
有赞移动性能监控平台(二)
一、前言
性能和稳定性一直是App质量体系中最基本和最关键的一环。 而移动端业务快速迭代的过程中,开发同学对性能的关注不足,量变引起质变,App的卡顿严重影响商家的日常经营,商家对性能的吐槽和抱怨越来越严重。而面对商家反馈的性能问题,由于缺乏现场信息,问题的排查既被动又困难。我们急需一个系统化的解决方案,需要有自己的APM(Application Performance Management),可以通过它来发现问题,并且能依靠它的数据来指导我们进行性能优化。
二、整体设计
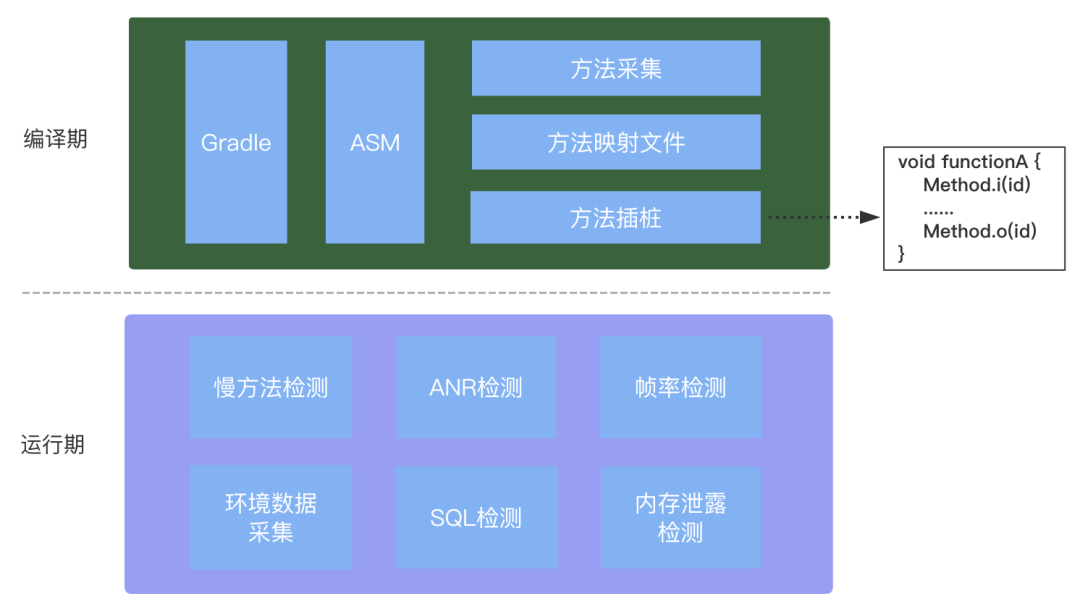
