
PowerBI 全网首发原生平滑曲线 - 通用模板及应用

书接上回,我们研究了折线如何变成曲线,如下:

并得到了最终的终极方案:
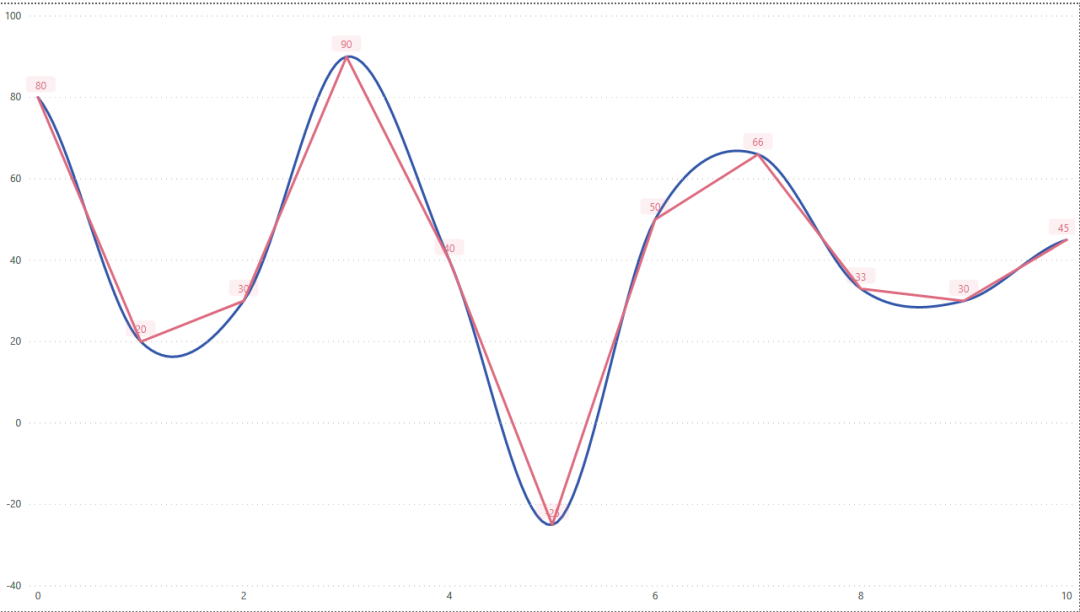
它满足了:
足够简单
连续光滑
性能够好
那么问题来了:
要单独构建两个辅助表
是否可以让 X 轴不显示序号而是真实信息
也就是通用化问题。
答案是非常肯定的。
效果
我们都知道,在给出年月计算新老客户以及活跃用户数是相对比较复杂的计算,我们来看看最终效果:
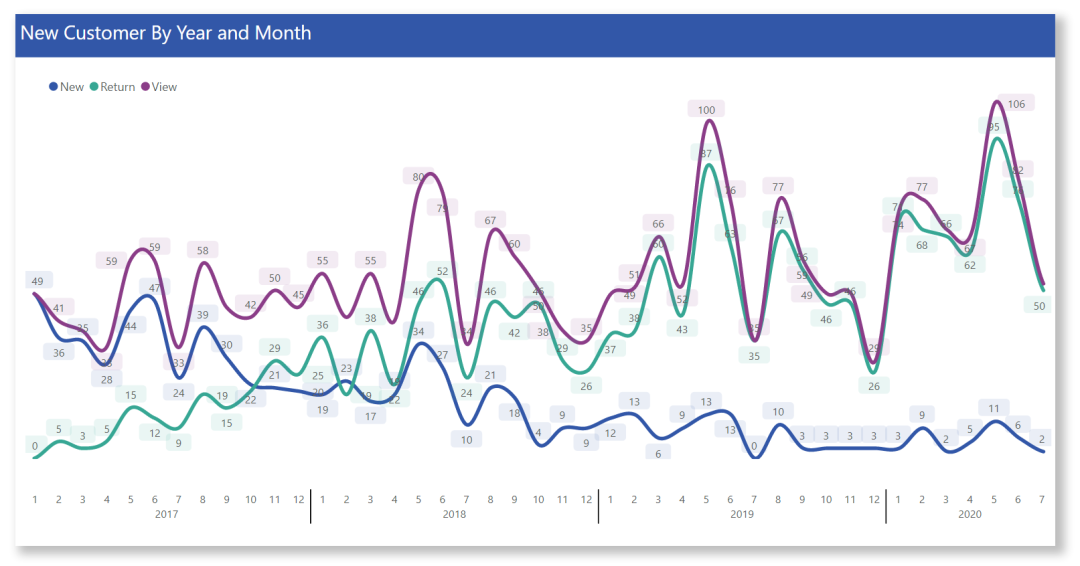
这个效果完全满足了需求。
请观察几个点:
2017年01月,活跃用户由纯新用户供应49人,老用户0人。
2017年11月,活跃用户50人,分别对应新用户21人与老用户29人。
2019年05月,活跃用户100人,分别对应新用户13人与老用户87人。
2019年07月,活跃用户35人,新用户0人,完全由老用户供应。
整套曲线的显示很完美。
再观赏坐标轴,图例,曲线颜色,标签,标签背景颜色都完美配合。
这的确实现了想要的一切,这套曲线是连续光滑的,避免了折线图的生硬。
如果是折线图,会是这样:
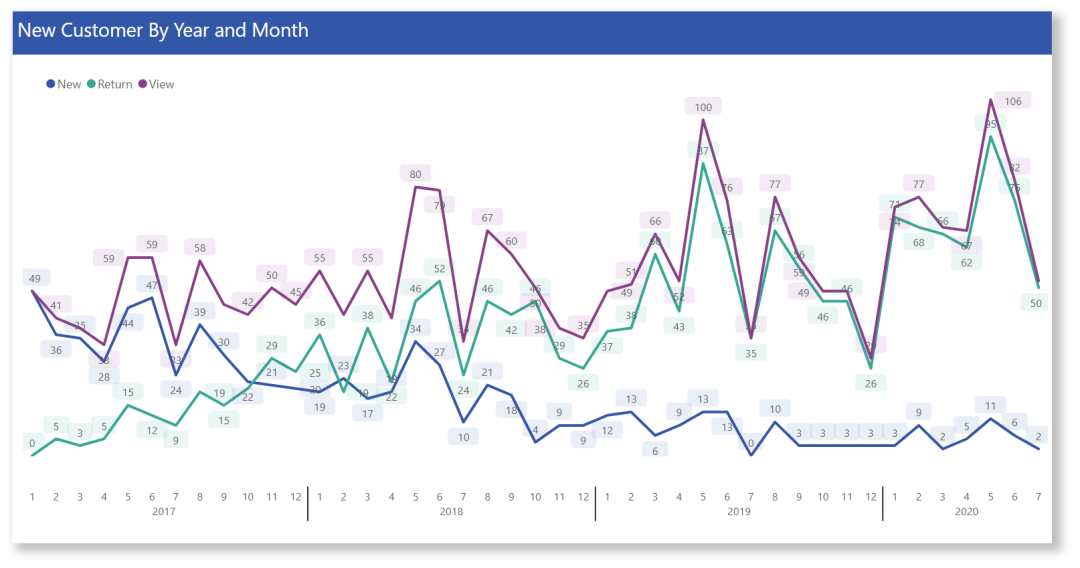
不对比不知道,一对比,就看出平滑曲线的优雅了。
上文有伙伴留言:
Excel 里点一下就好了
Tableau 里点一下就好了
