
吴恩达:22张图全解深度学习知识
↑↑↑点击上方蓝字,回复资料,10个G的惊喜
来源:知乎、智能计算芯世界 作者:Sophia
深度学习基础


sigmoid:sigmoid 函数常用于二分分类问题,或者多分类问题的最后一层,主要是由于其归一化特性。sigmoid 函数在两侧会出现梯度趋于零的情况,会导致训练缓慢。 tanh:相对于 sigmoid,tanh 函数的优点是梯度值更大,可以使训练速度变快。 ReLU:可以理解为阈值激活(spiking model 的特例,类似生物神经的工作方式),该函数很常用,基本是默认选择的激活函数,优点是不会导致训练缓慢的问题,并且由于激活值为零的节点不会参与反向传播,该函数还有稀疏化网络的效果。 Leaky ReLU:避免了零激活值的结果,使得反向传播过程始终执行,但在实践中很少用。





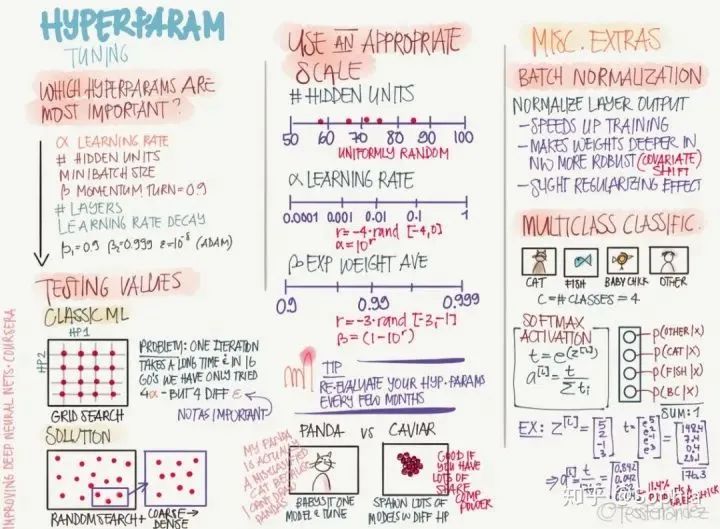
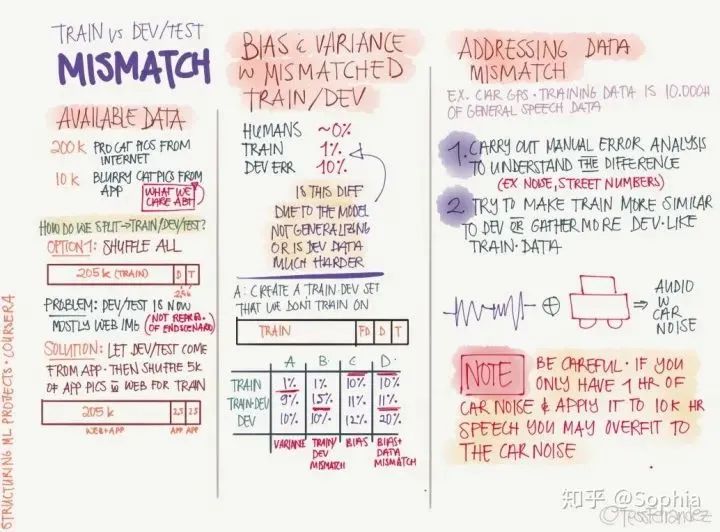
依靠经验:聆听自己的直觉,设置感觉上应该对的参数然后看看它是否工作,不断尝试直到累趴。 网格搜索:让计算机尝试一些在一定范围内均匀分布的数值。 随机搜索:让计算机尝试一些随机值,看看它们是否好用。 贝叶斯优化:使用类似 MATLAB bayesopt 的工具自动选取最佳参数——结果发现贝叶斯优化的超参数比你自己的机器学习算法还要多,累觉不爱,回到依靠经验和网格搜索方法上去。

