
从 BBR 到 BBRv2

2016 年 10 月份的一个 youtube 链接: Making Linux TCP Fast,首次发布了 BBR 算法, TCP 拥塞控制开启了新局面。
BBR 非常简单,它背后是一个单流理想模型:
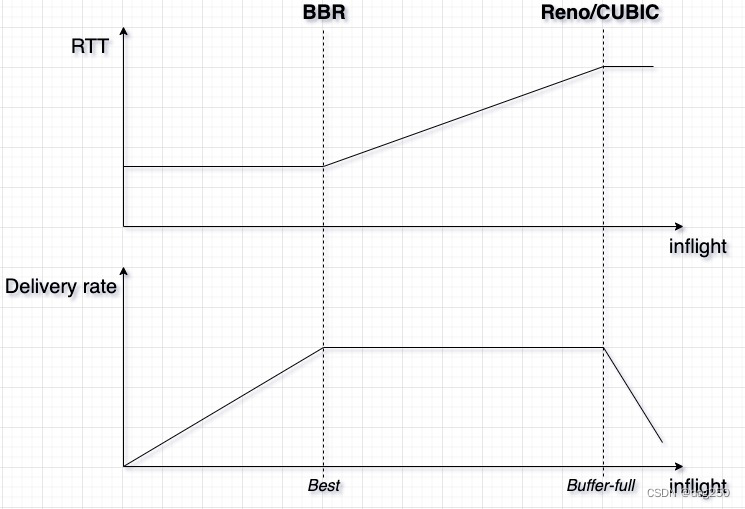
但现实情况并不遵循该模型,所以 BBR 的表现很难兑现承诺,特别在多流场景,公平性难保证,高重传换吞吐频繁发生。
下面是一个过程示意图:
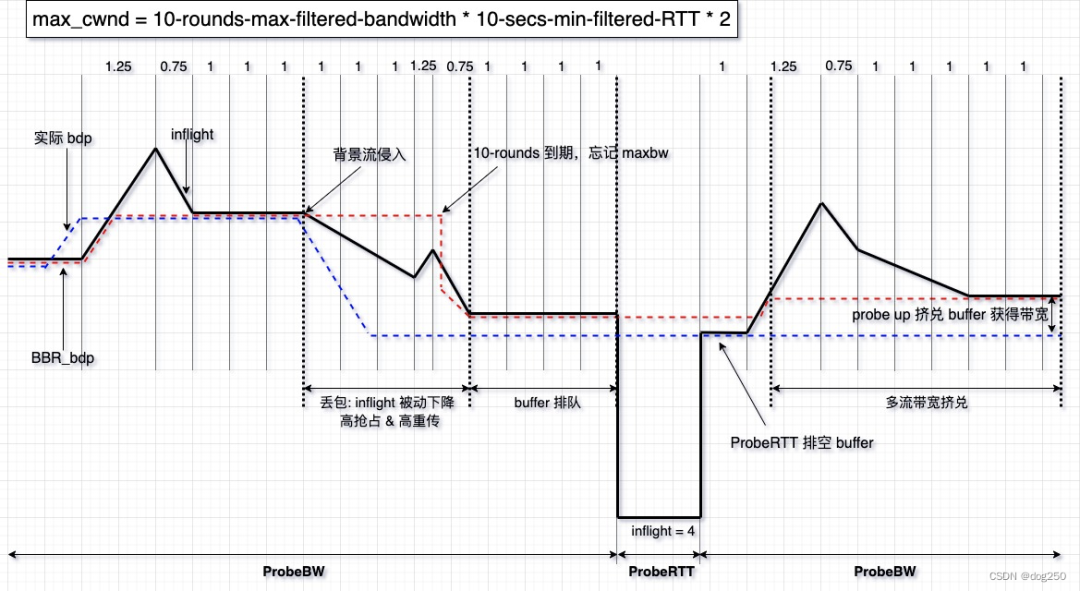
该表现的根本原因是 “BBR 必须用更多的 inflight 探测潜在带宽”。而 “更多的 inflight” 和 Loss-based 算法的 AI 过程无异,但却没有相应的 MD 反馈,这意味着 BBR 流的 inflight 很容易被拉到一个高水位。高水位的 inflight 很容易导致排队甚至丢包,而这正是 BBR 目标的反面。
多流共享瓶颈带宽,背景流的侵入和退出以及它们的 AIMD 易对 BBR 造成干扰,BBR 记录瞬时探测收益,并坚持 10-rounds,这种迟钝反应使 BBR 很难维持理想模型的状态机。
BBR 必须考虑更接近现实的场景,对 inflight 进行约束,这就是 BBRv2 的背景。
下面的背景引用来自:Understanding of BBRv2
However, in multiple BBRv1 flows, each sender overestimates the available bandwidth because of the max_filter that is immediately applied as new sending rate; therefore, the total amount of data sent from BBR hosts exceeds the pipe’s capacity, resulting in the standing queue creation. If the buffer sizes are not large enough to store excess data, the packet loss occurs. Moreover, this packet loss persists throughout the entire bandwidth sharing of multiple BBRv1 flows because BBRv1 does not reduce the maximum boundary of the inflight data, no matter how much packet loss occurs. This maximum boundary of the above-mentioned inflight data is the inflight cap, calculated as 2 BDP, and it is used to maintain the maximum throughput and low latency.
