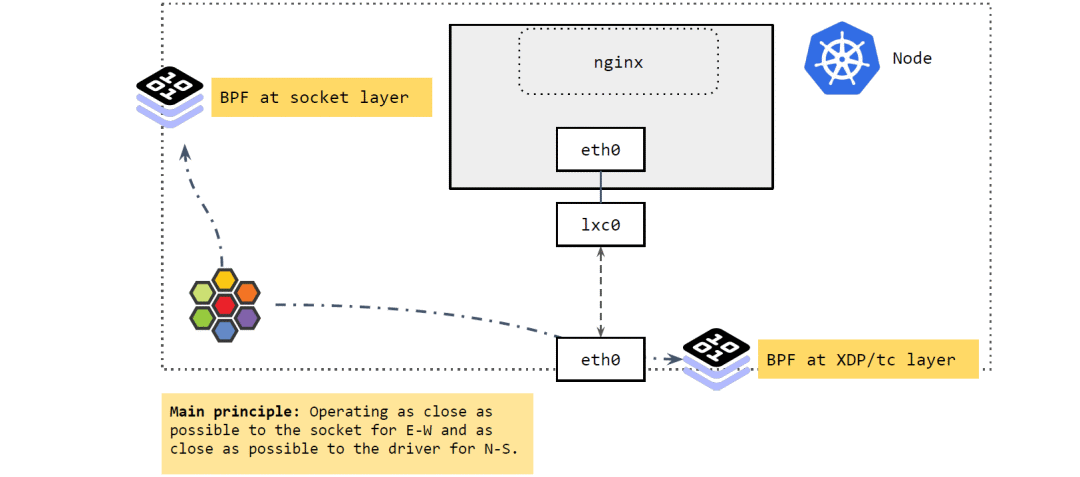
在 socket 层运行的 BPF 程序
在 XDP 和 tc 层运行的 BPF 程序
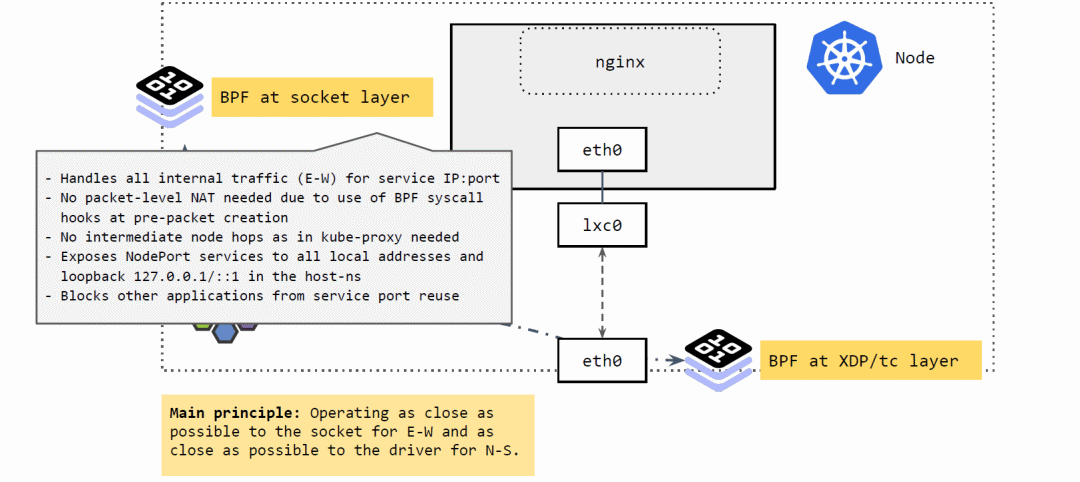
将 Service 的 IP:Port 映射到具体的 backend pods,并做负载均衡。
当应用发起 connect、sendmsg、recvmsg 等请求(系统调用)时,拦截这些请求, 并根据请求的IP:Port 映射到后端 pod,直接发送过去。反向进行相反的变换。
不需要包级别(packet leve)的地址转换(NAT)。在系统调用时,还没有创建包,因此性能更高。
省去了 kube-proxy 路径中的很多中间节点(intermediate node hops) 可以看出,应用对这种拦截和重定向是无感知的(符合 Kubernetes Service 的设计)。
因此,如果 Pod 流量直接从 node 出宿主机,必须确保它能正常回来。而 node IP 一般都是全局可达的,集群外也可以访问,所以常见的解决方案就是:在 Pod 通过 node 出集群时,对其进行 SNAT,将源 IP 地址换成 node IP 地址;应答包回来时,再进行相 反的 DNAT,这样包就能回到 Pod 了。

