
Jmeter+Grafana+Chronograf+InfluxDB性能测试监控平台
依赖的软件版本:
influxdb-1.3.0.x86_64.rpm
chronograf-1.4.4.1.x86_64.rpm
grafana-6.2.1-1.x86_64.rpm
一、安装InfluxDB
安装完毕后,修改InfluxDB的配置:
配置jmeter存储的数据库与端口号
vi /etc/influxdb/influxdb.conf在graphite配置项下修改库与端口
enabled = true database = "jmeter" bind-address = ":2003" protocol = "tcp" consistency-level = "one"启动InfluxDB
/etc/init.d/influxdb restart二、InfluxDB数据库配置
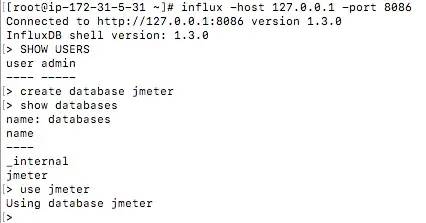
1、登录数据库
influx -host 127.0.0.1 -port 8086
2、数据库管理
# 创建数据库create database # 查询所有数据库> show databases# 使用某个数据库> use 创建一个名为jmeter的数据库
3、表管理
# SHOW measurements命令查看所有的表,这个类似于mysql下的 show tables;SHOW MEASUREMENTS;# 创建表,直接在插入数据的时候指定表名INSERT ,host=server1,region=cn_east-1 value=0.68 # 删除表DROP MEASUREMENT三、配置InfluxDB web管理
InfluxDB 1.3以及之后的版本已经取消在InfluxDB中启用web管理了,取而代之的是使用Chronograf。
安装Chronograf 组件:
wget https://dl.influxdata.com/chronograf/releases/chronograf-1.4.4.1.x86_64.rpmsudo yum localinstall chronograf-1.4.4.1.x86_64.rpm启动web服务:
sudo systemctl start chronograf
然后通过http://localhost:8888连接Web页面:
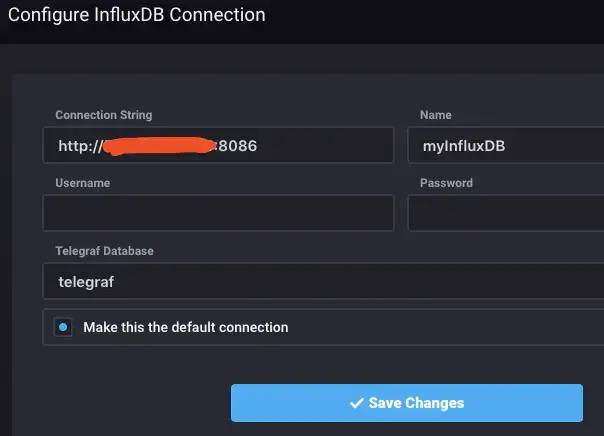
接下来的步骤将Chronograf连接到您的InfluxDB实例
对于Connection String,输入运行InfluxDB的机器的主机名或IP,并确保包含InfluxDB的默认端口:8086。
接下来,命名连接字符串,这可以输入任何值。
最后三个输入框无需编辑。
Username并且Password可以保持空白,Telegraf的默认数据库名称为telegraf。
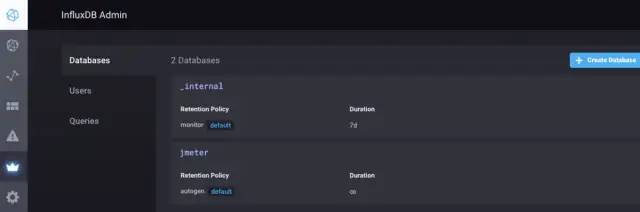
保存成功以后,可以在influxdb Admin看到数据库管理界面,在这里可以看到刚刚新建的jmeter数据库
四、安装Grafana
根据官网指引下载安装Grafana
wget https://dl.grafana.com/oss/release/grafana-6.2.1-1.x86_64.rpmsudo yum localinstall grafana-6.2.1-1.x86_64.rpm启动
Grafana /etc/init.d/grafana-server restart打开浏览器,访问 http://localhost:3000
输入用户名和密码登录系统,用户名与密码都是admin
第一次登录成功以后会让你重置密码。
添加需要展示数据的数据库,这里我们配置Influxdb,
配置Influxdb URL
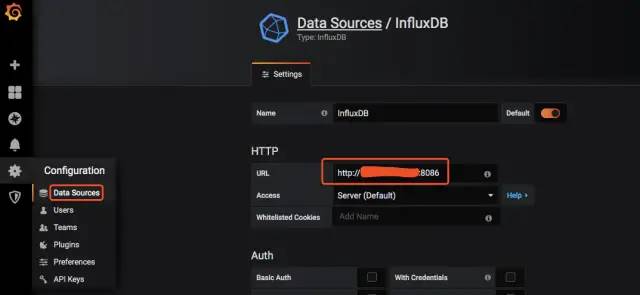
配置Influxdb 数据库,用户名和密码

