
前端监控SDK开发分享
大厂技术 高级前端 Node进阶
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群
作者:子慕大诗人
原文:https://www.cnblogs.com/1wen/p/14417475.html
目录
前言
收集哪些数据
性能
错误
辅助信息
小结
客户端SDK(探针)相关原理和API
Web
微信小程序
编写测试用例
单元测试
流程测试
- 提供Web环境的方式
- Mock Web API的方式
结语
一、前言
随着前端的发展和被重视,慢慢的行业内对于前端监控系统的重视程度也在增加。这里不对为什么需要监控再做解释。那我们先直接说说需求。
对于中小型公司来说,可以直接使用三方的监控,比如自己搭建一套免费的sentry就可以捕获异常和上报事件,或者使用阿里云的ARMS,功能比较全面也并不会太贵。类似的开源系统或者付费系统还很多,都能满足我们一定的需求。
假如这个公司逐渐成长,已经成为一个中大型的公司,用户量、业务服务、公司整体架构全部都在升级,这样三方的监控系统可能就慢慢的出现一些不能满足需求的问题。比如企业内部各种系统之间的关系太独立和分散,不能使用内部的统一登陆、不能相互跳转,想要增加一些字段收集并不能很快得到支持等等。这些问题都会导致效率上不能满足企业发展要求。一个内部可控并且能高速响应企业需求的前端监控系统就显得很有必要。
我们在内部的前端监控系统上已经投入了一定的精力和时间,今天分享一下前端监控SDK部分的内容,主要三个方面:
收集哪些数据
客户端SDK(探针)及原理
编写测试用例
二、收集哪些数据
前端监控系统最核心的首要是收集客户端的相关数据,我们现在支持的客户端探针有:web、微信小程序、andriod和ios。它们主要收集如图以下信息:

2.1 性能
收集页面加载、静态资源、ajax接口等性能信息,指标有加载时间、http协议版本、响应体大小等,这是为业务整体质量提升提供数据支撑,解决慢查询问题等。
2.2 错误
收集js报错、静态资源加载错误、ajax接口加载错误,这些常规错误收集都很好理解。下面主要说明一下"业务接口错误(bussiness)":
客户端发送ajax请求后端业务接口,接口都会返回json数据结构,而其中一般都会有errorcode和message两个字段,errorcode为业务接口内部定义的状态码。正常的业务响应内部都会约定比如errorcode==0等,那如果不为0可能是一些异常问题或者可预见的异常问题,这种错误数据就是需要收集的。
由于不同团队或者接口可能约定都不一样,所以我们只会提供一个预设方法,预设方法会在ajax请求响应后调用,业务方自己根据约定和响应的json数据,在预设的方法中编写判断逻辑控制是否上报。像是下面这样:
errcodeReport(res) {
if (Object.prototype.toString.call(res) === '[object Object]' && res.hasOwnProperty('errcode') && res.errcode !== 0) {
return { isReport: true, errMsg: res.errmsg,code: res.errcode };
}
return { isReport: false };
}
2.3 辅助信息
除了上面两类硬指标数据,我们还需要很多其它的信息,比如:用户的访问轨迹、用户点击行为、用户ID、设备版本、设备型号、UV/UA标识、traceId等等。很多时候我们要解决的问题并不是那么简单直接就能排查出来,甚至我们需要前端监控和其它系统在某些情况下能够关联上,所以这些软指标信息同样很重要。
在这里专门解释一下traceId:
现在的后端服务都会使用APM(应用性能管理)系统,APM工具会在一次完整请求调用之初生成唯一的id,通常叫做traceId,它会记录整个请求过程服务端的链路细节。如果前端能够获取到它,就能通过它去后端APM系统中查询某次请求的日志信息。只要后端做好相关的配置,后端接口在响应客户端http请求时,可以把traceId返回给客户端,SDK便可以去收集ajax请求的traceId,这样前后端监控就能够关联上了。