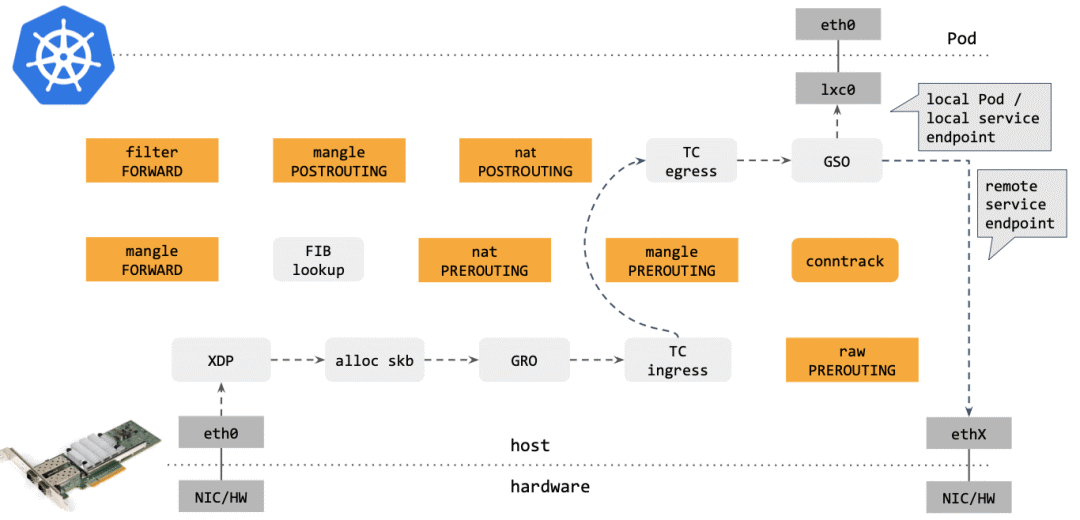
将东西向流量放在离 socket 层尽量近的地方做。
将南北向流量放在离驱动(XDP 和 tc)层尽量近的地方做。
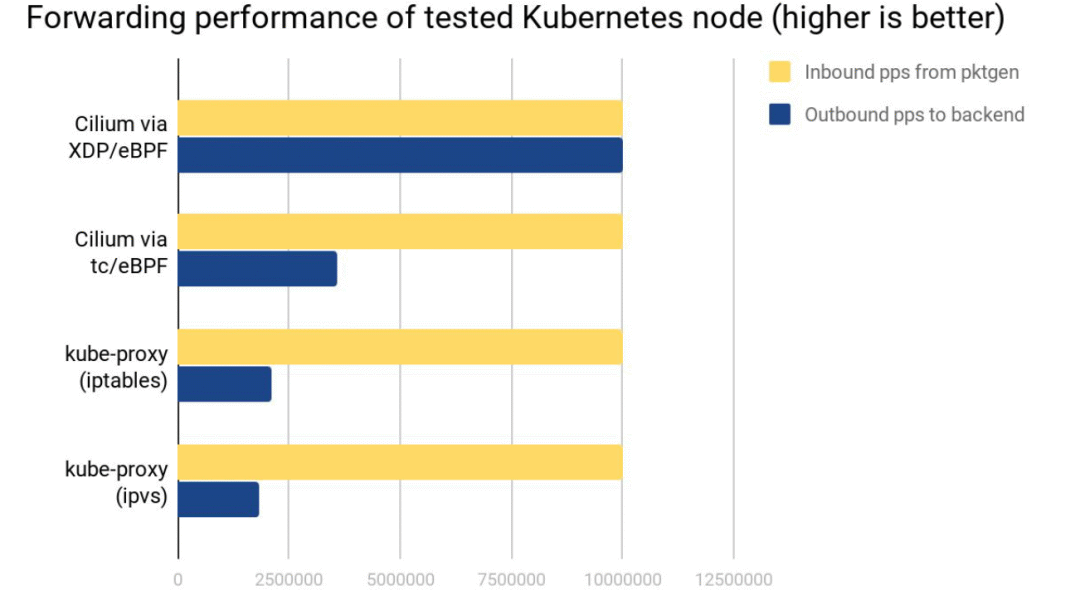
Cilium XDP eBPF 模式能处理接收到的全部 10Mpps(packets per second)。
Cilium tc eBPF 模式能处理 3.5Mpps。
kube-proxy iptables 只能处理 2.3Mpps,因为它的 hook 点在收发包路径上更后面的位置。
kube-proxy ipvs 模式这里表现更差,它相比 iptables 的优势要在 backend 数量很多的时候才能体现出来。
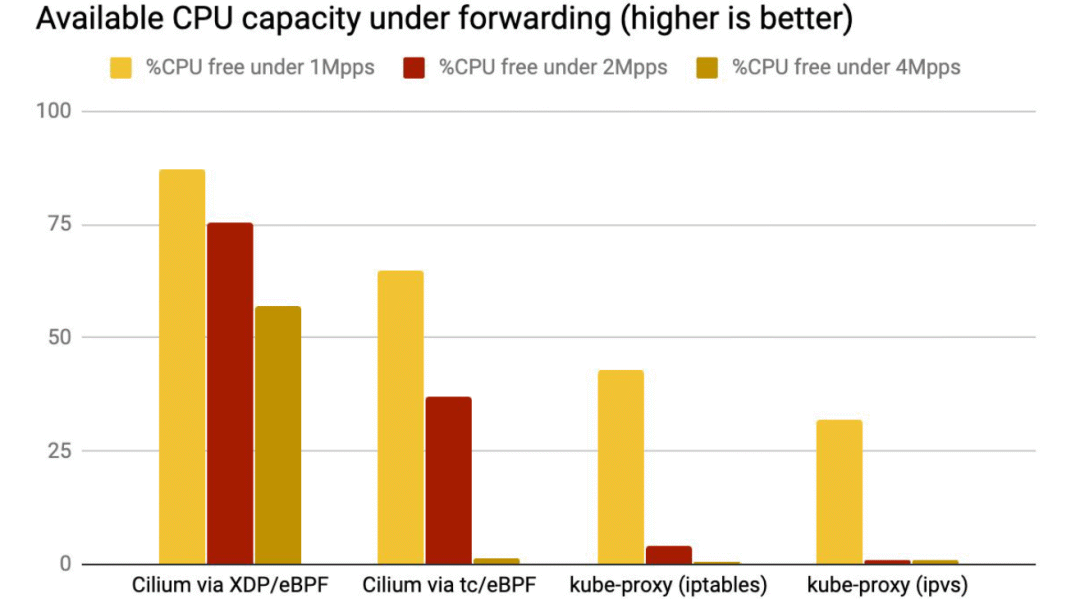
XDP 性能最好,是因为 XDP BPF 在驱动层执行,不需要将包 push 到内核协议栈。
kube-proxy 不管是 iptables 还是 ipvs 模式,都在处理软中断(softirq)上消耗了大量 CPU。
设想在将来,Linux 只会保留一个非常小的核心内核(tiny core kernel),其他所有 内核功能都由用户定义,并用 BPF 实现(而不再是开发内核模块的方式)。
这样可以减少受攻击面,因为此时的核心内核非常小;另外,所有 BPF 代码都会经过 verifer 校验。
极大减少 ‘static’ feature creep,资源(例如 CPU)可以用在更有意义的地方。
设想一下,未来 Kubernetes 可能会内置 custom BPF-tailored extensions,能根据用户的应用自动适配(optimize needs for user workloads);例如,判断 pod 是跑在数据中心,还是在嵌入式系统上。


- END -
推荐阅读 31天拿下K8s含金量最高的CKA+CKS证书! 运维工程师不得不看的经验教训和注意事项 Kubernetes 的这些核心资源原理,你一定要了解 终于搞懂了服务器为啥产生大量的TIME_WAIT! Kubernetes 网络方案之炫酷的 Cilium Prometheus+InfluxDB+Grafana 打造高逼格监控平台 民生银行 IT运维故障管理 可视化案例 这些 K8S 日常故障处理集锦,运维请收藏~ Linux 这些工具堪称神器! 猪八戒网 CI/CD 最佳实践之路 从零开始搭建创业公司DevOps技术栈 12年资深运维老司机的成长感悟 搭建一套完整的企业级 K8s 集群(kubeadm方式)
点亮,服务器三年不宕机