五、配置Jmeter
jmeter中,添加【监听器 -> Backend Listener】,选择监听类型并配置graphiteHost
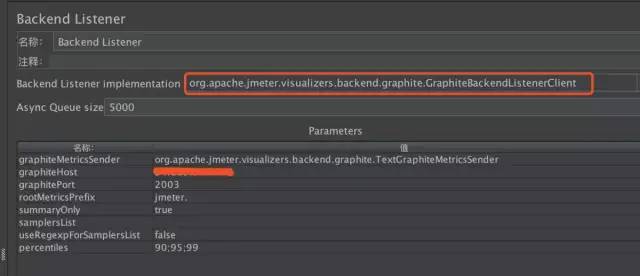
默认情况下,JMeter发送在samplerName“all”下累计的所有采样器的指标。如果配置了 BackendListenerSamplersList,那么JMeter还会发送匹配样本名称的指标,前提是配置 summaryOnly=true
配置完毕后,发送接口请求,可以多发几次,
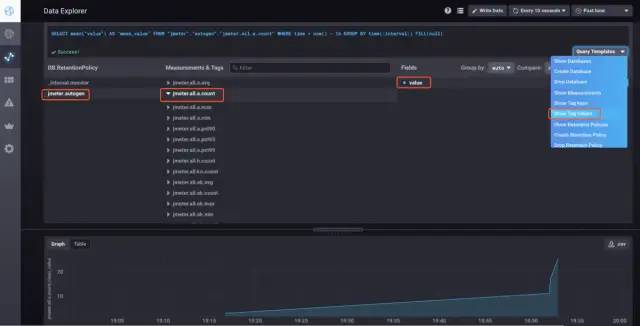
然后进入到chronograf的Data Explorer页面,在【Query Templates】下拉框中选择{Show Tag Value},然后依次选择jmeter数据库和任意一张指标表,会发现在上方到输入框里自动生产类似sql一样的语句,按下回车,就会在底部的图表模块生成数据,
这样表明Jmeter到InfluxDB配置正确。
如果想要监控某个或某几个指定请求的话,Jmeter上的“Backend Listener”修改如下参数:将“summanyOnly”修改成False,将“userRegexpForSamplersList”修改成True,并且要设置“samplersList”的值,“samplersList”是可以支持正则表达式的,“samplersList”的设置要与请求对应,否则找不到该请求。
如图:

端口说明:
8086端口,Grafana用来从数据库取数据的端口
2003端口,JMeter往数据库发数据的端口
如果想要了解这些监控都代表什么意思,可以访问Jmeter的官网地址去查看阅读。
六、配置Grafana
1、点击左侧+号,选择Dashboard

2、在New Panel下选择【Add Query】

3、选择数据库类型和任意指标表名
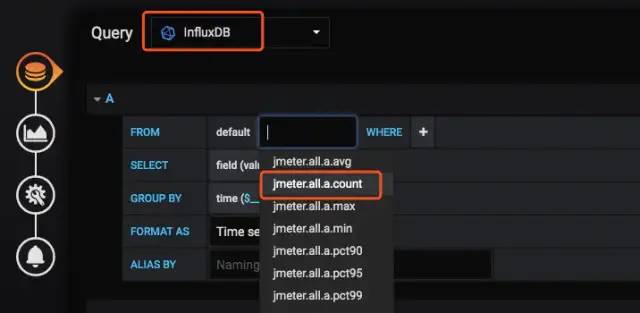
最后生成图表如下:

线程数/用户相关指标
test.minAT-Min active threads:最小活跃线程数
test.maxAT-Max active threads:最大活跃线程数
test.meanAT-Mean active threads:活跃线程数
test.startedT-Started threads:启动线程数
test.endedT-Finished threads:结束线程数
响应时间指标
ok.count:采样器的成功响应数
h.count:每秒点击数
ok.min:采样器成功最短响应时间
ok.max:采样器成功最长响应时间
ok.avg:采样器成功平均响应时间
ok.pct:采样器成功响应百分比
ko.count:采样器失败响应数
ko.min:采样器失败的响应最短时间
ko.max:采样称失败最长响应时间
ko.avg:采样器失败平均响应时间
ko.pct:采样器失败响应百分比
a.count:采样器响应数(ok.count和ko.count的总和)
a.min:采样器最小响应时间(ok.count和ko.count的最小值)
a.max:采样器最大响应时间(ok.count和ko.count的最大值)
a.avg:采样器平均响应时间(ok.count和ko.count的平均值)
a.pct:采样器响应百分比(根据和失败样本的总数计算)
七、Grafana导入Dashboard模版
Grafana官网提供丰富的模版的库,进行二次扩展。
搜索看板模版:

1、下载JMeter Load Test 的 JSON文件和Jmeter依赖包

2、在Grafana中导入json模版
设置DB

3、配置Jmeter
3.1 将下载的JMeter-InfluxDB-Writer-plugin-xx.xx.jar放到Jmeter的/lib/ext目录下
3.2 在Jmeter脚本中添加 Backend Listener (Add -> Listener -> Backend Listener)
3.3 Backend Listener implementation选择{JMeterInfluxDBBackendListenerClient}
3.4 配置参数列表

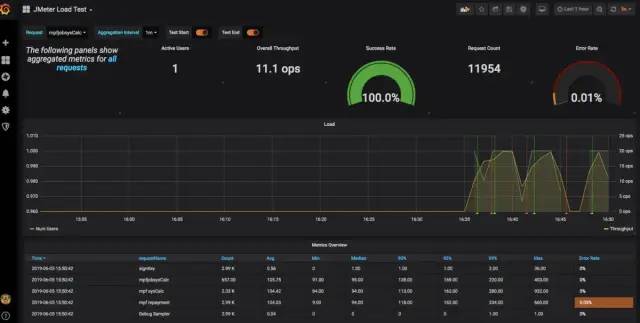
最后运行脚本,可以看到DashBoard
参考:
https://xiexianbin.cn/database/influxdb/2018-04-09-influxdb/
https://blog.csdn.net/zuozewei/article/details/82911173
-------- THE END --------