没有错。
这两句话是用来怼BI佐罗好还是用来怼PowerBI产品组好呢?
明明是 PowerBI 产品组应该做的事,偏偏不做,把时间用来研究 PowerBI 的logo不叫logo叫Icon这种问题,而 BI佐罗 只能通过这么间接的方法来弥补了 PowerBI 的硬伤,反而捞不到什么好。一定要注意:这是 PowerBI 的问题。
那么我们这么做有意义吗?有的。
处于学习 PowerBI 尤其是 DAX 的阶段,这样的问题的解决可以极度提升个人的 DAX 以及 PowerBI 能力,而不是曲线问题本身。
很多人学习 PowerBI 以及学习 DAX,可以在这些问题中得以思考并实现是很有价值的。
最重要的是,本文要从根本上给出通用方法。
通用实现
一个问题的解决,并不是最难的,最难的在于:
通用化和可扩展化,适用于所有场景
以更高的性能运行与折线图不应该有任何性能差异
这两点居然被完美地解决了。
首先,来看方法的通用化。
如果我们的 X 轴是 0,1,2,...,N,那么,我们只需要这么做:
将 X 轴演化为:0.01,0.02,....1.00,1.01,1.02,...,2.00,2.01,2.02,...,3.00,4.00,...,N.00 即可。这样 X 轴就以10倍或者20倍拉伸除了更多的点。我们只要在这些点计算出值,并用纯折线图连接,由于点很多,看着就是平滑的曲线了。
但是,如果我们的 X 轴是年,月,甚至是年,月的层级怎么办?
