
腾讯3面:说说前端监控平台/监控SDK的架构设计和难点亮点?
前言
事情是这样的,上周,我的一位两年前端经验的发小,在 腾讯三轮面试 的时候被问了一个问题:说说你们公司前端监控项目的架构设计和亮点设计 ;
而说回我这位发小,因为做过他们公司监控项目的可视化报表界面,所以简历上有写着前端监控项目的项目经验;但是不幸的是,他虽然前端基础相当不错,但并没有实际参与监控SDK的设计开发(只负责写监控的可视化分析界面),所以被问到这个问题,直接就一个懵了;结果也很正常,面试没过;
那么这篇文章,我就来介绍一下对于前端监控项目的 整体架构 和 可以做的亮点优化 ;前文几篇文章有介绍具体的前端监控实现,感兴趣的小伙伴可以点击链接跳转过去阅读; 传送门就在下面。
传送门
这篇文章的标题原拟定是:一文摸清前端监控实践要点(四)架构设计;但是我的发小面试刚好碰上了这么一个问题,于是我便将标题改为了这个。
一文摸清前端监控实践要点(一)性能监控[1]
一文摸清前端监控实践要点(二)行为监控[2]
一文摸清前端监控实践要点(三)错误监控[3]
腾讯三面:说说前端监控告警分析平台的架构设计和难点亮点?[4]
整体 架构设计
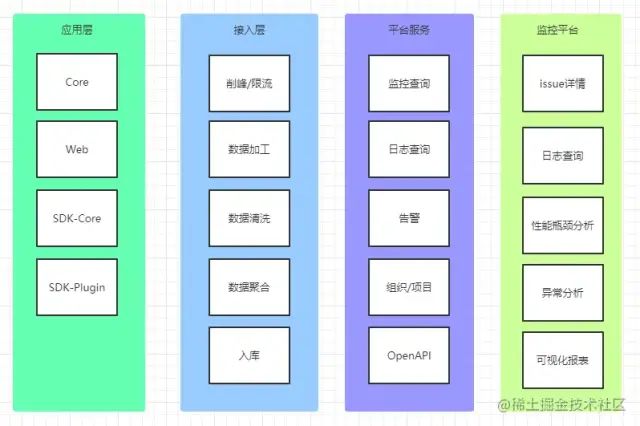
直接上图,我们在应用层SDK上报的数据,在接入层经过 削峰限流 和 数据加工 后,将原始日志存储于 ES 中,再经过 数据清洗 、数据聚合 后,将 issue(聚合的数据) 持久化存储 于 MySQL ,最后提供 RESTful API 提供给监控平台调用;
削峰限流是为了避免激增的大数据量、恶意用户访问等高并发数据导致的服务崩溃;数据加工是为了将IP、运营商、归属地等各种二次加工数据,封装进上报数据里;数据清洗是为了经由白名单、黑名单过滤等的业务需要,还有避免已关闭的应用数据继续入库;数据聚合是为了将相同信息的数据进行抽象聚合成issue,以便查询和追踪;
SDK 架构设计
为支持多平台、可拓展、可插拔的特点,整体SDK的架构设计是 内核+插件 的插件式设计;每个 SDK 首先继承于平台无关的 Core 层代码。然后在自身SDK中,初始化内核实例和插件;
值得一谈的点
下面将主要谈谈这些内容:前端监控项目除了正常的数据采集、数据报表分析以外;会碰上哪些难点可以去突破,或者说可以做出哪些亮点的内容?
SDK 如何设计成多平台支持?
首先我们先来了解一下,在前端监控的领域里,我们可能不仅仅只是监控一个 web环境 下的数据,包括 Nodejs、微信小程序、Electron 等各种其余的环境都是有监控的业务需求在的;
那么我们就要思考一个点,我们的一个 SDK 项目,既然功能全,又要支持多平台,那么怎么设计这个 SDK 可以让它既支持多平台,但是在启用某个平台的时候不会引入无用的代码呢?