2.4 小结
收集以上的信息并开发一套管理台,能够达到监控前端性能和异常错误的目的。想象一个场景,当我们收到监控系统的告警或者相关同事的问题反馈时,我们能打开管理台,首先查看到实时的错误,如果发现是js的代码导致的问题,我们能很快找到前端代码错误的地方。如果不是前端的错误,我们通过收集的业务接口错误发现是后端接口的问题,我们也能及时的通知后端同事,在什么时间哪个接口报出errorcode为xx的错误,并且我们还能通过traceId直接查到这次ajax请求的后端链路监控数据。如果实在不是明显就能排查到的问题,我们还能通过收集到的用户轨迹、设备信息和网络请求等数据,多方面的分析还原用户当时的场景,来辅助我们排查代码中的难以复现的bug或者兼容问题。
在以上这个场景中,我们能够提高前端排查问题的能力,甚至能辅助后端同学。在大部分时候,出现bug,很可能第一时间首先是找到前端做反馈,前端是排查问题的先头部队。当我们有这样的前端监控系统之后,不至于每次遇到问题手足无措,解决问题的时间也会快许多。
【具体字段一览】
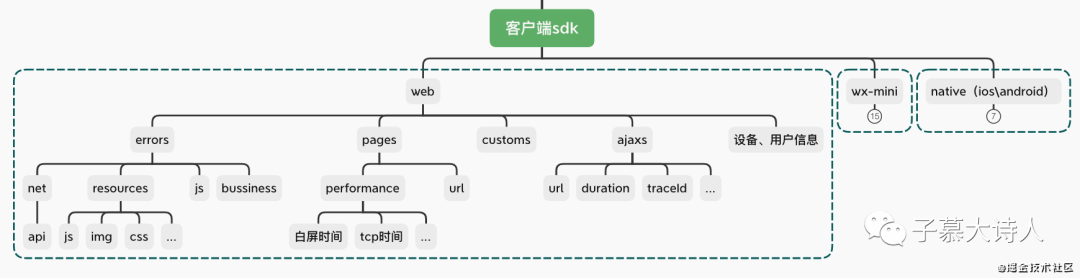
确定好了要收集哪些信息,接下来就需要去实现客户端SDK,它能够在业务项目中自动收集数据上报给服务端。
三、客户端SDK(探针)相关原理和API
所谓探针,是因为我们的SDK要依托于监控的前端项目的运行环境,在其运行环境的底层API中加入探针函数来收集信息,下面分享WEB和微信小程序SDK实现的主要原理和使用的API。
3.1 WEB
下图是SDK主要使用的Web API,通过这几个API我们就能分别获取到:页面性能信息、资源性能信息、ajax信息、错误信息。
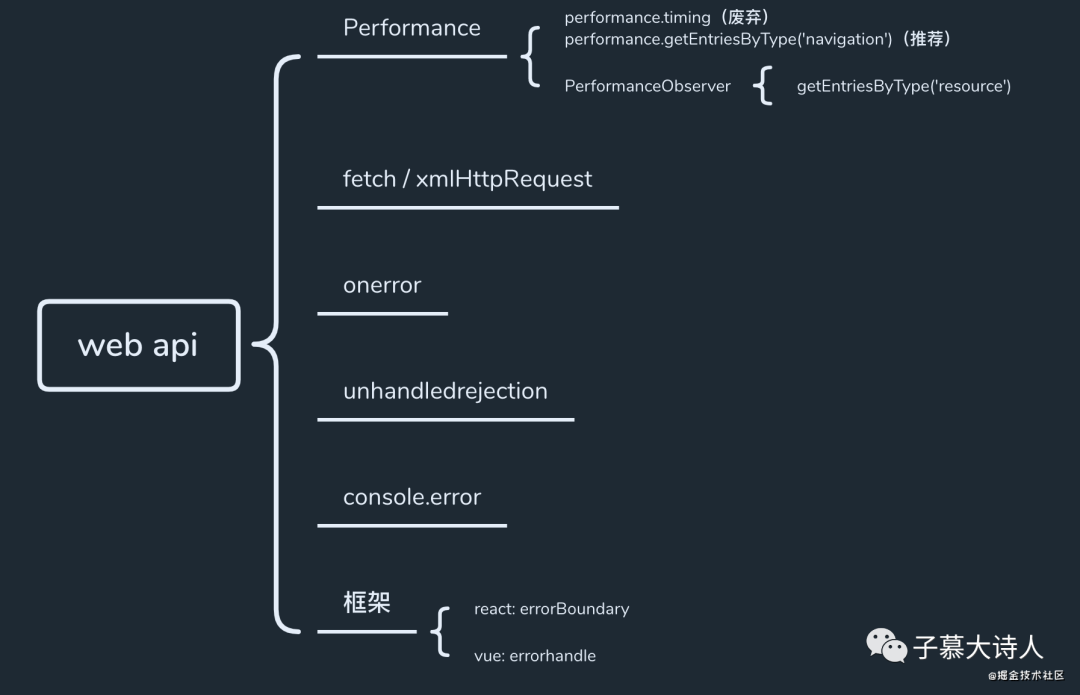
3.1.1 Performance
通过performance.timing可以拿到页面首次加载的性能数据,dns、tcp、白屏时间等,而在最新的标准中performance.timing已经被废弃,因此我们也改造为使用performance.getEntriesByType('navigation')。这里的白屏时间可能和实际真正的用户感官的白屏时间是有差异的,仅供参考。
通过new PerformanceObserver监听器,我们可以监听所有资源(css,script,img,ajax等)加载的性能数据:加载时间,响应大小,http协议版本(http1.1/http2)等。而后我们需要通过一个数组去管理资源性能数据,在完成数据上报后,清空数组。
3.1.2 fetch/xmlHttpRequest
由于浏览器并没有提供一个统一的API使我们能够收集到ajax请求和响应数据,并且不管我们是用axois还是使用其他的http请求库,他们都是基于fetch和xmlHttpRequest实现的。因此只能通过重写fetch和xmlHttpRequest,并在对应的函数和逻辑中插入自定义代码,来达到收集的目的。相关的文章很多,这里就不再细说了。
let _fetch = fetch;
window.fetch = function () {
// custom code
return _fetch
.apply(this, arguments)
.then((res) => {
// custom code
return res;
})
};
3.1.3 window.onerror | unhandledrejection | console.error | 以及框架自带的监听函数
最后这几个API都是收集js相关错误信息的。需要注意两个问题:
一是onerror会获取不到跨域的script错误,解决方案也很简单:为跨域的script标签设置crossorigin属性,并且需要静态服务器为当前资源设置CORS响应头。