如果您学习过《BI真经》就可以知道我们可以创建一个定制 X 轴,并保留年月层级同时做到扩大20倍,如下所示:
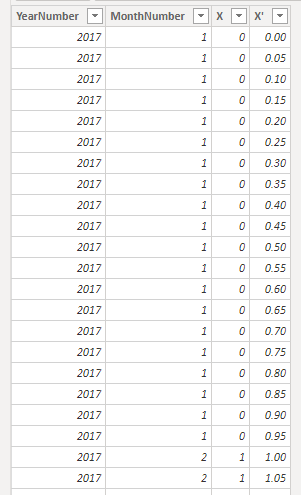
可以看出:
2017-01 的 X 是 0,而有 0.00 到 0.95 间隔 0.05 步长的 20 个点
X 和 X' 与该维度融合,无需另外制作
将这两个特定整合到一起真的太强大了,也就意味着:
当且仅当需要为某个折线图定制它的光滑曲线版本时,才进行仅一次维度定制即可。
接着,维度定制的方法存在通用性吗?
答案是肯定的。其通用算法如下:
Smooth.X.CRM.Date =
VAR _base =
VAR _last = EOMONTH( [Start:Date.LastDate.All] , -1 )
RETURN
CALCULATETABLE(
SUMMARIZE( 'Calendar' , [YearNumber] , [MonthNumber] ),
'Calendar'[Date] <= _last
)
VAR _base_indexKey =
ADDCOLUMNS(
_base,
"@IndexKey" , [YearNumber] * 100 + [MonthNumber]
)
// no need to change the DAX below:
VAR _index_temp = SELECTCOLUMNS( _base_indexKey , "@IndexKey" , [@IndexKey] )
VAR _base_index = SUBSTITUTEWITHINDEX( _base_indexKey , "X" , _index_temp , [@IndexKey] , ASC )
VAR _table_ex =
FILTER(
GENERATEALL( _base_index , SELECTCOLUMNS( GENERATESERIES( 0 , 19 ) , "X'" , [x] + [Value] / 20 ) ) ,
[X'] <= MAXX( _base_index , [X] )
)
RETURN _table_ex框架思路如下:
准备基本维度
将基本维度扩展出通用索引 X 以及 X'
其中,第一步需要编写,而第二步已经被模板化,无需做任何修改。
需要修改的 DAX 仅仅为:
VAR _base =
VAR _last = EOMONTH( [Start:Date.LastDate.All] , -1 )
RETURN
CALCULATETABLE(
SUMMARIZE( 'Calendar' , [YearNumber] , [MonthNumber] ),
'Calendar'[Date] <= _last
)
VAR _base_indexKey =
ADDCOLUMNS(
_base,
"@IndexKey" , [YearNumber] * 100 + [MonthNumber]
)也就是构建了一个在合理时间范围内的 年 月 表而已,这也是本来就必须要做的。
而将基本维度扩展出通用索引 X 以及 X' 的 DAX 无需做任何修改,已经神奇地做了通用实现。
没有《BI真经》作为基础,看不懂是很正常的,请学习《BI真经》。
那么,现在维度已经好了。
再来看度量值如何做才能:
通用化
高性能
这里我们借助《BI真经》给出的通用视图性能提升模式,给出通用化实现,如下:
CRM.User.New.Smooth =
VAR _x_curr = SELECTEDVALUE( 'Smooth.X.CRM.Date'[X] ) // 指定表
VAR _dx = SELECTEDVALUE( 'Smooth.X.CRM.Date'[X'] ) - SELECTEDVALUE( 'Smooth.X.CRM.Date'[X] ) // 指定表
VAR _view_table =
CALCULATETABLE(
ADDCOLUMNS(
SUMMARIZE( 'Smooth.X.CRM.Date' , [X] , [YearNumber] , [MonthNumber] ) , // 新维度
"Y" ,
CALCULATE(
[CRM.User.New] , // 原始度量值
TREATAS(