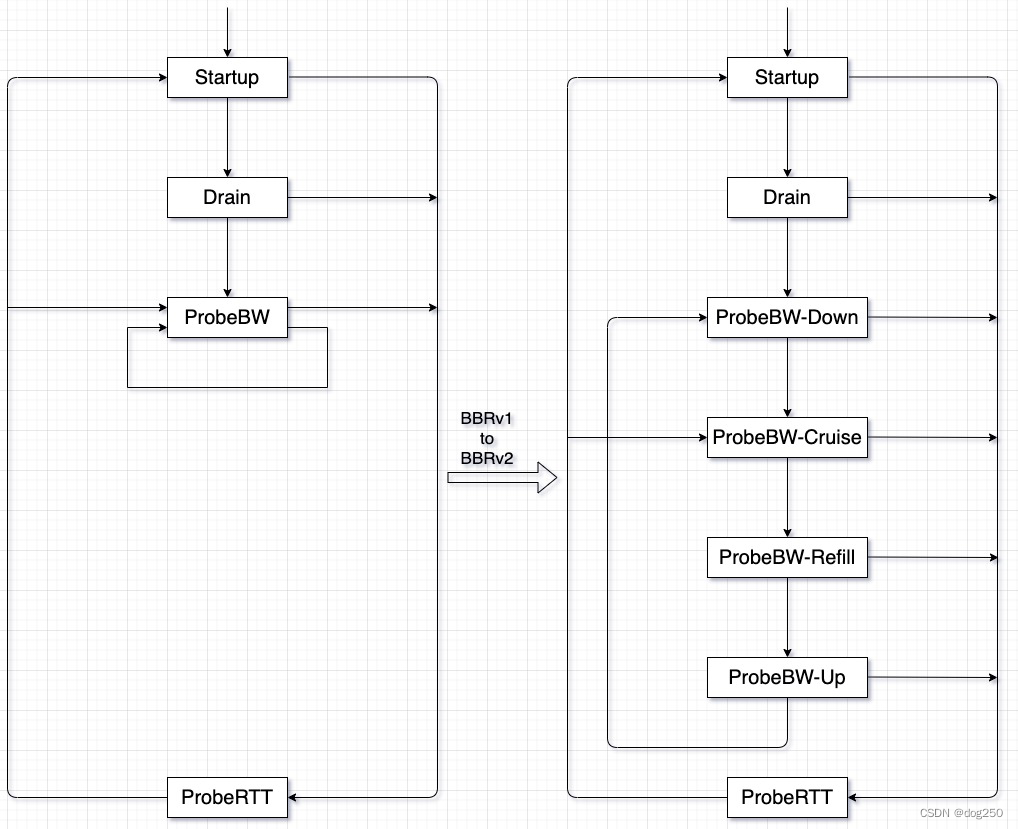
BBRv2 的核心在于 “更精确地测量 Delivery rate,并根据丢包,ECN 信号约束 inflight”。为此,BBRv2 在 ProbeBW 状态引入了一个子状态机:
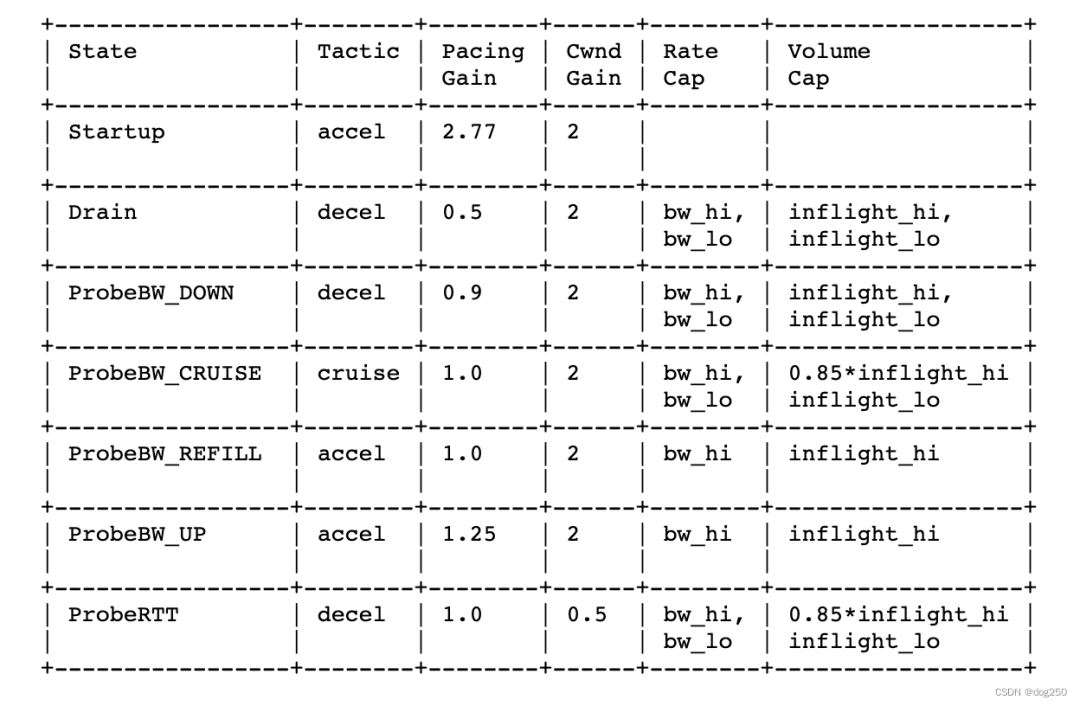
以下是约束细节,来自 BBRv2 draft:
下面是一个 BBRv2 的过程示意图:
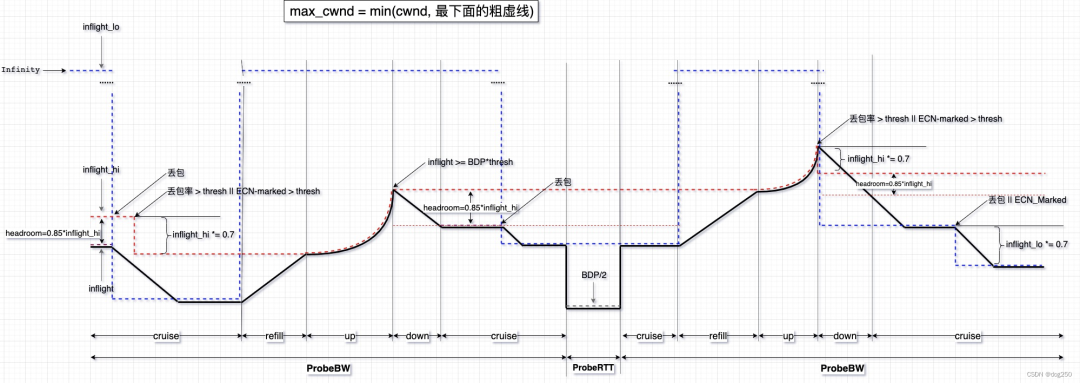
驱动 BBRv2 状态机转换的不再是固定的 phase,而完全基于 “丢包”,“ECN-Mark”,“公平性” 等变量 “随时” 进行 probe up 或 probe down:
实时跟踪丢包率与 ECN Mark,实时调整 inflight_hi/lo,限制实际 inflight。
实时跟踪丢包率与 ECN Mark,辅以公平性保证,驱动子状态机状态转换。
在 cruise 状态,保留 headroom 作为 “公地奉献”。
BBRv2 专门为 Reno/CUBIC 保留一个 AIMD 周期的时间窗口,该窗口等于 0.5*Max_cwnd = BDP 个 RTT 的时间(具体计算参考 Jacobson管道),两次 probe up 的时间不小于该窗口,同时在明确没有因 probe up 造成丢包的前提下,又可继续 probe up。