二是代码压缩后的报错信息需要通过sourceMap文件解析出源代码对应的行列和错误信息,sourceMap本身是一种数据结构,存储了源代码和压缩代码的关系数据,通过解析库能够很轻松转换它们。但如何自动化管理和操作sourceMap文件才是前端监控系统核心需要解决的问题。这里就需要结合企业内部的静态资源发布系统和前端监控系统,来解决低效率的手动打包上传问题。
3.2 微信小程序
微信小程序底层使用js实现,有着它自己的一套生命周期,也提供了全局的API。通过重写它的部分全局函数和相关API我们能获取到:网络请求、错误信息、设备和版本信息等。由于微信小程序的加载流程是由微信APP控制的,js等资源也被微信内部托管,因此和web不同,我们没有办法获取到web中performance能获取到的页面和资源加载信息。下图是SDK主要使用的API
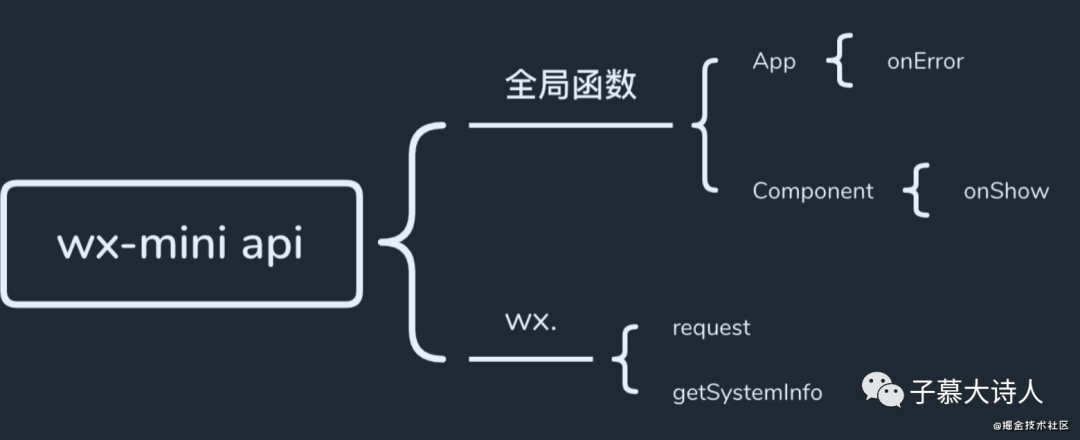
3.2.1 App和Component
通过重写全局的App函数,绑定onError方法监听错误,重写它的onShow方法执行小程序启动时SDK需要的逻辑。通过重写Component的onShow方法,可以在页面组件切换时执行我们的路径收集和执行上报等逻辑。
// SDK初始化函数
init(){
this.appMethod = App;
this.componentMethod = Component;
const ctx = this;
//重写微信小程序Component
Component = (opts) => {
overrideComponent(opts, ctx);
ctx.componentMethod(opts);
};
//重写微信小程序App
App = (app) => {
overrideApp(app, ctx);
ctx.appMethod(app);
};
}
//注意ctx是sdk的this
overrideComponent(opts, ctx) => {
const compOnShow = opts.methods.onShow;
opts.methods.onShow = function(){
// do something
//注意这里的this是实际调用方
compOnShow.apply(this, arguments)
}
})
overrideApp(app, ctx) => {
const _onError = app.onError || function () {};
const _onShow = app.onShow || function () {};
app.onError = function (err) {
reportError(err, ctx);
return _onError.apply(this, arguments);
};
app.onShow = function () {
//do something
return _onShow.apply(this, arguments);
};
})
3.2.2 重写wx.request
这里也是因为和 fetch/xmlHttpRequest 一样,并没有一个全局的API能让我们捕获到请求信息,因此只能通过重写wx.request来达到监听收集的功能。
const originRequest = wx.request;
const ctx = this;
//重写wx.request,增加中间逻辑
Object.defineProperty(wx, 'request', {
value: function () {
// sdk code
const _complete = config.complete || function (data) {};
config.complete = function (data) {
// sdk code
return _complete.apply(this, arguments);
};
return originRequest.apply(this, arguments);
}
})
当我们已经实现了SDK之后或者说在实现的过程中,就需要编写测试代码了,下面说说编写测试用例。
四、编写测试用例