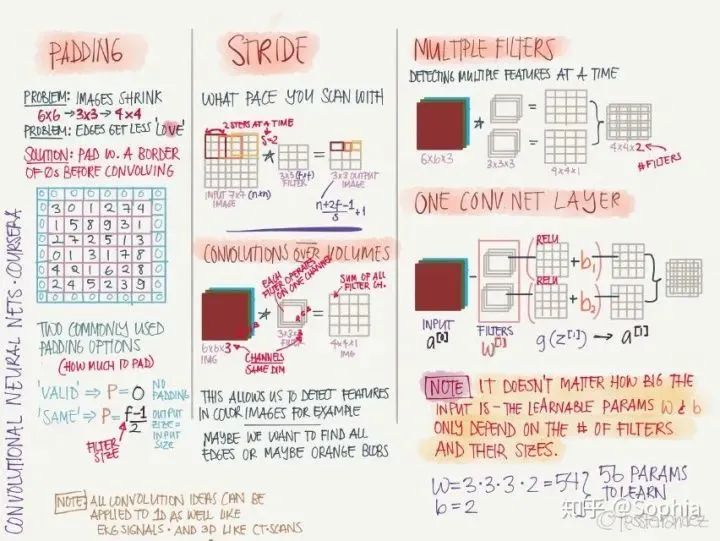
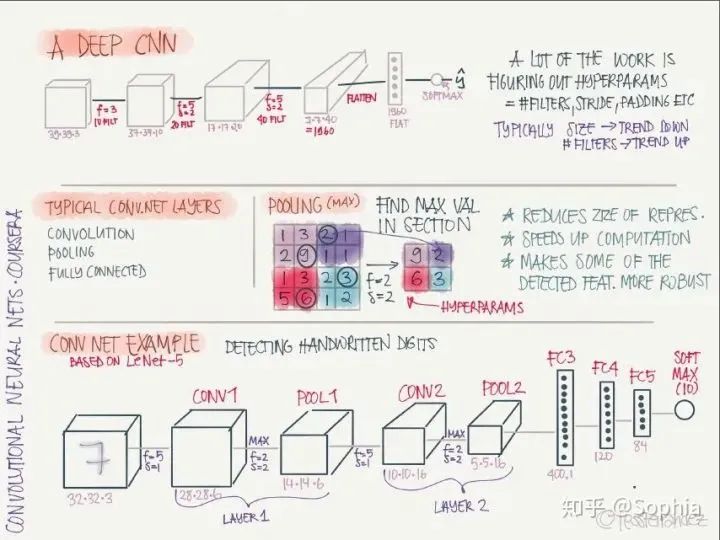
卷积网络

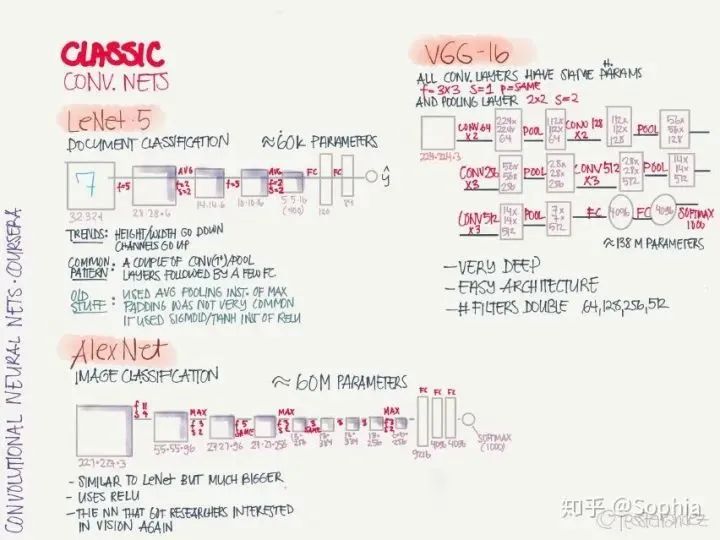
LeNet·5:手写识别分类网络,这是第一个卷积神经网络,由 Yann LeCun 提出。 AlexNet:图像分类网络,首次在 CNN 引入 ReLU 激活函数。 VGG-16:图像分类网络,深度较大。