最简单的办法:将每个平台单独放一个仓库,单独维护 ;但是这种办法的问题也很严重:人力资源浪费严重;会导致一些重复的代码很多;维护非常困难;
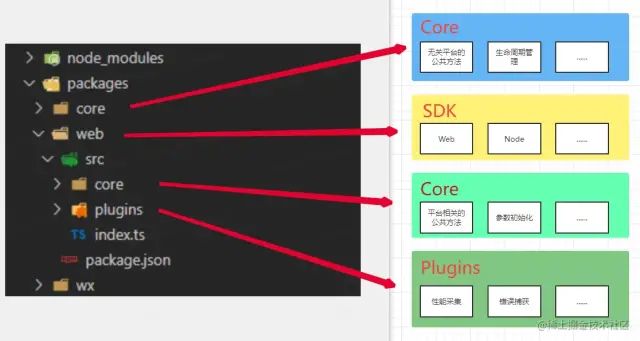
而较好一点的解决方案:我们可以通过插件化对代码进行组织:见下图
我们用 Core来管理SDK内与平台无关的一些代码,比如一些公共方法(生成mid方法、格式化);然后每个平台单独一个 SDK;去继承core的类;SDK 内自己管理SDK特有的核心方法逻辑,比如上报、参数初始化;最后就是 Plugins插件,每个SDK都是由内核+插件组成的,我们将所有的插件功能,比如性能监控、错误监控都抽离成插件;
这样子进行 SDK 的设计有很多好处:
每个平台分开打包,每个包的体积会大大缩小; 代码的逻辑更加 清晰自恰
最后打包上线时,我们通过修改 build 的脚本,对 packages 文件夹下的每个平台都单独打一个包,并且分开上传到 npm 平台;
SDK 如何方便的进行业务拓展和定制?
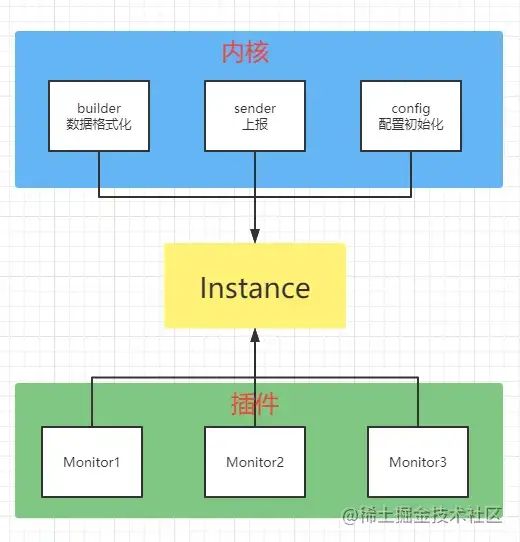
业务功能总是会不断迭代的,SDK 也一样,所以说我们在设计SDK的时候就要考虑它的一个拓展性;我们来看下图:
上图是 SDK 内部的一个架构设计 :内核+插件 的设计;
内核里是SDK内的 公共逻辑或者基础逻辑;比如数据格式化和数据上报是底下插件都要用到的公共逻辑;而配置初始化是SDK运行的一个基础逻辑;插件里是SDK的 上层拓展业务,比如说监听js错误、监听promise错误,每一个小功能都是一个插件;内核和插件一起组成了 SDK实例Instance,最后暴露给客户端使用;
而看了上图已经上文的解释,可拓展这个问题的答案已经很清晰了,我们需要拓展业务,只需要在内核的基础上,不断的往上叠加 Monitor 插件的数量就可以了;
至于说定制化,插件里的功能,都是使用与否不影响整个SDK运行的,所以我们可以自由的让用户对插件里的功能进行定制化,决定哪个监控功能启用、哪个监控功能不启用等等....
我这边举个代码例子,大家可以参考着看看就行:
// 服务于 Web 的SDK,继承了 Core 上的与平台无关方法;
class WebSdk extends Core {
// 性能监控实例,实例里每个插件实现一个性能监控功能;
public performanceInstance: WebVitals;
// 行为监控实例,实例里每个插件实现一个行为监控功能;
public userInstance: UserVitals;
// 错误监控实例,实例里每个插件实现一个错误监控功能;
public errorInstance: ErrorVitals;
// 上报实例,这里面封装上报方法
public transportInstance: TransportInstance;
// 数据格式化实例
public builderInstance: BuilderInstance;
// 维度实例,用以初始化 uid、sid等信息
public dimensionInstance: DimensionInstance;
// 参数初始化实例
public configInstance: ConfigInstance;
private options: initOptions;
constructor(options: initOptions) {
super();
this.configInstance = new ConfigInstance(this, options);
// 各种初始化......