SDK属于一个需要长期维护和更新的独立库,它被使用在很多业务项目中,要求更加稳定,当出现问题的时候,它的更新成本很高。需要经历:更新代码->发布新版本->业务方更新依赖版本,等流程,而如果在这个流程中,假如SDK又改出其它问题,那将会再启上述循环,业务同事肯定会被麻烦死。随着接入监控的系统增多,在迭代过程中改动任何的代码已经让人开始发慌,因为存在很多流程性的关联逻辑,害怕改出问题。在一次代码的重构和优化过程中,决心完善单元测试和流程测试。
4.1 单元测试
单元测试主要是对一些有明显输入输出的通用方法,比如SDK的utils中的常用方法,SDK的参数配置方法等。而对于监控SDK来说,更多的测试代码主要集中在流程测试,对于单元测试这里就不具体说明了。
4.2 流程测试
监控SDK在业务项目中初始化之后,主要是通过加入探针监听业务项目的运行状态而收集信息并进行上传的,它在大部分情况下并不是业务方调用什么就执行什么。比如我们页面初次加载,SDK在合适的时机会执行首次加载相关信息的收集并上传,那我们需要通过测试代码来模拟这个流程,保障上报的数据是预期的。
我们的SDK运行在浏览器环境中,在node环境下是不支持Web相关API的。因此我们需要让我们的测试代码在浏览器中运行,或者提供相关API的支持。下面我们将会介绍两种不同的方式,来支持我们的测试代码正常运行。
4.2.1 提供Web环境的方式
假如我们使用mocha或者jest作为测试框架,可以通过mocha自带的mocha.run方法在html中编写和执行我们的测试代码,并在浏览器中打开运行;jest-lite也可以支持让jest运行在浏览器中。
但有时候我们不想让它打开浏览器,希望在终端中就能完成测试代码运行,可以使用无头浏览器,在node中加载浏览器环境,比如phontomjs或者puppeteer。他们提供了相关的工具,比如mocha-phantomjs就能直接在终端中运行html执行测试流程。
基于写好的html测试文件,再使用mocha-phantomjs和phantomjs,以下是package.json的命令配置。
scripts:{
test: mocha-phantomjs -p ./node_modules/.bin/phantomjs /test/unit/index.html
}
phontomjs已经被废弃了,不被推荐使用。推荐puppeteer,相关的功能和类似工具都有支持。
举例说明:
以前有在WebSocket的代码库中使用过这种方式。因为依赖Web Api: WebSocket。需要通过new WebSocket(),来完成测试流程,而node环境下没有此API。于是使用mocha在html中写测试用例,如果希望全程使用终端跑测试,还可以配合使用mocha-phantomjs让测试的html文件可以在终端中执行而不用打开本地的网页运行。
当然其实完全可以直接在浏览器中打开html查看测试运行结果,而且phantomjs相关的依赖包非常大、安装也比较慢。但当时我们使用了持续继承服务travis,当我们的代码更新到远程仓库以后,travis将会启动多个独立容器并在终端中执行我们的测试文件,如果不使用mocha-phantomjs在终端中跑测试没有办法在travis中成功通过。
4.2.2 Mock Web API的方式
在这次完善监控SDK测试的过程中,尝试了另一种方式,全程使用Mock的方式。
上面的Web环境运行方式需要提供浏览器或者无头浏览器。但实际我们需要测试的代码并不是Web API,我们只是使用了它们。我们假定它们是稳定的,我们只需要在乎它的输入输出,如果它们内部出bug了,我们也是不能控制的,那是浏览器开发商的事情。因此我要做的事情仅仅是在node环境中模拟相关的Web API。
拿前面说到的WebSocket举例,因为node中不支持WebSocket,我们没有办法new WebSocket。那假如有完全模拟WebSocket的三方node库,我们就可以在node代码中,直接让执行环境支持WebSocket: const WebSocket = require('WebSocket')。这样我们就不需要在浏览器或者无头浏览器环境下运行了。