{ ( [YearNumber] , [MonthNumber] ) } , // 新维度
'Calendar'[YearNumber] , 'Calendar'[MonthNumber] // 原始维度
)
)
)
,
ALLSELECTED( )
)
// ------以下模板无需修改----------
VAR _y_min = MAXX( FILTER( _view_table , [X] = MINX( _view_table , [X] ) ) , [Y] )
VAR _y_max = MAXX( FILTER( _view_table , [X] = MAXX( _view_table , [X] ) ) , [Y] )
VAR _y0 = COALESCE( MAXX( FILTER( _view_table , [X] = _x_curr - 1 ) , [Y] ) , _y_min )
VAR _y1 = MAXX( FILTER( _view_table , [X] = _x_curr + 0 ) , [Y] )
VAR _y2 = MAXX( FILTER( _view_table , [X] = _x_curr + 1 ) , [Y] )
VAR _y3 = COALESCE( MAXX( FILTER( _view_table , [X] = _x_curr + 2 ) , [Y] ) , _y_max )
RETURN
VAR _u1 = _dx
VAR _u2 = _dx * _dx
VAR _a0 = -0.5 * _y0 + 1.5 * _y1 - 1.5 * _y2 + 0.5 * _y3
VAR _a1 = _y0 - 2.5 * _y1 + 2 * _y2 - 0.5 * _y3
VAR _a2 = -0.5 * _y0 + 0.5 * _y2
VAR _a3 = _y1
RETURN _a0 * _u1 * _u2 + _a1 * _u2 + _a2 * _u1 + _a3本来是复杂的度量值逻辑计算,在这里也做到了:
高度通用化,仅仅格式化的修改几个位置
用了视图层模式,以及对该问题的定制优化,性能非常快
这样,就完美地解决了度量值计算的问题。
理解视图层通用模式需要学习《BI真经》。
总结
本文给出了折线图的平滑曲线版本的完美通用实现以及所有的 DAX 细节。需要《BI真经》作为基础方能领悟其中的各种妙处。
从本文中不难看出在解决问题到通用化的过程中的通用模式,也就是模式的模式:
问题到模板
维度的通用化构建方法
维度的可变部分,用套路改有限的参数
维度的不变部分,模板化实现,永不修改
度量值的通用化头肩方法
度量值的可变部分,用套路改有限的参数
度量值的不变部分,模板化实现,永不修改
如果你学习过《BI真经》的《PBI高级》,你就可以看出,这里严格遵守了 OCP 原则(开放闭合原则)给出了稳定需求和可变需求的分离,让实现具备了通用性。
在选择10个点,20个点还是更多点作为插值元素方面以及索引从 0 开始而不是从 1 开始等很多细节都经过了极为巧妙地推演,读者可以自行研究,此处就不再赘述。
再来回顾最终的结果:
致敬:大学本科二年级《数学分析》第四章 - 函数的连续,曲线的光滑。
既然可以用于这个新老用户访问趋势图,本方案便可以用于任何曲线场景,完美通用实现。
缺乏 DAX 基础和数学基础的伙伴认为本文比较复杂也很正常,但在实际应用层面,仅仅是改几个参数的问题,已经可以无脑复制,但问题是如果您没有《BI真经》的学习,无脑复制也是有难度的。
最后,强烈建议有缘的你,如果正在学习 PowerBI 请学习《BI真经》,它可以推演出所有在 PowerBI 中需要的内容。
在订阅了BI佐罗讲授的《BI真经》之《BI进行时》课程区,除了可以下载本文案例,还可以观看视频讲解。
在视频讲解中,会更加详尽地介绍一些细节,连前几个视频将于 2 月初统一更新。

让数据真正成为你的力量
Create value through simple and easy with fun by PowerBI
Excel BI | DAX Pro | DAX 权威指南 | 线下VIP学习
扫码与PBI精英一起学习,验证码:data2021
PowerBI MVP 带你正确而高效地学习 PowerBI
点击“阅读原文”,即刻开始
↙