}
}
export default WebSdk;
看上面的代码,我在初始化每个插件的时候,都将 this 传入进去,那么每个插件里面都可以访问内核里的方法;
SDK 在拓展新业务的时候,如何保证原有业务的正确性?
在上述的 内核+插件 设计下,我们开发新业务对原功能的影响基本上可以忽略不计,但是难免有意外,所以在 SDK 项目的层面上,需要有 单元测试 的来保证业务的稳定性;
我们可以引入单元测试,并对 每一个插件,每一个内核方法,都单独编写测试用例,在覆盖率达标的情况下,只要每次代码上传都测试通过,就可以保证原有业务的一个稳定性;
SDK 如何实现异常隔离以及上报?
首先,我们引入监控系统的原因之一就是为了避免页面产生错误,而如果因为监控SDK报错,导致整个应用主业务流程被中断,这是我们不能够接收的;
实际上,我们无法保证我们的 SDK 不出现错误,那么假如万一SDK本身报错了,我们就需要它不会去影响主业务流程的运行;最简单粗暴的方法就是把整个 SDK 都用 try catch 包裹起来,那么这样子即使出现了错误,也会被拦截在我们的 catch 里面;
但是我们回过头来想一想,这样简单粗暴的包裹,会带来哪些问题:
我们只能获取到一个报错的信息,但是我们无法得知报错的位置、插件; 我们没有将其上报,我们无法感知到 SDK 产生了错误 我们没法获取 SDK 出错的一个环境数据
那么,我们就需要一个相对优雅的一个异常隔离+上报机制,回想我们上文的架构:内核+插件的形式;我们对每一个插件模块,都单独的用trycatch包裹起来,然后当抛出错误的时候,进行数据的封装、上报;
这样子,就完成了一个异常隔离机制:
它实现了:当SDK产生异常时不会影响主业务的流程; 当SDK产生异常时进行数据的封装、上报; 出现异常后,中止 SDK 的运行,并移除所有的监听;
SDK 如何实现服务端时间的校对?
看到这里,可能有的同学并不明白,进行服务端时间的校对是什么意思;我们首先要明白,我们通过 JS 调用 new Date() 获取的时间,是我们的机器时间;也就是说:这个时间是一个随时都有可能不准确的时间;
那么既然时间是不准确的,假如有一个对时间精准度要求比较敏感的功能:比如说 API全链路监控;最后整体绘制出来的全链路图直接客户端的访问时间点变成了未来的时间点,直接时间穿梭那可不行;
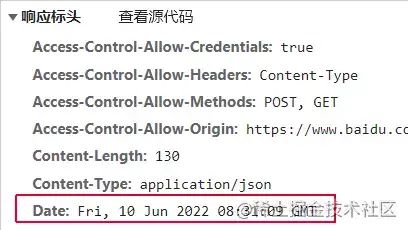
如上图,我们先要了解的是,http响应头 上有一个字段 Date;它的值是服务端发送资源时的服务器时间,我们可以在初始化SDK的时候,发送一个简单的请求给上报服务器,获取返回的 Date 值后计算 Diff差值 存在本地;
这样子就可以提供一个 公共API,来提供一个时间校对的服务,让本地的时间 比较趋近于 服务端的真实时间;(只是比较趋近的原因是:还会有一个单程传输耗时的误差)
let diff = 0;
export const diffTime = (date: string) => {
const serverDate = new Date(date);
const inDiff = Date.now() - serverDate.getTime();
if (diff === 0 || diff > inDiff) {
diff = inDiff;
}
};
export const getTime = () => {
return new Date(Date.now() - diff);
};
当然,这里还可以做的更精确一点,我们可以让后端服务在返回的时候,带上 API 请求在后端服务执行完毕所消耗的时间
server-timing,放在响应头里;我们取到数据后,将ttfb 耗时减去返回的server-timing再除以2;就是单程传输的耗时;那这样我们上文的计算中差的单程传输耗时的误差就可以补上了;
SDK 如何实现会话级别的错误上报去重?
