
消息队列常见问题总结和分析
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
作者 | 九卷
来源 | urlify.cn/BRjiIr
一、简介
很久以前也写过一篇关于消息队列的文章,这里的文章,这篇文章是对消息队列使用场景,以及一些模型做过一点介绍。
这篇文章将分析消息队列常见问题。
消息队列:利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统集成。
从定义看:它是一种数据交流平台,也是数据通信平台。
然而,数据通信我们可以用http,RPC来进行通信,这些与消息队列有什么区别呢?
最大的区别就是同步和异步。http和RPC一般都是同步,而消息队列是异步。
二、为什么要用消息队列
1.解耦
双方不在基于对方直接通信了,而是基于消息队列来通信,通过MQ解耦了客户端和服务端通信。处理数据的双方关注的点不同了,比如说一个事务,我们只关心核心流程,而需要依赖其他系统但不是那么重要的事情,有通知即可,不需要等待结果。这种消息模型,关心的是通知,而不在意处理过程。也可以用消息队列。
上下游开发人员也可以基于消息队列发送消息,而不需要同步的处理消息了。
2.异步处理
传统的业务逻辑都是基于同步的方式进行处理的。而有了消息队列,就可以把消息存放在MQ里,消息队列的消费者就可以从消息队列中获取数据并进行处理。它不一定要实时处理,可以隔几分钟处理消息队列里的数据。
3.削峰和流控
这里有点像计算机中的硬件,比如CPU和内存,CPU运算速度比内存高N个数量级,那怎么才能缓解两者之间的差异?中间加一个缓存来缓解两者速度的差异。
同理,MQ也可以起到这种作用。对于上下游软件不同的处理速度的差异进行调节。
比如,我们常见的秒杀应用,前端瞬间涌入成千上万的请求,前端可以承受这么大的请求压力,但是复杂的后端系统,肯定会被压垮,从而导致秒杀服务不可以用的情况。为了解决这种前后端处理速度不平衡的差异,导致的服务问题,可以引入消息队列来调节,用消息队列来缓存用户的请求,等待后端系统来消费。
上面就是消息队列的主要功能,当然还有其他一些功能,比如消息广播,最终一致性等。
使用MQ后的问题
当然使用了消息队列,会增加系统的复杂性,一致性延迟,可用性降低等问题。
可用性降低是指系统可用性降低,如果MQ挂了,那么肯定会影响到整个系统了。
因为上下游系统可能都会与MQ交互。
三、什么时候引入MQ?
这个要看业务系统功能需求,一个是系统处理是否到达了瓶颈,需要消息队列来缓解;
还有,业务系统一致性要求是不是特别高。通常业务系统不会要求那么高的一致性要求。当然一些高频交易系统,一致性要求特别高,就不适合用了。
引入任何一个新的软件必然会增加原有系统的复杂性,还是要根据业务特性进行合理的选择。
四、消息队列常见问题
1.如何保证消息不被重复消费(怎么保证幂等)
为什么会重复消费
生产者:也就是客户端,可能会重复推送一条数据到MQ中。有可能是客户端超时重复推送,也有可能是网络比较慢客户端重复推送了数据到MQ中。
MQ:消费者消费完了一条数据,发送ACK信息表示消费成功时,这时候,MQ突然挂了,导致MQ以为消费者还未消费该条消息,MQ恢复后再次推送了该条消息,导致重复消费。
消费者:与上面MQ挂掉情况类似,消费者已经消费完了一条消息,正准备给MQ发送ACK消息但还未发送时,这时候消费者挂了,服务重启后MQ以为消费者还没有消费该条消息,再次推送该条消息。
怎么处理重复消费
每个消息都带一个唯一的消息id。消费端保证不重复消费就可以了,即使生产端产生了重复的数据,当然生产端也最好控制下重复数据。
消费端保证不重复消费:
通常方法都是存储消费了的消息,然后判断消息是否存在。
1.先保存在查询
每次保存数据前,先查询下,不存在就插入。这种是并发不高的情况下可以使用。
2.数据库添加唯一约束条件
比如唯一索引
3.增加一个消息表
已经消费的消息,把消息id插入到消息表里面。
为了保证高并发,消息表可以用Redis来存。
2.如何处理消息丢失的问题
消息丢失的原因
生产者:生产者推送消息到MQ中,但是网络出现了故障,比如网络超时,网络抖动,导致消息没有推送到MQ中,在网络中丢失了。又或者推送到MQ中了,但是这时候MQ内部出错导致消息丢失。
MQ:MQ自己内部发生了错误,导致消息丢失。
消费者:有时处理消息的消费者处理不当,还没等消息处理完,就给MQ发送确认信息,但是这时候消费者自身出问题,挂了,确认消息已经发送给MQ告诉MQ自己已经消费完了,导致消息丢失。
如何保证消息不丢失呢?下面谈谈这方面的做法。
3.如何保证消息可靠性传输
整个消息从生产到消费一般分为三个阶段:生产者-生产阶段,MQ-存储阶段,消费者-消费阶段
3.1 生产者-生产阶段
在这个阶段,一般通过请求确认机制,来保证消息可靠性传输。与TCP/IP协议里ACK机制有点像。
客户端发送消息到消息队列,消息队列给客户端一个确认响应,表示消息已经收到,客户端收到响应,表示一次正常消息发送完毕。
3.2 MQ-存储阶段
消息队列给客户端发送确认消息。存储完成后,才发送确认消息。
3.3 消费者-消费阶段
跟生产阶段相同,消费完了,给消息队列发送确认消息。
4.如何保证消息的顺序性
我们日常说的顺序性是什么呢?