系统主要分为两个部分:
移动端上的「性能检测」,主要负责数据的采集。
后端的「数据处理」,主要包含数据的清洗、解析、存储、报警等。
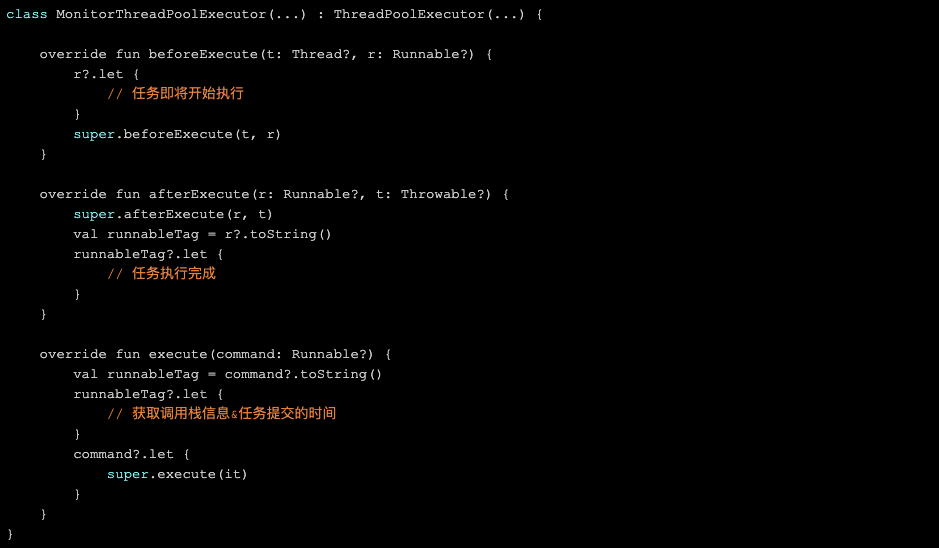 检测的核心在于监听线程池的三个节点:
检测的核心在于监听线程池的三个节点:任务提交到线程池。拉取每个任务的调用栈信息,解析并记录任务的发起点以及任务的提交时间。同时可以分析此时线程池的负载状况(结合activeCount、corePoolSize、queueSize),如果负载达到阈值,则拉取出当前所有的任务,分析是否存在明显有问题的任务(比如同一任务发起多次等)。
任务开始执行。记录任务开始执行的时间。