首先,我们需要理清一个概念,我们可以认为:
在用户的 一次会话中,如果产生了同一个错误,那么将这同一个错误上报多次是没有意义的;在用户的 不同会话中,如果产生了同一个错误,那么将不同会话中产生的错误进行上报是有意义的;
为什么有上面的结论呢?理由很简单:
在用户的同一次会话中,如果点击一个按钮出现了错误,那么再次点击同一个按钮,必定会出现同一个错误,而这出现的多次错误,影响的是同一个用户、同一次访问;所以将其全部上报是没有意义的; 而在同一个用户的不同会话中,如果出现了同一个错误,那么这不同会话里的错误进行上报就显得有意义了;
所以说我们在第三篇文章《一文摸清前端监控实践要点(三)错误监控》[5]中有一个生成 错误mid 的操作,这是一个唯一id,但是它的唯一规则是针对于不同错误的唯一;
// 对每一个错误详情,生成一串编码
export const getErrorUid = (input: string) => {
return window.btoa(unescape(encodeURIComponent(input)));
};
所以说我们传入的参数,是 错误信息、错误行号、错误列号、错误文件等可能的关键信息的一个集合,这样保证了产生在同一个地方的错误,生成的 错误mid 都是相等的;这样子,我们才能在错误上报的入口函数里,做上报去重;
// 封装错误的上报入口,上报前,判断错误是否已经发生过
errorSendHandler = (data: ExceptionMetrics) => {
// 统一加上 用户行为追踪 和 页面基本信息
const submitParams = {
...data,
breadcrumbs: this.engineInstance.userInstance.breadcrumbs.get(),
pageInformation: this.engineInstance.userInstance.metrics.get('page-information'),
} as ExceptionMetrics;
// 判断同一个错误在本次页面访问中是否已经发生过;
const hasSubmitStatus = this.submitErrorUids.includes(submitParams.errorUid);
// 检查一下错误在本次页面访问中,是否已经产生过
if (hasSubmitStatus) return;
this.submitErrorUids.push(submitParams.errorUid);
// 记录后清除 breadcrumbs
this.engineInstance.userInstance.breadcrumbs.clear();
// 一般来说,有报错就立刻上报;
this.engineInstance.transportInstance.kernelTransportHandler(
this.engineInstance.transportInstance.formatTransportData(transportCategory.ERROR, submitParams),
);
};
SDK 采用什么样的上报策略?
对于上报方面来说,SDK的数据上报可不是随随便便就上报上去了,里面有涉及到数据上报的方式取舍以及上报时机的选择等等,还有一些可以让数据上报更加优雅的优化点;
首先,日志上报并不是应用的主要功能逻辑,日志上报行为不应该影响业务逻辑,不应该占用业务计算资源;那么在往下阅读之前,我们先来了解一下目前通用的几个上报方式:
信标( Beacon API)Ajax( XMLHttpRequest和fetch)Image( GIF、PNG)
我们来简单讲一下上述的几个上报方式
首先 Beacon API[6] 是一个较新的 API
它可以将数据以 POST方法将少量数据发送到服务端它保证页面卸载之前启动信标请求 并允许运行完成且不会阻塞请求或阻塞处理用户交互事件的任务。
然后 Ajax 请求方式就不用我多说了,大家应该平常用的最多的异步请求就是 Ajax;
最后来说一下 Image 上报方式:我们可以以向服务端请求图片资源的形式,像服务端传输少量数据,这种方式不会造成跨域;
上报方式
看了上面的三种上报方式,我们最终采用 sendBeacon + xmlHttpRequest 降级上报的方式,当浏览器不支持 sendBeacon 或者 传输的数据量超过了 sendBeacon 的限制,我们就降级采用 xmlHttpRequest 进行上报数据;
优先选用 Beacon API 的理由上文已经有提到:它可以保证页面卸载之前启动信标请求,是一种数据可靠,传输异步并且不会影响下一页面的加载 的传输方式。
而降级使用 XMLHttpRequest 的原因是, Beacon API 现在并不是所有的浏览器都完全支持,我们需要一个保险方案兜底,并且 sendbeacon 不能传输大数据量的信息,这个时候还是得回到 Ajax 来;
看到了这里,有的同学可能会问:为什么不用 Image 呀?那跨域怎么办呀?原因也很简单:
Image是以GET方式请求图片资源的方式,将上报数据附在URL上携带到服务端,而URL地址的长度是有一定限制的。规范对URL长度并没有要求,但是浏览器、服务器、代理服务器都对URL长度有要求。有的浏览器要求URL中path部分不超过2048,这就导致有些请求会发送不完全。至于 跨域问题,作为接受数据上报的服务端,允许跨域是理所应当的;
我们将其简单封装一下:
export enum transportCategory {
// PV访问数据
PV = 'pv',
// 性能数据
PERF = 'perf',
// api 请求数据