在上述窗口内,BBRv2 执行 cruise,对网络不注入任何干扰,让 Reno/CUBIC 安静 AI,由于 BBR probe up 采用 MI,它只在时间窗口过后,一次性执行 MI,在理论上,BBRv2 和 Reno/CUBIC 具有了同样的 probe 周期,建立了友好共存的基础。
如 BBRv2 draft 4.3.3.5.1 小节所述,BBRv2 希望在 DC 和 Internet 都能和 Reno/CUBIC 友好共存,巧合的是,两类网络的典型 BDP 是一致的:
DC 网络:40 Gbps / 8 bits-per-Byte * 20 us / (1514 Bytes) ~= 66 packets
Internet:25Mbps / 8 bits-per-Byte * 30 ms / (1514 bytes) ~= 62 packets
probe up 之后大约 60 多个 RTT,BBRv2 便可友好地再次 probe up,这个时间在 Internet 大约 2 secs,在 DC 网络大约 1.3 ms。该 Time Scale 不包含固定经验值,它是 rounds 的函数,自适应各类网络。这是一个事实上可靠的 BBR/Reno 共存保证。
和 BBRv1 的固定 8-rounds 一轮相比,BBRv2 probe up 间隔时间久了很多。策略是个好策略,但在我看来,现实场景中,都是异步流,BDP 个 RTT 的 AIMD 周期属高斯分布的右尾,取其期望均值是高尚的,大约 30~40 个 RTT 很合理。
