/* Delete a key, value, and associated expiration entry if any, from the DB. * If there are enough allocations to free the value object may be put into * a lazy free list instead of being freed synchronously. The lazy free list * will be reclaimed in a different bio.c thread. */ #define LAZYFREE_THRESHOLD 64 intdbAsyncDelete(redisDb *db, robj *key){ /* Deleting an entry from the expires dict will not free the sds of * the key, because it is shared with the main dictionary. */ if (dictSize(db->expires) > 0) dictDelete(db->expires,key->ptr);
/* If the value is composed of a few allocations, to free in a lazy way * is actually just slower... So under a certain limit we just free * the object synchronously. */ dictEntry *de = dictUnlink(db->dict,key->ptr); if (de) { robj *val = dictGetVal(de); // 计算value的回收收益 size_t free_effort = lazyfreeGetFreeEffort(val);
/* If releasing the object is too much work, do it in the background * by adding the object to the lazy free list. * Note that if the object is shared, to reclaim it now it is not * possible. This rarely happens, however sometimes the implementation * of parts of the Redis core may call incrRefCount() to protect * objects, and then call dbDelete(). In this case we'll fall * through and reach the dictFreeUnlinkedEntry() call, that will be * equivalent to just calling decrRefCount(). */ // 只有回收收益超过一定值,才会执行异步删除,否则还是会退化到同步删除 if (free_effort > LAZYFREE_THRESHOLD && val->refcount == 1) { atomicIncr(lazyfree_objects,1); bioCreateBackgroundJob(BIO_LAZY_FREE,val,NULL,NULL); dictSetVal(db->dict,de,NULL); } }
/* Release the key-val pair, or just the key if we set the val * field to NULL in order to lazy free it later. */ if (de) { dictFreeUnlinkedEntry(db->dict,de); if (server.cluster_enabled) slotToKeyDel(key->ptr); return1; } else { return0; } }
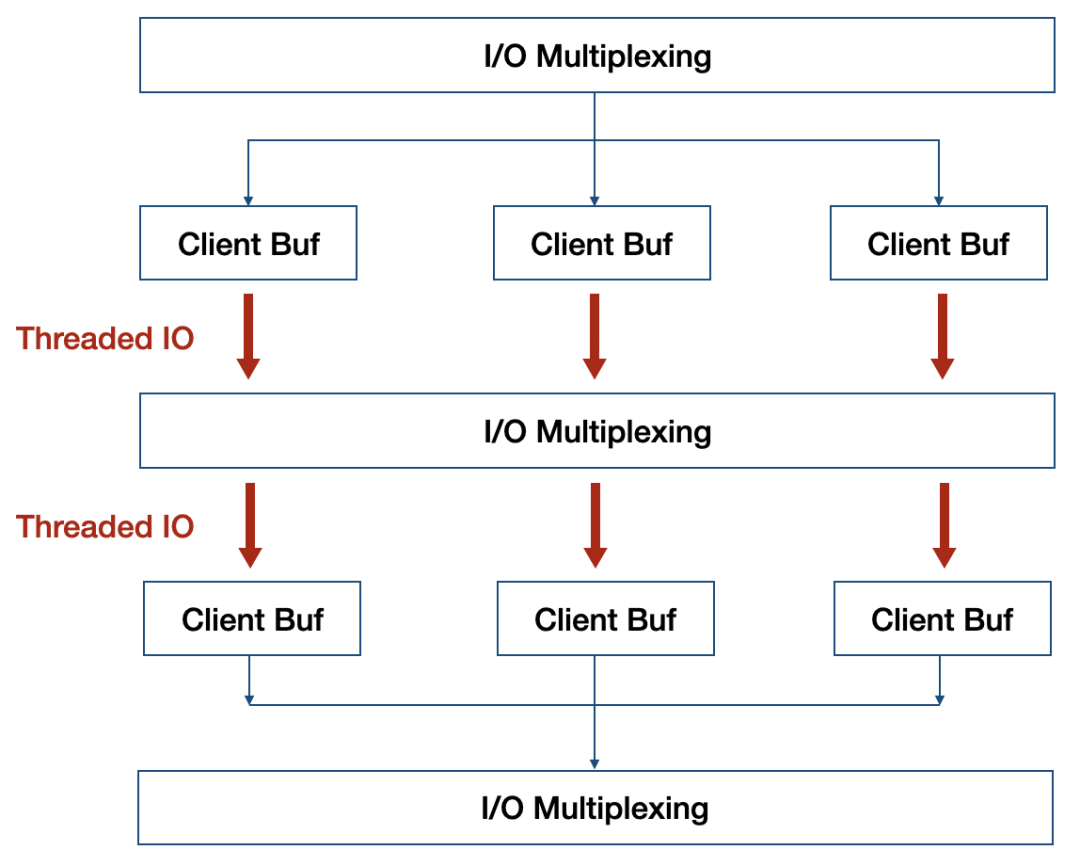
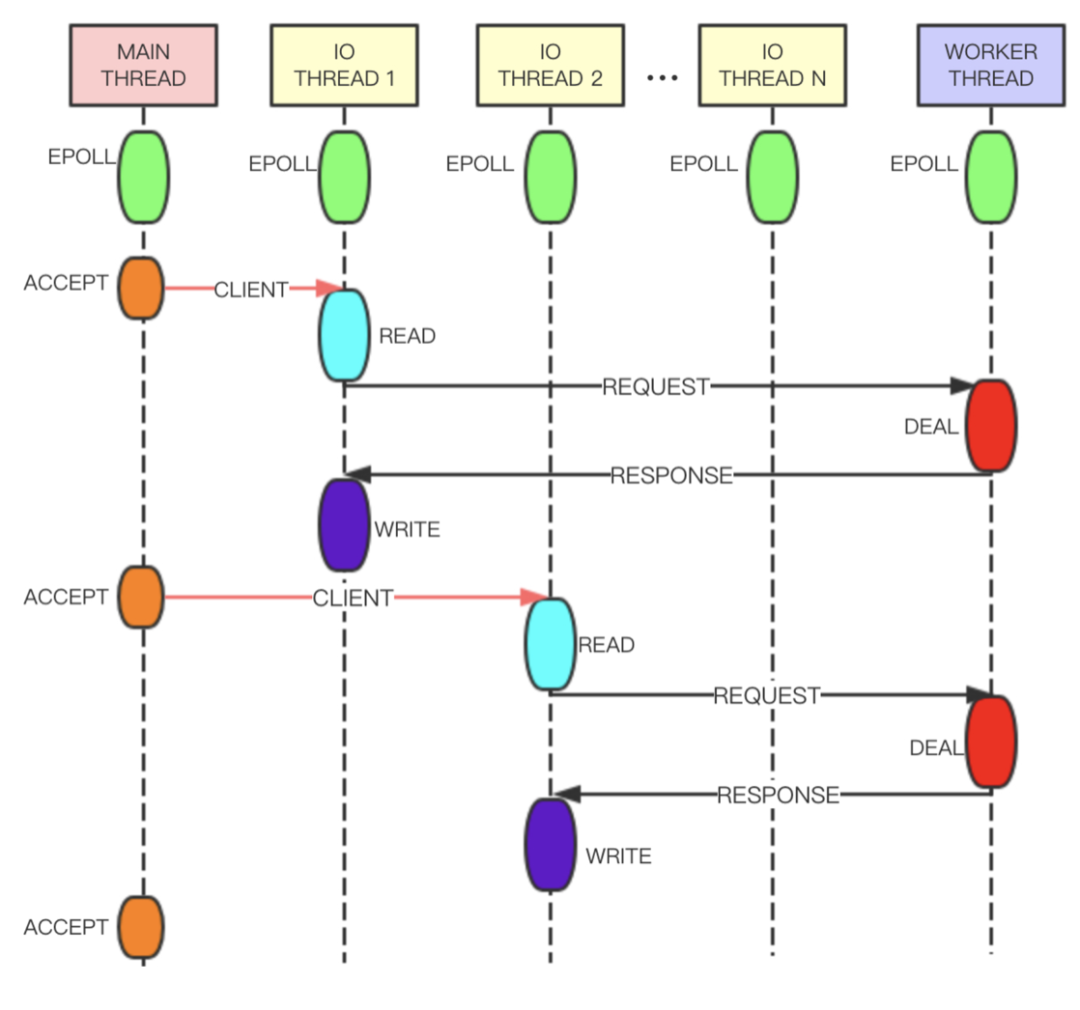