API = 'api',
// 报错数据
ERROR = 'error',
// 自定义行为
CUS = 'custom',
}
export interface DimensionStructure {
// 用户id,存储于cookie
uid: string;
// 会话id,存储于cookiestorage
sid: string;
// 应用id,使用方传入
pid: string;
// 应用版本号
release: string;
// 应用环境
environment: string;
}
export interface TransportStructure {
// 上报类别
category: transportCategory;
// 上报的维度信息
dimension: DimensionStructure;
// 上报对象(正文)
context?: Object;
// 上报对象数组
contexts?: Array<Object>;
// 捕获的sdk版本信息,版本号等...
sdk: Object;
}
export default class TransportInstance {
private engineInstance: EngineInstance;
public kernelTransportHandler: Function;
private options: TransportParams;
constructor(engineInstance: EngineInstance, options: TransportParams) {
this.engineInstance = engineInstance;
this.options = options;
this.kernelTransportHandler = this.initTransportHandler();
}
// 格式化数据,传入部分为 category 和 context \ contexts
formatTransportData = (category: transportCategory, data: Object | Array<Object>): TransportStructure => {
const transportStructure = {
category,
dimension: this.engineInstance.dimensionInstance.getDimension(),
sdk: getSdkVersion(),
} as TransportStructure;
if (data instanceof Array) {
transportStructure.contexts = data;
} else {
transportStructure.context = data;
}
return transportStructure;
};
// 初始化上报方法
initTransportHandler = () => {
return typeof navigator.sendBeacon === 'function' ? this.beaconTransport() : this.xmlTransport();
};
// beacon 形式上报
beaconTransport = (): Function => {
const handler = (data: TransportStructure) => {
const status = window.navigator.sendBeacon(this.options.transportUrl, JSON.stringify(data));
// 如果数据量过大,则本次大数据量用 XMLHttpRequest 上报
if (!status) this.xmlTransport().apply(this, data);
};
return handler;
};
// XMLHttpRequest 形式上报
xmlTransport = (): Function => {
const handler = (data: TransportStructure) => {
const xhr = new (window as any).oXMLHttpRequest();
xhr.open('POST', this.options.transportUrl, true);
xhr.send(JSON.stringify(data));
};
return handler;
};
}
上报时机
上报时机这里,一般来说:
PV、错误、用户自定义行为都是触发后立即就进行上报;性能数据需要等待页面加载完成、数据采集完毕后进行上报;API请求数据会进行本地暂存,在数据量达到10条(自拟)时触发一次上报,并且在页面可见性变化、以及页面关闭之前进行上报;如果你还要上报 点击行为等其余的数据,跟API请求数据一样的上报时机;
上报优化
或许,我们想把我们的数据上报做的再优雅一点,那么我们还有什么可以优化的点呢?还是有的:
启用 HTTP2,在HTTP1中,每次日志上报请求头都携带了大量的重复数据导致性能浪费。HTTP2头部压缩采用Huffman Code压缩请求头,能有效减少请求头的大小;服务端可以返回 204状态码,省去响应体;使用 `requestIdleCallback`[7] ,这是一个较新的 API,它可以插入一个函数,这个函数将在浏览器空闲时期被调用。这使开发者能够在主事件循环上执行后台和低优先级工作,而不会影响延迟关键事件,如果不支持的话,就使用 settimeout;
平台数据如何进行 削峰限流?