最近看的一本书《系统之美》,提到 “有限理性” 一词,也叫 “看不见的脚”,和 亚当斯密 的 “看不见的手” 相对。“有限理性” 这个概念完全适用于多流共享带宽的场景,“有限理性” 的后果就是 “公地悲剧”,各方都在自私地获利,最终却分担恶果,这显然对每一方都有利。TCP AIMD 可以完美应对 “公地悲剧”,可 BBRv1 并不能。
在一个有限资源的系统中,BBRv2 越来越多地反馈外界背景事件,这是进步,而 BBRv1 似乎很少具有全局观,结合《系统之美》,BBRv2 正行走在突破 “公地悲剧” 的正确道路上。
单流吞吐虽下降,换取整体效果向善。
有了 TCP 友好性作为基础,和 Reno/CUBIC 整齐划一之后,BBRv2 便拥有了长期演进的可能性,最终作为 CUBIC 的接力者成为默认标准算法。相比之下,BBRv1 仅仅提供了一个新的思路,但它并没有为实际部署以及与传统 TCP 流共存做好准备。
但直到 Linux Kernel v6.1-rc2,也依然不见 BBRv2 合入(相比较而言,BBRv2 在 QUIC 上的进度却快很多),它依然仅存在于 Google 自己的分支:https://github.com/google/bbr/blob/v2alpha/net/ipv4/tcp_bbr2.c
工作中涉及到 DC 内部 TCP cc 演进的问题讨论,对于短突发,倾向于调大 init cwnd 为一个 BDP 左右,倾向于复用长连接,start from idle 的 cwnd 为 init cwnd。对于长流,倾向于 BBRv2,它确实比 DCTCP 更具有适应性,且包含了 DCTCP 的 feature。记录一篇,这篇可作为资料查询,因为形而上的东西不太多(但依然有)。