任务执行完成。与任务开始时间做差值,计算并记录任务的执行时间,如果任务的执行时间超出阈值,则会进行上报。
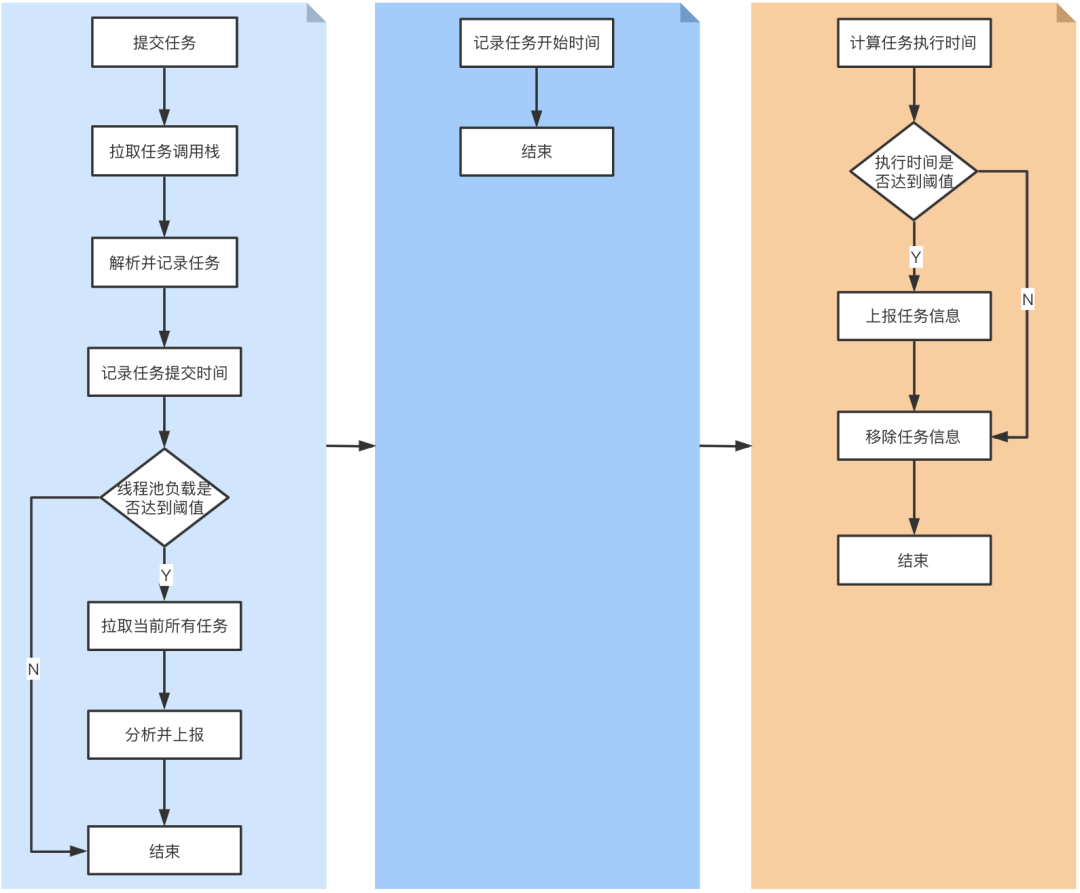 通过上面的方式能逐步分离出「耗时长」、「频率高」的任务,通过对这些任务的优化,最终达到线程池优化的目标。另外由于有了完整的线程池负载情况跟踪以及任务执行时间数据,我们对线程池的健康度也有了可度量的指标,这也为我们做线程池的自动化配置提供了参考依据。
通过上面的方式能逐步分离出「耗时长」、「频率高」的任务,通过对这些任务的优化,最终达到线程池优化的目标。