假设说,有某一个时间点,突然间流量爆炸,无数的数据向服务器访问过来,这时如果没有一个削峰限流的策略,很可能会导致机器Down掉,
所以说我们有必要去做一个削峰限流,从概率学的角度上讲,在大数据量的基础上我们对于整体数据做一个百分比的截断,并不会影响整体的一个数据比例。
简单方案-随机丢弃策略进行限流
前端做削峰限流最简单的方法是什么?没错,就是 Math.random() ,我们让用户传入一个采样率,
if(Math.random()<0.5) return;
非常简单的就实现了!但是这个方案不是一个很优雅的解决办法,为什么呢?
大流量项目限制了 50% 的流量,它的流量仍然多; 小流量项目限制了 50% 的流量,那就没有流量了;
优化方案-流量整型
现在做流量整形的方法很多,最常见的就是三种:
计数器算法:计数器算法就是单位时间内入库数量固定,后面的数据全部丢弃;缺点是无法应对恶意用户;漏桶算法:漏桶算法就是系统以固有的速率处理请求,当请求太多超过了桶的容量时,请求就会被丢弃;缺点是漏桶算法对于骤增的流量来说缺乏效率;令牌桶算法:令牌桶算法就是系统会以恒定的速度往固定容量的桶里放入令牌,当请求需要被处理时就会从桶里取一个令牌,当没有令牌可取的时候就会据拒绝服务;
对于上述三种限流方案的文章很多,我这里就不细展开描述,有兴趣的同学自己去找一下资料阅读;
我们先来分析一下:
计数器能够削峰,限制最大并发数以保证服务高可用令牌桶实现流量均匀入库,保证下游服务健康
最后我们团队在上述的方案选择中,最终选择了 计数器 + 令牌桶 的方案;这也是参考了 前端早早聊 李振:如何从 0 到 1 建设前端性能监控系统[8] 的限流方案分享;
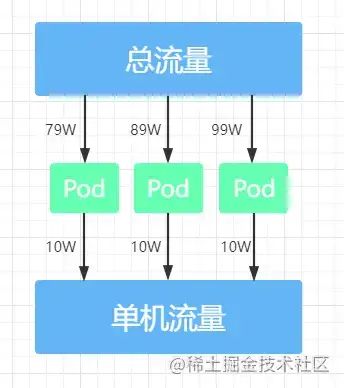
首先从外部来的流量是我们无法预估的,假设如上图我们有三个 服务器Pod,如果总流量来的非常大,那么这时我们通过计数器算法,给它设置一个很大的最大值;这个最大值只防小人不防君子,可能99%的项目都不会触发;这样经过 总流量的计数器削峰后,再到中心化的令牌桶限流:通过redis来实现,我们先做一个定时器每分钟都去令牌桶里写令牌,然后单机的流量每个进来后,都去redis里取令牌,有令牌就处理入库;没有令牌就把流量抛弃;这样子我们就实现了一个 单机的削峰+中心化的限流,两者一结合,就是解决了小流量应用限流后没流量的问题,以及控制了入库的数量均匀且稳定;
平台数据为什么需要 数据加工?
那么,为什么需要数据加工,以及数据加工需要做什么处理?
当我们的数据上报之后,因为 IP地址 是在服务端获取的嘛,所以服务端就需要有一个服务,去统一给请求数据中家加上 IP地址 以及 IP地址 解析后的归属地、运营商等信息;
根据业务需要,还可以加上服务端服务的版本号 等其余信息,方便后续做追踪;
这里就不展开描述~
平台数据为什么需要 数据清洗、聚合?
在一开始的整体架构设计中已经说明:
数据清洗是为了白名单、黑名单过滤等的业务需要,还有避免已关闭的应用数据继续入库;数据聚合是为了将相同信息的数据进行抽象聚合成issue,以便查询和追踪;
这样子假设后续我们需要在数据库查询:某一条错误,产生了几次,影响了几个人,错误率是多少,这样子可以不用再去 ES 中捞日志,而是在 MySQL 中直接查询即可;
并且,我们还可以将抽象聚合出来的 issue ,关联于公司的 缺陷平台(类bug管理平台) ,实现 issue追踪 、 直接自动贴bug到负责人头上 等业务功能;
平台数据如何进行 多维度追踪?