下面就具体拿我们的监控SDK中的fetch举例,是如何模拟流程测试的,总的来说要支持下面3个内容,
启动一个httpserver服务提供接口服务
引入三方库,让node支持fetch
node中手动模拟部分performance API
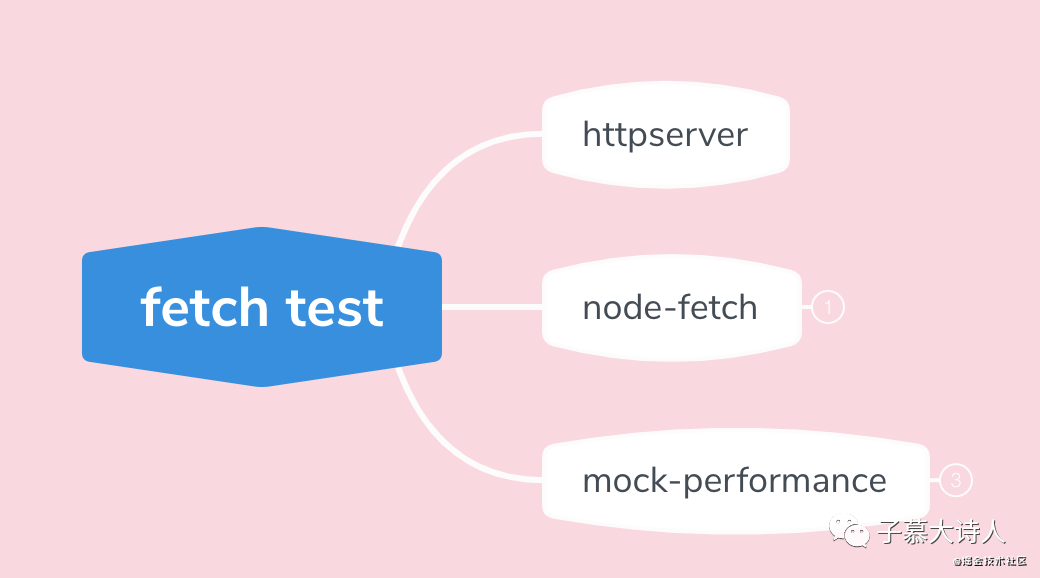
首先说明一下SDK中fetch的正常流程,当我们的SDK在业务项目中初始化了之后,SDK会重写fetch,于是业务项目中真正使用fetch做业务接口请求的时候,SDK就能通过之前重写的逻辑获取到http请求和响应信息,同时也会通过performance获取到fetch请求的性能信息,并进行上报。我们要写的测试代码,就是验证这个流程能够顺利完成。
(1)http server
因为是验证fetch完整流程,我们需要启动一个httpserver服务,提供接口来接收和响应这次fetch请求。
(2)mock fetch
node环境中支持fetch的话,我们可以直接使用三方库node-fetch,在执行环境的顶部,我们就可以提前定义fetch。
/** MockFetch.js */
import fetch from 'node-fetch';
window = {};
window.fetch = fetch;
global.fetch = fetch;
(3)mock performance
而performance就比较特殊一点,没有一个三方的库能够支持。对于fetch流程来说,我们如果要模拟performance,只需要模拟我们使用的PerformanceObserver,甚至一些入参和返回我们也可以只模拟我们需要的。下面的代码是PerformanceObserver的使用例子。在SDK中,我们主要也是使用这一段代码。
/** PerformanceObserver 使用实例 */
var observer = new PerformanceObserver(function(list, obj) {
var entries = list.getEntriesByType('resource');
for (var i=0; i < entries.length; i++) {
// Process "resource" events
}
});
observer.observe({entryTypes: ['resource']});
在浏览器内部performance底层会自动去监听资源请求,我们只是通过它提供PerformanceObserver去收集它的数据。本质上来说,主动收集的行为探针在performance内部实现。
下面我们模拟PerformanceObserver一部分功能,来支持我们需要的测试流程。定义window.PerformanceObserver为构造函数,把传入方法参数fn加入到数组中。mockPerformanceEntriesAdd 是我们需要手动调用的方法,当我们发起一次fetch,我们就手动调用一下此方法,把mock数据传入给注册的监听函数,这样就能使PerformanceObserver的实例接收到我们的mock数据,以此来模拟浏览器中performance内部的行为。
/** MockPerformance.js */
let observerCallbacks = [];
//模拟PerformanceObserver对象,添加资源监听队列
window.PerformanceObserver = function (fn) {
this.observe = function () {};
observerCallbacks.push(fn);
};
//手动触发模拟performance资源队列
window.mockPerformanceEntriesAdd = (resource) => {
observerCallbacks.forEach((cb) => {
cb({
getEntriesByType() {
return [resource];
},
});
});
};