比如说小孩早上上学过程,他先起床,然后洗漱,吃早餐,最后上学。我们认为他做的事情是有先后顺序的,及是时间的先后顺序,我们用时间来标记他的顺序。
更抽象的理解,这些发生的事件有一个相同的参考系,即他们的时间是对应同一个物理时钟的时间。
如果没有绝对的时间作为参考系,那他们之间还能确定顺序吗?
如果事件之间有因果关系,比如A、B两个事件是因果关系,那么A一定发生在B之前(前应后果)。相反,在没有一个绝对的时间的参考的情况下,若A、B之间没有因果关系,那么A、B之间就没有顺序关系。跟java里的happen before很像。
总结一下,我们说顺序时,其实说的是:
在有绝对时间作为参考系的情况下,事件发生的时间先后关系;
在没有绝对时间作为参考系的情况下,一种由因果关系推断出来的happening before的关系;
在分布式系统领域,有一篇关于时间,时钟和事件的顺序的很有名的一篇论文
Time, Clocks, and the Ordering of Events in a Distributed System,可以看一看,上面举例情况都是参考这篇论文。
参考上面的结论,在消息队列中,我们也是以时间作为参考系,让消息有序。
但是,在消息队列中,消息有序会遇到一些问题,下面让我们来讨论这些问题。
消息的顺序性的一些问题
在计算机系统中,有一个比较棘手的问题是,它可以是多线程执行的,而且哪个线程先运行,哪个线程后运行,完全是由操作系统决定的,完全没有规律,是乱序执行。显然与消息队列中的消息有序相悖。
还有,在消息队列中,涉及到生产者,MQ,消费者,还有网络,这4者之间的关系。然后他们又涉及到消息的顺序性,就有很多种情况需要考虑。可以参考这篇文章
分布式开放消息系统(RocketMQ)的原理与实践(作者:CHUAN.CHEN),各种情况讨论的很全面。
最后的结论就是:消息的顺序性,不仅仅是MQ本身存储消息要保证顺序性,还需要生产者和消费者一同来保证顺序性。
顺序性保证
在消息队列中,消息的顺序性需要3方面来保证:
1、生产者发送消息时要保证顺序
2、消息被消息队列存储时要保持和发送的顺序一致
3、消息被消费时保持和存储的顺序一致
生产者:发送时要求用户在同一个线程中采用同步的方式发送。
消息队列:存储保持和发送的顺序一致。一般是在一个分区中保持顺序性。
消费者:一个分区的消息由一个线程来处理消费消息。
https://www.hicsc.com/post/2020041566 这个链接中,作者分析了RocketMQ顺序消息的代码实现。
5.消息队列中消息延迟问题
你说的 消息的延迟 是延迟消息队列吗?啊,并不是,是完全2个不同的概念。延迟消息队列是MQ提供的一个功能。消息的延迟,是指消费端消费的速度跟不上生产端产生消息的速度,可能导致消费端丢失数据,也可能导致消息积压在MQ中。所以这里说的消息的延迟,指的是消费端消费消息的延迟。
消息队列的消费模型pull和push:
1、push模式
这种模式是消息队列主动将消息推送给消费者。
优点:尽可能实时的将消息发送给消费者进行消费。
缺点:如果消费端消费能力弱,消费端的消费速度赶不上生产端,而MQ又不断的给消费端推送消息,消费端的缓存满了导致缓存溢出,就会产生错误或丢失数据的可能。
2、pull模式
这种模式是由消费端主动向消息队列拉取消息。
优点:可以自主可控的拉取消息。
缺点:拉取消息的频率不好控制。
a、如果每次pull时间间隔比较久,会增加消息延迟,消息到达消费者时间会加长。这样时间一长会导致MQ中消息的堆积,而消息长时间堆积就会导致一系列的问题:
1、如果积压了几个小时的数据,有几千万的数据量,消费端处理的压力会越来越大。
2、如果是带有过期时间的消息,可能这些消息已经到了过期时间,因为积压时间太长,但还没被消费端消费掉,消费端来不及消费。
3、如果持续的积压,达到了MQ能存储消息数量的上限,也就是说MQ满了,存不下了,会导致MQ丢掉数据,导致数据丢失。
想一下,上面的情形是不是跟TCP/IP协议的流量控制和拥塞控制遇到的一些问题很像,也有很多不同。
b、如果每次pull的时间间隔比较短,在一段时间内MQ中没有可消费的消息,会产生很多无效的pull请求,导致一定的网络开销。
所以解决问题的办法最主要就是优化消费端的消费性能。1.优化消费逻辑 2.水平扩容,增加消费端并发。
延迟问题处理
如果消息堆积已经发生了,导致了上面的3个问题,这时怎么办?