首先我们会对每一个用户(user),会去生成一个 用户id(uid ;并对每一次会话(session),生成一个 会话id(sid) ;
uid 和 sid 都是28位的随机ID,sid 和 uid 都在初始化时生成,不同的是,因为 uid 的生命周期只在一次会话之中(关闭页签之前),所以 sid 我们存放在 sessionStorage 中,而 uid 我们存放在 cookie 里,过期时间设置六个月;
每次SDK初始化时,都先去 cookie 和 sessionStorage 里取 uid 和 sid,如果取不到就重新生成一份;并且在每次数据上报时,都将这些 id 附带上去;
你如果有需要,还可以再搞一个登录id,由使用方传入,专门存放登录成功后的登录态ID;
这样一系列搞完之后,我们在第二篇文章《一文摸清前端监控实践要点(二)行为监控》[9]中收集了很多的行为数据,包括PV访问、路由跳转、http请求、click事件、自定义事件、甚至第三章的错误数据等等;这些种种零零散散的数据就可以被串联起来,得到新的分析价值;
因为 cookie 有极小的可能性被用户手动禁用,这种情况下
uid传null就可以了
代码错误如何进行 源码映射?
在第三篇文章中,我们通过解析错误堆栈,得到了错误的文件、行列号等信息,可以通过对 sourcemap 可以对源码进行映射,定位错误源码的位置;
大家可以跳转阅读相应的代码:一文摸清前端监控自研实践(三)错误监控 \- Source Map[10]
当然需要注意的是,在生产环境我们是不可以将 sourcemap 文件发布上线的,我们可以通过手动上传到监控平台的形式去进行错误的分析定位;
如何设计监控告警的维度?
首先,监控告警不是一个易事,在什么情况下,我们需要进行告警的推送?
我们先来了解两个概念:宏观告警 和 微观告警;
| key | 宏观告警 | 微观告警 |
|---|---|---|
| 告警依据 | 是否超出了阈值? | 是否有产生新的异常? |
| 关键指标 | 数量、比率 | 单个异常 |
| 比对方法 | 时间区间内的 异常数量、异常比率 | 新增的异常且异常uid未解决 |
宏观告警更加关注的是:一段时间区间内,新增异常的数量、比率是否超过了阈值;如果超过了那就进行告警;微观告警更加关注的是:是否有新增的、且未解决的异常;
我们团队这边目前做的都是微观告警;只要出现的新异常,它的 uid 是当前已激活的异常中全新的一个;那么就进行告警,通知大群、通知负责人、在缺陷平台上新建 bug 指派给负责人;
监控告警如何指派给代码提交者?
如上文提到,我们当发现新 bug 产生时,我们可以将这个 bug 指派给负责人;这里其实还可以做的更细致一点,我们可以做一个 处理人自动分配 的机制;
处理人自动分配,分配给谁呢?还记得我们在第三篇错误监控中,捕获错误时上报了错误的位置,也就是源码所在;那么我们只需要找到最近一次提交这行代码的人就可以了;
Git Blame
那么找出 出错行author 的原理其实就是 Git Blame ;这方面的文档很多,不了解的同学可以看一下 Git Blame[11];

看上图,指令其实很简单,
// git blame -L <n,m> <file>
// n是起始行,m是结束行,file是指定文件
// eg:
git blame -L 2,2 LICENSE
查询返回的结构是:
commitID (代码提交作者 提交时间 代码位于文件中的行数) 实际代码
这样子,我们就可以获取到具体的提交记录是哪次,并且提交者是谁;
利用 Gitlab Open-api 在服务端集成
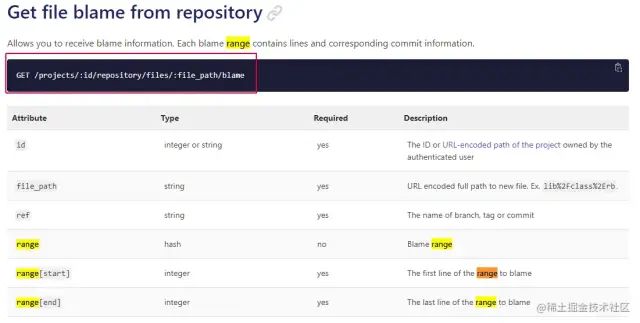
在 gitlab 文档[12] 中,详细说明了API的使用和参数方法;我们只需传入 range[start] 、 range[end] ,还有具体的 分支 和 文件名 ;我们就可以像下面这个官方给出的例子一样调用
curl --head --header "PRIVATE-TOKEN: <your_access_token>" "https://gitlab.example.com/api/v4/projects/13083/repository/files/path%2Fto%2Ffile.rb/blame?ref=master&range[start]=1&range[end]=2"
参考阅读
一文摸清前端监控实践要点(一)性能监控[13]
一文摸清前端监控实践要点(二)行为监控[14]
一文摸清前端监控实践要点(三)错误监控[15]
前端早早聊 李振:如何从 0 到 1 建设前端性能监控系统[16]
Git Blame[17]
Gitlab 查询 Blame[18]
参考资料
https://juejin.cn/post/7097157902862909471: https://juejin.cn/post/7097157902862909471
[2]https://juejin.cn/post/7098656658649251877: https://juejin.cn/post/7098656658649251877