另外由于有了完整的线程池负载情况跟踪以及任务执行时间数据,我们对线程池的健康度也有了可度量的指标,这也为我们做线程池的自动化配置提供了参考依据。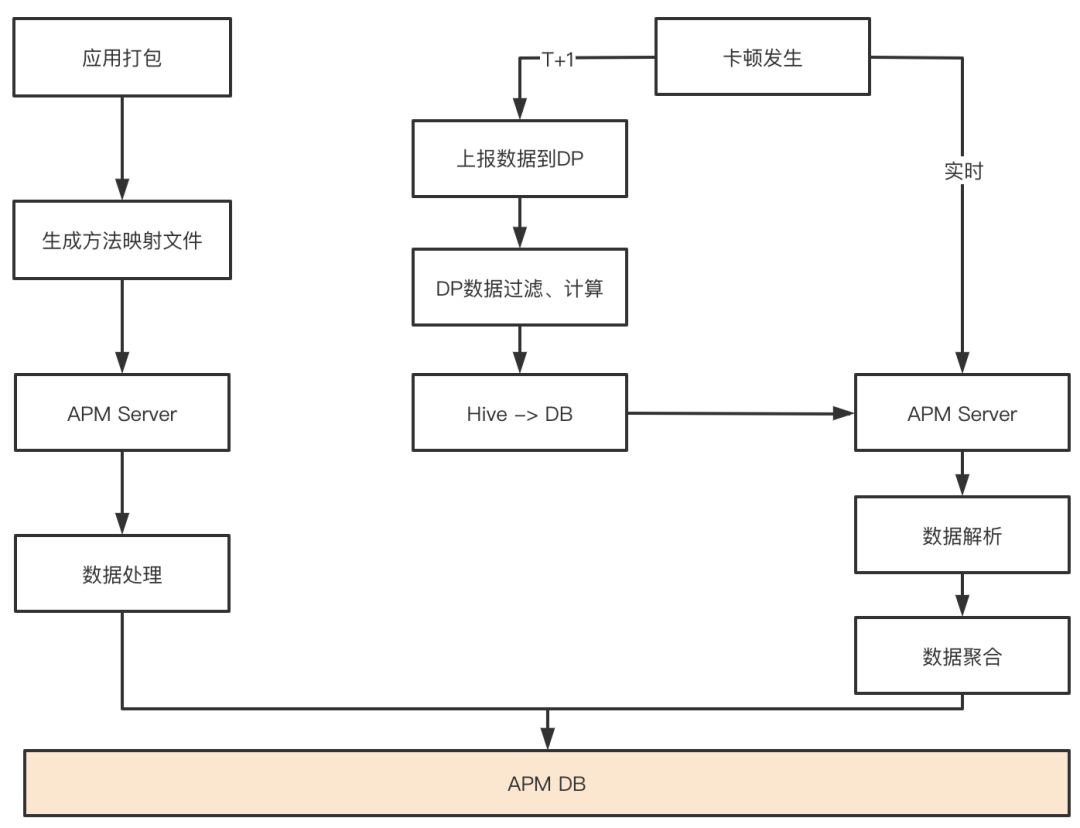
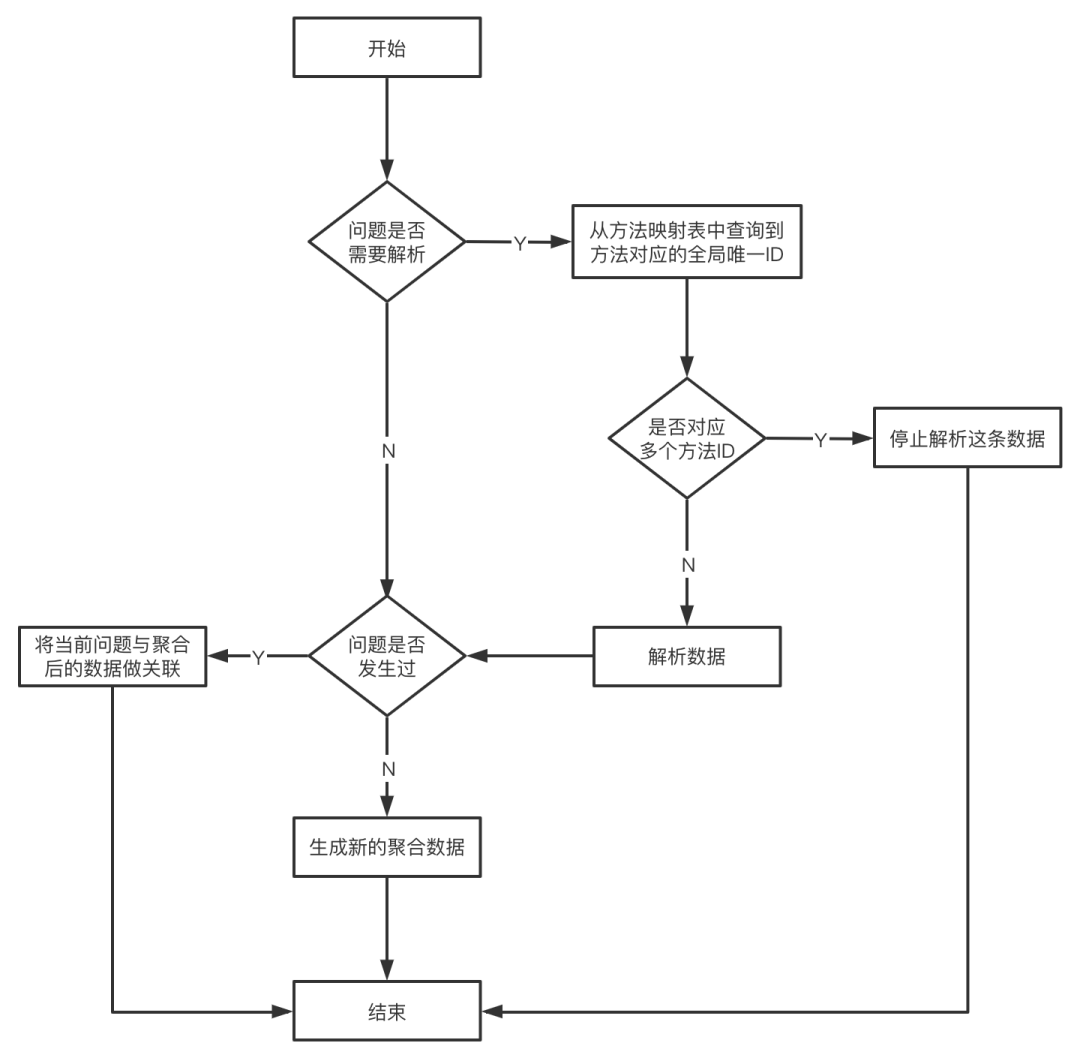 (2)数据清理流程
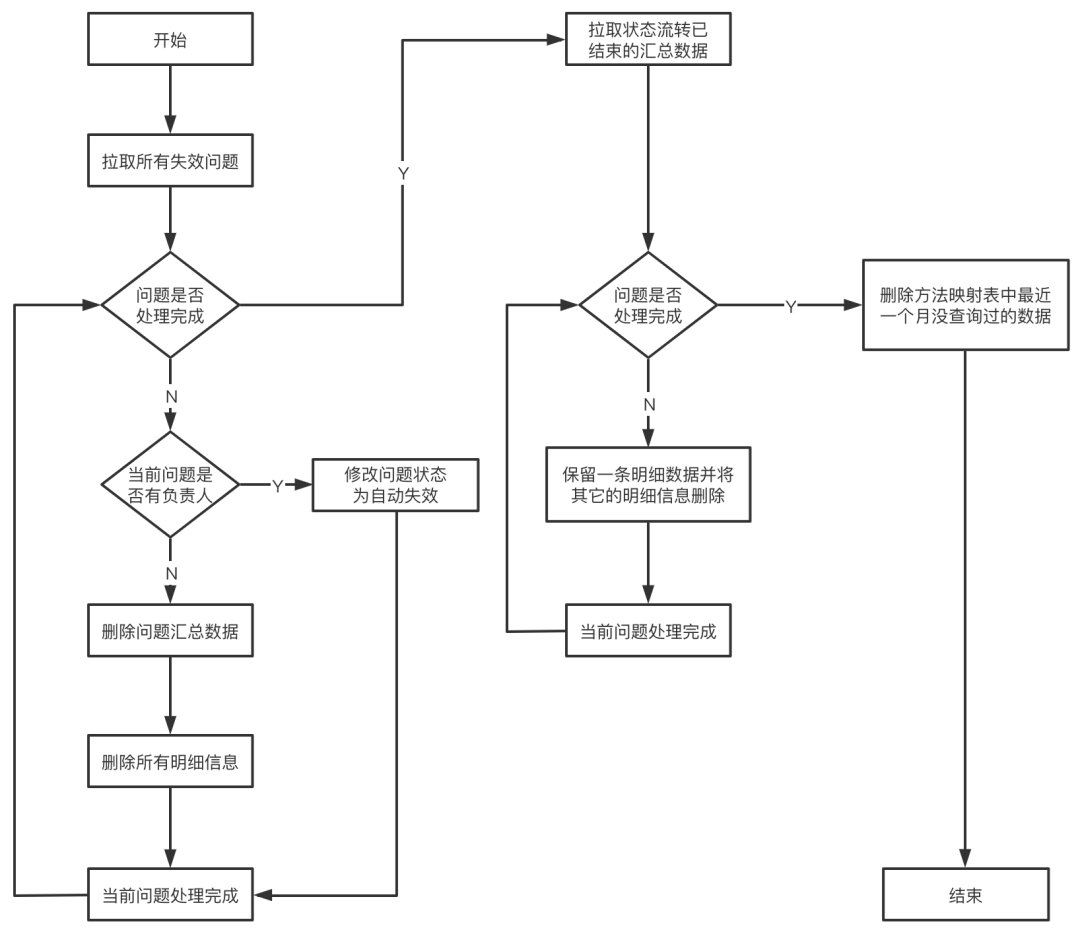
(2)数据清理流程未分配的问题且最近一个月问题不再出现,则这个问题大概率以后不会再发生了,针对这种问题我们会直接清除问题的所有信息,不会再跟踪这个问题。
已分配但未标记解决的问题且最近一个月问题不再出现,这种问题一般是问题已经修复但是没有及时修改状态,我们会把问题的状态修改为自动失效。