ResNet: 引入残差连接,缓解梯度消失和梯度爆炸问题,可以训练非常深的网络。 Network in Network: 使用 1x1 卷积核,可以将卷积运算变成类似于全连接网络的形式,还可以减少特征图的通道数,从而减少参数数量。 Inception Network: 使用了多种尺寸卷积核的并行操作,再堆叠成多个通道,可以捕捉多种规模的特征,但缺点是计算量太大,可以通过 1x1 卷积减少通道数。
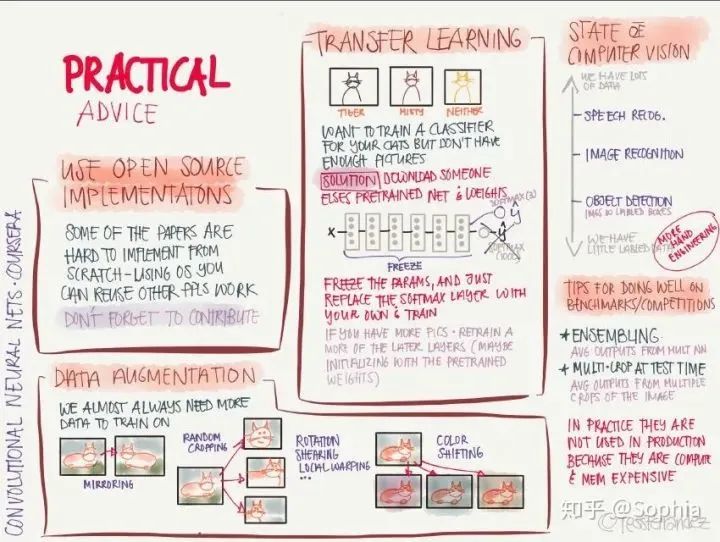
使用开源实现: 从零开始实现时非常困难的,利用别人的实现可以快速探索更复杂有趣的任务。 数据增强: 通过对原图像进行镜像、随机裁剪、旋转、颜色变化等操作,增加训练数据量和多样性。 迁移学习: 针对当前任务的训练数据太少时,可以将充分训练过的模型用少量数据微调获得足够好的性能。 基准测试和竞赛中表现良好的诀窍: 使用模型集成,使用多模型输出的平均结果;在测试阶段,将图像裁剪成多个副本分别测试,并将测试结果取平均。
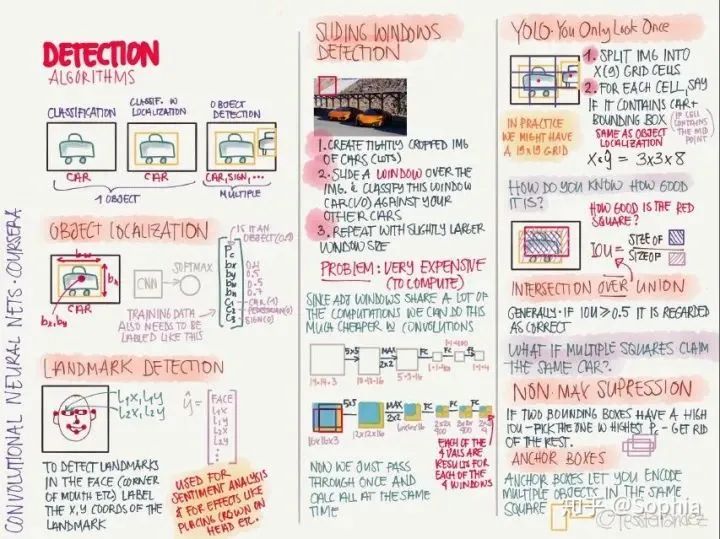

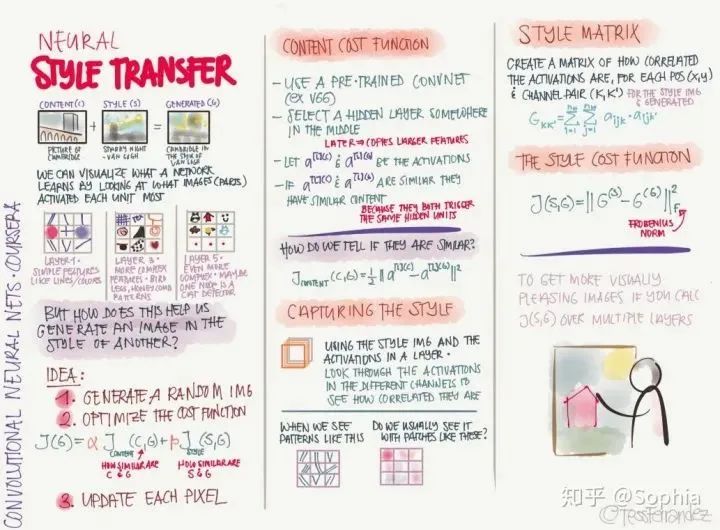
循环网络




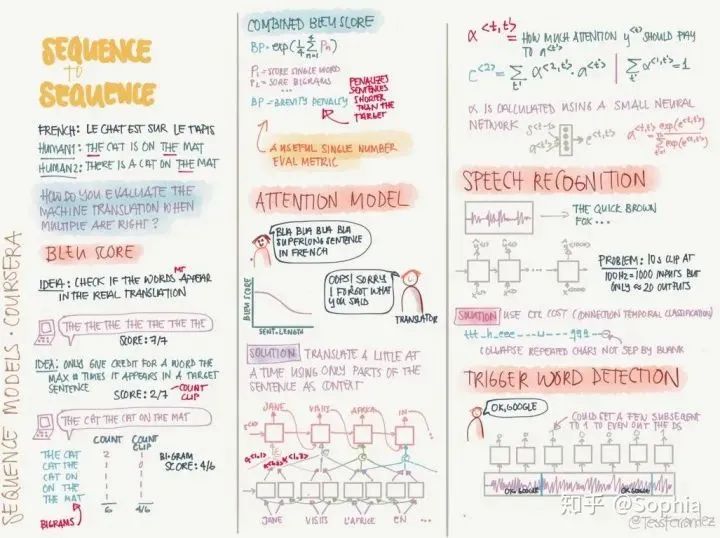
推荐阅读
(点击标题可跳转阅读)
评论