1、积压了几个小时几千万的数据
第一:肯定要找到积压数据的原因,一般都是消费端的问题。
第二:如果可以的,扩大消费端的数量,快速消费掉消息。
第三:扩容,增加多机器消费。新建一个topic,partition是原来10倍,建立原先10倍的queue。然后写一个临时的消费程序,这个消费程序去转移积压的数据,把积压的数据均匀轮询写入建立好的10倍数量的queue。然后在征用10倍机器的消费端来消费这个queue。这种做法相当于临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据。消费完了,恢复原来的部署。这是大厂做法。
2、积压时间过长,带有过期时间的消息过期失效了
这个没有好的办法处理,只能通过程序找出丢失的数据,然后也是通过程序把丢失的数据重新导入到MQ里,重新消费。
3、长时间积压倒是MQ写满了
这个也没啥好办法处理,只能快速消费掉MQ里的数据,快速消费指消费一个,丢掉一个,不要这些数据了,然后重新导入数据。用户少的时候在补回数据。
6.消息队列高可用
6.1 kafka
kafka基本架构:
Broker:一个kafka节点就是一个broker,多个broker组成一个kafka集群。一个broker可以是一个单机器kafka服务器。
Topic:存放消息的主题,相当于一个队列。可以理解为存放消息的分类,比如你可以有前端日志的Topic,后端日志的Topic。可以理解为MySQL里的表。
Partition:一个topic可以划分为多个partition,每个partition都是一个有序队列。把topic主题中的消息进行分拆,均摊到kafka集群中不同机器上。partition是topic的进一步拆分。
Replica:副本消息。kafka可以以partition为单位,保存多个副本,分散在不同的broker上。副本数是可以设置的。
Segment: 一个Partition被切分为多个Segment,每个Segment包含索引文件和数据文件。
Message:kafka里最基本消息单元。
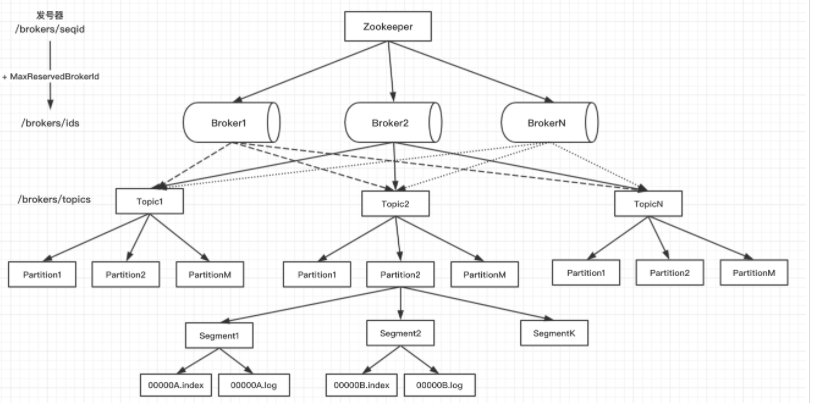
一个kafka集群可以由多个broker组成,每个broker是一个节点,你创建一个topic,这个topic可以划分为多个partition,每个partition可以存储在不同的broker上,每个partition存放一部分数据。
6.2 RocketMQ
在 RocketMQ 4.5 版本之前,RocketMQ 只有 Master/Slave 一种部署方式来实现高可用。
一组 Broker 中有一个 Master,有零到多个 Slave,Slave 通过同步复制或异步复制方式去同步 Master 的数据。Master/Slave 部署模式,提供了一定的高可用性。
上面主从高可用架构有一个缺点:
主节点挂了后需要人为的进行重启或者切换。为了解决这个问题,后续引入了raft,用raft协议来完成自动选主。RocketMQ的DLedger 就是一个基于 raft 协议的 commitlog 存储库,也是 RocketMQ 实现新的高可用多副本架构的关键。
还可以多master多slave部署,防止单点故障。
五、参考
https://www.hicsc.com/post/2020041566
https://tech.meituan.com/2016/07/01/mq-design.html
https://lamport.azurewebsites.net/pubs/time-clocks.pdf
https://rocketmq.apache.org/docs/quick-start/
https://github.com/apache/rocketmq
https://github.com/apache/rocketmq/tree/master/docs/cn
https://github.com/apache/kafka
https://kafka.apache.org/documentation/#gettingStarted
https://bug-free.cn/2020/01/09/Kafka-架构设计/
粉丝福利:Java从入门到入土学习路线图
???

?长按上方微信二维码 2 秒
感谢点赞支持下哈 