
Data Fabric,下一个风口?

导读:Data Fabric,又名数据经纬,是近期横空出世的一个概念。之前对其了解甚少,近期做了个小调研,对这一概念内涵与外延、产品及定位、业务与前景、未来及趋势等做了简单整理总结,分享给大家。



激增的暗数据&数据孤岛
低效的数据交付方式
日益严峻的数据质量问题
不断扩大的安全合规风险
在过去的十年里,数据和应用孤岛的数量激增,而数据和分析(D&A)团队的技能型人才数量却保持不变,甚至下降。作为一种跨平台和业务用户的灵活、弹性数据整合方式,Data Fabric能够简化企业机构的数据整合基础设施并创建一个可扩展架构,减少大多数数据和分析团队因整合难度上升而出现的技术债务。 其真正价值在于:通过内置的分析技术动态改进数据的使用,使数据管理工作量减少70%并加快价值实现时间。 Gartner最新预测显示,至2024年,Data Fabric可减少50%人力数据管理成本,与此同时,数据使用效率会因Data Fabric的部署使用伴随着数据类型日益多样化、数据孤岛不断林立、数据结构愈加复杂,企业在分布式数据环境中高效管理和利用多维数据成为亟待解决的难题。 与此同时,企业上云成为一大趋势,混合数据环境下企业该如何跨平台、跨环境,以实时的速度收集、访问、管理、共享数据,从不断变化、高度关联、却又四处分散的数据中获得可执行洞见,实现智能化决策?面对上述数据管理难题,Data Fabric提出了一套治理“良方”。 Data Fabric是一种新兴的数据集成和管理理念,意在独立于部署平台、数据流程、地理位置和架构方法,在不移动数据位置的前提下,为企业内的所有数据提供单一访问点,保证数据使用端在正确的时间、正确的地点以实时的速度拿到正确的数据。
连接数据,而非集中数据
自助服务,而非专家服务
主动智能,而非被动人工
万物链接,而非简单替代
5. 关联对比

