
Python实现行转列?!超简单,赶快get起来

◆ ◆ ◆ ◆ ◆
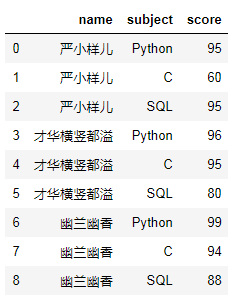
乍一看,好像没毛病啊!!
然鹅鹅鹅,当需求:=简单计算一下每个人的总分吧!来临的时候。我脑海中不禁浮想起了:

# 遇事不要慌,先导个包吧import pandas as pdimport numpy as np# 造假数据data = {'name':['严小样儿','严小样儿','严小样儿','才华横竖都溢','才华横竖都溢','才华横竖都溢','幽兰幽香','幽兰幽香','幽兰幽香'],'subject':['Python','C','SQL','Python','C','SQL','Python','C','SQL'],'score':[95,60,95,96,95,80,99,94,88]}# 生成dfdf = pd.DataFrame(data)df
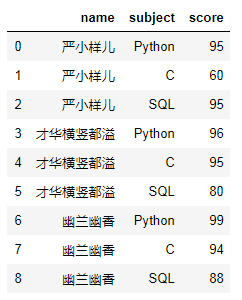
#df.pivot(index=None, columns=None, values=None)df.pivot(index='name',columns='subject',values='score')
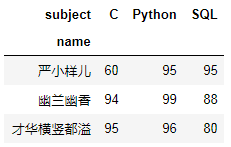

不要高兴的太早,遇到重复值就麻烦了!少侠请看:
# 造含有重复值的假数据data1 = {'name':['严小样儿','严小样儿','严小样儿','严小样儿','才华横竖都溢','才华横竖都溢','才华横竖都溢','幽兰幽香','幽兰幽香','幽兰幽香'],'subject':['Python','Python','C','SQL','Python','C','SQL','Python','C','SQL'],'score':[95,95,60,95,96,95,80,99,94,88]}df1 = pd.DataFrame(data1)df1
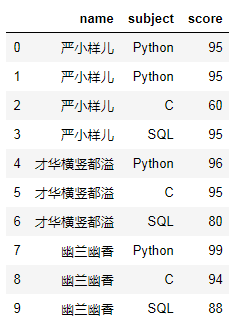
df1.pivot(index='name',columns='subject',values='score')# 一旦有重复值,就会报错。ValueError: Index contains duplicate entries, cannot reshape


别急别急,去个重不就可以了吗?!
df1.drop_duplicates().pivot(index='name',columns='subject',values='score')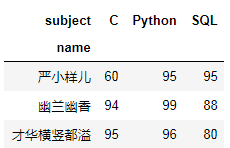
方法二:数据透视表
# pivot_table(data, values=None, index=None, columns=None, aggfunc='mean')pd.pivot_table(df1,index='name',columns='subject',values='score',aggfunc={'score':'max'})
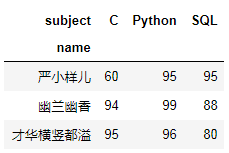
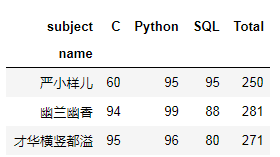
# 重复数据集也可以df_pivot = pd.pivot_table(df1,index='name',columns='subject',values='score',aggfunc={'score':'max'})# 增加一个新列:Totaldf_pivot['Total'] = df_pivot.apply(lambda x:np.sum(x),axis = 1)df_pivot
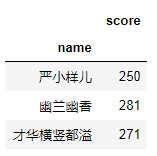
# 使用去重数据集才可以pd.pivot_table(df,index='name',values='score',aggfunc='sum')
# 使用join方法把总分列加进去。total = pd.pivot_table(df,index='name',values='score',aggfunc='sum')pd.pivot_table(df,index='name',columns='subject',values='score').join(total)
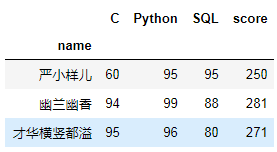
total1 = pd.pivot_table(df,index='name',values='score',aggfunc='sum').rename({'score':'总分'},axis=1)pd.pivot_table(df,index='name',columns='subject',values='score').join(total1)
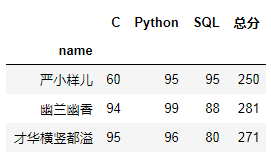
SQL如何实现行转列呢?!请戳:
记得点在看~

评论