状态流转已结束的问题(包括已处理、已忽略、自动失效的问题),我们会保留最新的一条明细数据进行存档,剩余的明细数据会全部清除。
方法映射表中会存储过往所有版本的所有方法信息,然而其中绝大多数方法其实是没问题的(比如简单的a+b),所以这里我们会对最近一个月解析时没有访问的方法进行清除(解析时没访问的方法意味着这个方法没发生卡顿问题)。
同一个版本可能会上传多次方法映射表信息,而真正发布的只会有一个,因此我们会去发版平台获取某个版本正在发布的信息,然后把没有正常发布的方法映射表数据删除。
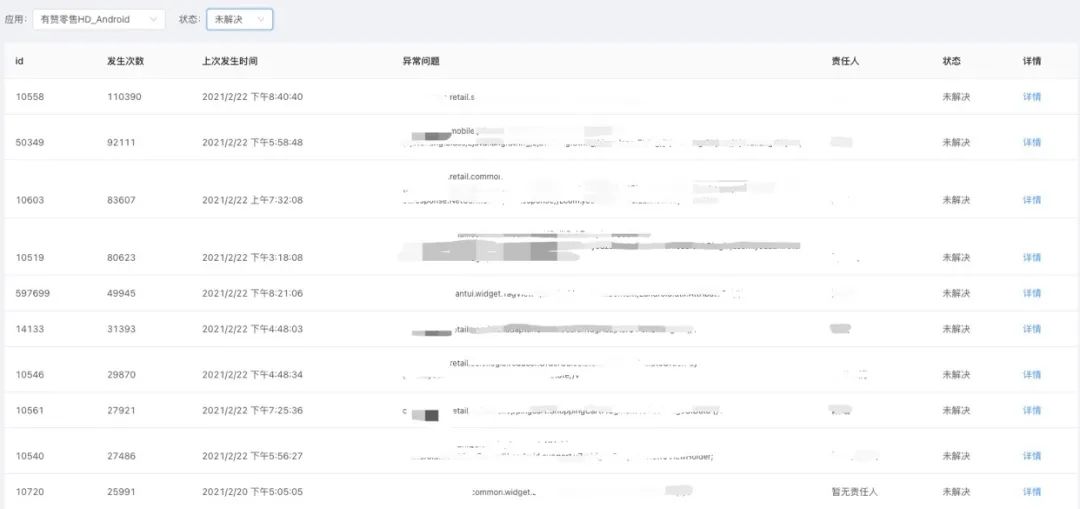