API 的访问方式不同。Data Mesh是面向开发同学、API驱动的解决方案,需要为API编写实现代码,而Data Fabric相反,其通过低代码、无代码的方式进行设计,API集成在架构内进行实现,而不是直接使用它。 思想不同。虽然Data Fabric和Data Mesh 都提供了跨技术、跨平台的使用数据的架构,但前者以技术为中心,是将多种技术进行组合使用,由 AI/ML 驱动的增强和自动化、智能元数据基础和强大的技术骨干(即云原生、基于微服务、API 驱动、可互操作和弹性)支持,更多的是关于管理数据技术(集成架构),而后者则侧重于组织结构和文化变革来实现敏捷性,可以在于技术无关的框架内指导方案设计,各数据领域团队可以在更理解其所管理的数据的基础下实现相应的数据产品的交付,更多的是管理人员和流程。 数据产品的实现思路不同。Data Mesh 将数据的产品思维作为核心设计原则,其数据是分布式的,每类数据都是一个独立的域(即数据产品),存储在对应的组织中,而Data Fabric所有的数据都会集中在一个位置(物理集中或虚拟集中),对外提供能力。其实,基于数据虚拟化集成技术的Data Fabric,其数据也是分布式的,通过虚拟逻辑数据模型对外统一提供数据使用。 数据资产的自动化方式不同。Data Fabric利用基于丰富的企业元数据基础(例如知识图)来发现、连接、识别、建议和向数据消费者提供数据资产的自动化,而Data Mesh则依赖于数据产品/域所有者来推动数据需求。 依赖关系不同。Data Fabric无需依赖Data Mesh的实践即可实施,而Data Mesh则必须利用Data Fabric来支持数据对象和产品的验证。 自动化程度不同。Data Fabric鼓励增强数据管理和跨平台编排,以最大限度地减少人工设计、部署和维护工作。Data Mesh则倾向于对现有系统的手动设计和编排,由业务领域执行持续维护。 解决方案的成熟度不同。成熟度上看,Data Fabric目前被广泛应用于各种数据应用场景,而Data Mesh仍然处在一个未开发的阶段。
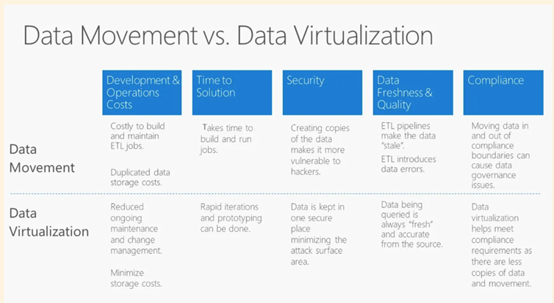
数据虚拟化技术
数据集成
更快地适应业务
更好的洞察力
更有效地消除孤岛
更低的成本和实施风险
更高效的业务协作
更安全的业务
1)Forrester 定义的能力要求
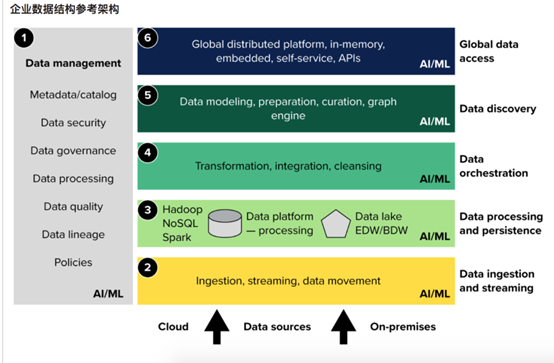
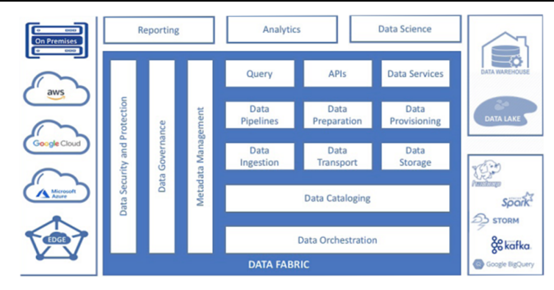
数据管理
数据摄取和流式传输
数据处理和持久化
数据编排
数据发现
数据访问
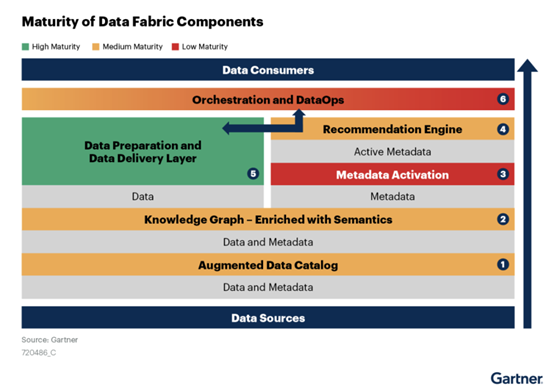
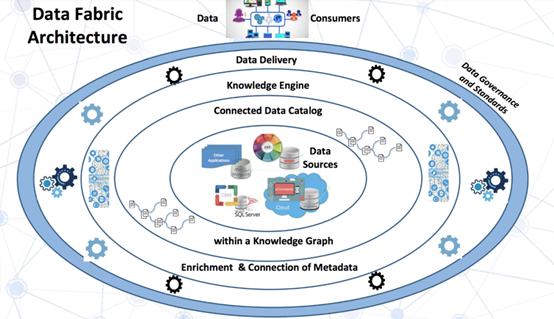
增强数据目录
语义知识图谱
主动元数据
推荐引擎
数据准备和数据交付
数据编排和DataOps
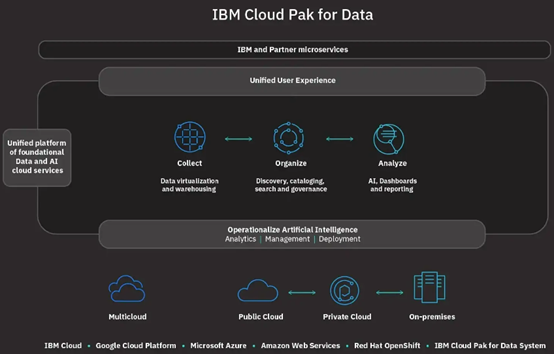
AutoCatalog:元数据的管理是挖掘数据价值,把各个不同来源的数据很好利用起来的重要技术环节。AutoCatalog 可以看成是 IBM 研发 AI 赋能的分类大脑,可以根据发现数据和分类的流程实现自动化,进行自动分类之后建立自动化目录,维护来自不同数据环境数据资产的 Dynamic 的实时目录。 AutoAI:AutoAI 的主要功能是尽量降低 AI 模型开发、模型校正、模型自我重新培训的技术门槛和人力付出,从而对动态的数据和整个 AI 本身算法生命的周期进行自动化。 AutoPrivacy:实际上 AutoPrivacy 主要是通过数据隐私框架当中的关键能力,使用 AI 的能力智能化地识别企业内部的敏感数据,当被调用的时候系统能够识别到、监控到,甚至在后续当定义敏感数据的使用和保护时,就可以为企业内部的政策实施自动化提供了技术和智能化的保障。 AutoSQL:因为我们现在要解决的问题是跨混合多云环境实现数据访问的自动化,当写一个传统 SQL 的时候,首先要知道这个数据在什么地方。我们通过 AutoSQL 的技术来实现访问数据的自动化,无须物理地移动这些数据,从而提高了数据查询的速度,也降低了使用数据的人对数据来源所需要的了解。
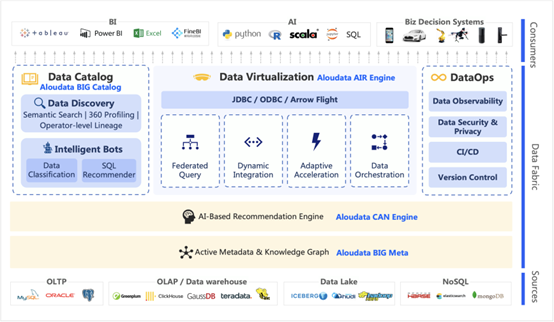
主动元数据
推荐引擎
增强数据目录
数据虚拟化
DataOps

数据接入的融合:基于成熟开源组件,稳定可靠,兼容MySQL协议和技术生态体系 数据存储的融合:可实现数据多副本、水平弹性伸缩、数据一致性、透明高可用、分层解耦融合 数据引擎融合:多引擎融合解决数据多样性存储的横向打通 数据接入的扩展:支持信息系统结构化数据、工业物联网时序数据、科学引擎接口数据的可扩展接入 数据输出的扩展:数据服务化要作为数据库的标准能力 数据引擎的扩展:针对数据类型与计算需求可扩展至 在线事务处理、在线分析处理、时序数据处理、全文检索、知识库等多种引擎

延伸阅读👇

延伸阅读《数据库高效优化》
作者:马立和 高振娇 韩锋
推荐语:本书以大量案例为依托,系统讲解了SQL语句优化的原理、方法及技术要点,尤为注重实践,在章节中引入了大量的案例,便于学习者实践、测试,反复揣摩。
评论