Now that values of aggregated data types are fully unshared, and client output buffers don’t contain shared objects as well, there is a lot to exploit. For example it is finally possible to implement threaded I/O in Redis, so that different clients are served by different threads. This means that we’ll have a global lock only when accessing the database, but the clients read/write syscalls and even the parsing of the command the client is sending, can happen in different threads.
/* Distribute the clients across N different lists. */ listIter li; listNode *ln; listRewind(server.clients_pending_read,&li); int item_id = 0; // 将等待处理的客户端分配给I/O线程 while((ln = listNext(&li))) { client *c = listNodeValue(ln); int target_id = item_id % server.io_threads_num; listAddNodeTail(io_threads_list[target_id],c); item_id++; }
...
/* Wait for all the other threads to end their work. */ // 轮训等待所有I/O线程处理完 while(1) { unsigned long pending = 0; for (int j = 1; j < server.io_threads_num; j++) pending += io_threads_pending[j]; if (pending == 0) break; }
I/O threading is not going to happen in Redis AFAIK, because after much consideration I think it’s a lot of complexity without a good reason. Many Redis setups are network or memory bound actually. Additionally I really believe in a share-nothing setup, so the way I want to scale Redis is by improving the support for multiple Redis instances to be executed in the same host, especially via Redis Cluster.
What instead I really want a lot is slow operations threading, and with the Redis modules system we already are in the right direction. However in the future (not sure if in Redis 6 or 7) we’ll get key-level locking in the module system so that threads can completely acquire control of a key to process slow operations. Now modules can implement commands and can create a reply for the client in a completely separated way, but still to access the shared data set a global lock is needed: this will go away.