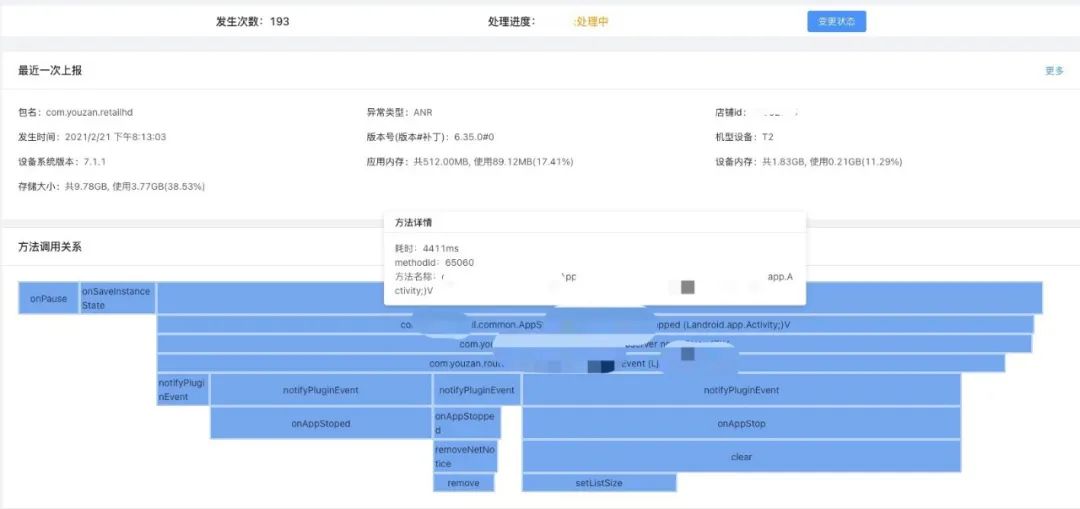
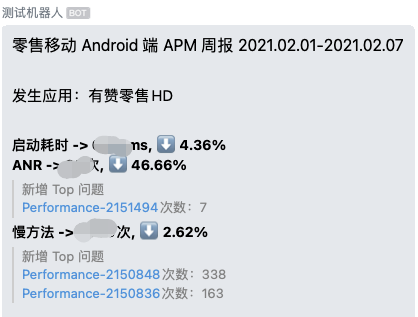
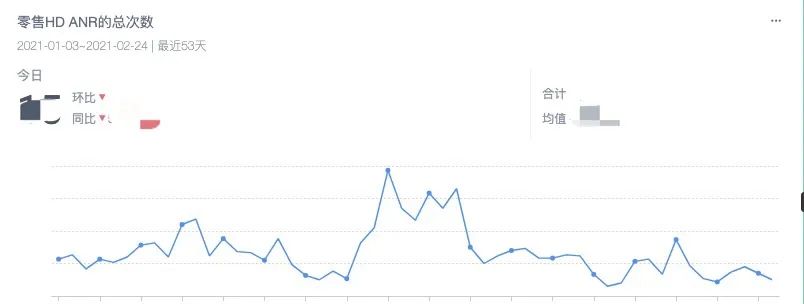 3.3.2 慢方法变化趋势
3.3.2 慢方法变化趋势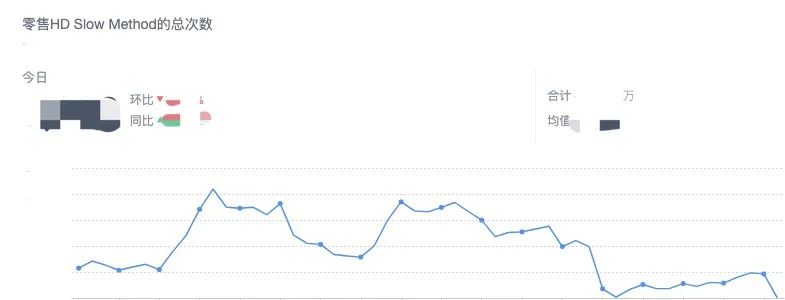 3.3.3 FPS变化趋势
3.3.3 FPS变化趋势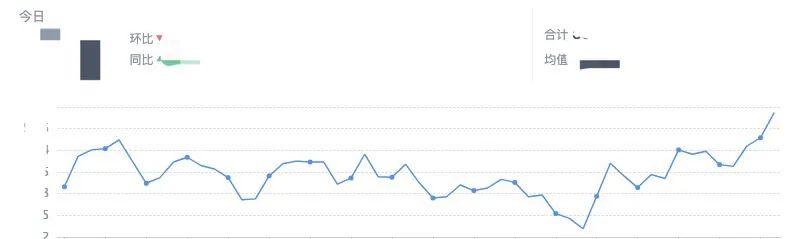
完善性能监控体系,补足网络、I/O、线程池、磁盘等方面的监控,通过性能监控的数据指导性能优化。
更多维度的数据筛选和过滤能力,能够更好的对指定设备或门店进行问题跟踪。
更强的数据处理能力,能够更快速地处理更庞大的数据量。
完善系统使用体验,如:报表呈现、问题分配机制、问题报警等。
推广到公司其它的业务线,帮助解决端上性能监控问题。
对App线上真实的性能情况有了数据化的指标,让我们对性能问题有了更清晰的感受。
通过监控的数据指导我们进行性能优化,优化效果也能有数据化的支撑。
通过监控的数据能让我们更快速的发现新引入的性能问题,防止性能不断劣化,为App的稳定运行提供保障。
推动各业务团队进行性能优化,让大家能更加重视自己产品的性能问题。