[3]https://juejin.cn/post/7100841779854835719/: https://juejin.cn/post/7100841779854835719/
[4]https://juejin.cn/post/7108660942686126093: https://juejin.cn/post/7108660942686126093
[5]https://juejin.cn/post/7100841779854835719/: https://juejin.cn/post/7100841779854835719/
[6]https://developer.mozilla.org/zh-CN/docs/Web/API/Beacon_API: https://link.juejin.cn?target=https%3A%2F%2Fdeveloper.mozilla.org%2Fzh-CN%2Fdocs%2FWeb%2FAPI%2FBeacon_API
[7]https://developer.mozilla.org/zh-CN/docs/Web/API/Window/requestIdleCallback: https://link.juejin.cn?target=https%3A%2F%2Fdeveloper.mozilla.org%2Fzh-CN%2Fdocs%2FWeb%2FAPI%2FWindow%2FrequestIdleCallback
[8]https://www.zaozao.run/video/s8/s8-3: https://link.juejin.cn?target=https%3A%2F%2Fwww.zaozao.run%2Fvideo%2Fs8%2Fs8-3
[9]https://juejin.cn/post/7098656658649251877: https://juejin.cn/post/7098656658649251877
[10]https://juejin.cn/post/7100841779854835719#heading-24: https://juejin.cn/post/7100841779854835719#heading-24
[11]https://git-scm.com/docs/git-blame: https://link.juejin.cn?target=https%3A%2F%2Fgit-scm.com%2Fdocs%2Fgit-blame
[12]https://docs.gitlab.com/ee/api/repository_files.html#get-file-blame-from-repository: https://link.juejin.cn?target=https%3A%2F%2Fdocs.gitlab.com%2Fee%2Fapi%2Frepository_files.html%23get-file-blame-from-repository
[13]https://juejin.cn/post/7097157902862909471: https://juejin.cn/post/7097157902862909471
[14]https://juejin.cn/post/7098656658649251877: https://juejin.cn/post/7098656658649251877
[15]https://juejin.cn/post/7100841779854835719/: https://juejin.cn/post/7100841779854835719/
[16]https://www.zaozao.run/video/s8/s8-3: https://link.juejin.cn?target=https%3A%2F%2Fwww.zaozao.run%2Fvideo%2Fs8%2Fs8-3
[17]https://git-scm.com/docs/git-blame: https://link.juejin.cn?target=https%3A%2F%2Fgit-scm.com%2Fdocs%2Fgit-blame
[18]https://docs.gitlab.com/ee/api/repository_files.html#get-file-blame-from-repository: https://link.juejin.cn?target=https%3A%2F%2Fdocs.gitlab.com%2Fee%2Fapi%2Frepository_files.html%23get-file-blame-from-repository
关于本文:
来源:菜猫子neko
https://juejin.cn/post/7108660942686126093
祝 您:2022 年暴富!万事如意!
点赞和在看就是最大的支持, 比心❤️
比心❤️