通俗点举例来说,十号公司要给打工人银行卡发工资的,打工人的工资银行卡第二天就会被扣房贷。打工人最关心的保障正常扣房贷否则影响征信。本来打工人只需要关注银行是否成功完成扣款,但是打工人最近丢工作了公司不会打款到工资卡,所以只能拿积蓄卡给自己的扣贷银行卡转钱,让后续银行可以扣钱还房贷。公司就是浏览器performance底层,打工人给自己转钱就是mockPerformanceEntriesAdd,把公司发工资到银行卡替换为自己转钱进去,从被动接收变为主动执行。细品,你细品~
mockPerformanceEntriesAdd就是模拟浏览器的主动行为,入参是性能信息,我们可以直接写死(下方mockData)。看看测试代码
/** test/fetch.js */
import 'MockFetch.js';
import 'MockPerformance.js';
import webReportSdk from '../dist/monitorSDK';
//初始化监控sdk,sdk内部会重写fetch
const monitor = webReportSdk({
appId: 'appid_test',
});
const mockData = {
name: 'http://localhost:xx/api/getData',
entryType: 'resource',
startTime: 90427.23999964073,
duration: 272.06500014290214,
initiatorType: 'fetch',
nextHopProtocol: 'h2',
...
}
test('web api: fetch', () => {
//GET
const requestAddress = mockData.name;
fetch(requestAddress, {
method: 'GET',
});
//发送请求后,需要模拟浏览器performace数据监听
window.mockPerformanceEntriesAdd(mockData);
})
当mockPerformanceEntriesAdd执行的时候,SDK内部的PerformanceObserver便能收集到mock的性能信息了。( 这里注意,我们还需要启动一个httpserver的服务,服务提供http://localhost:xx/api/getData接口 )
当上面的测试代码运行的时候,SDK能够获取地址为http://localhost:xx/api/getData的fetch的请求、响应和性能信息,并且SDK也会发送一次fetch请求把收集的数据上报给后端服务。我们可以再次重写window.fetch,来拦截SDK的上报请求,就可以获取到请求内容,用请求内容来做预期测试判断
//再次重写fetch,拦截请求并跳过上报
const monitorFetch = window.fetch;
let reportData;
window.fetch = function () {
//sdk上报的数据我们会做一个type标记,避免SDK收集它自己发出的请求信息
if (arguments[1] && arguments[1].type === 'report-data') {
//获取请求内容
reportData = JSON.parse(arguments[1].body);
return Promise.resolve();
}
return monitorFetch.apply(this, arguments);
};
//省略中间代码
expect(reportData.resourceList[0].name).toEqual(mockData.name);
合并后的测试代码
/** test/fetch.js */
import 'MockFetch.js';
import 'MockPerformance.js';
import webReportSdk from '../dist/monitorSDK';
//初始化监控sdk,sdk内部会重写fetch
const monitor = webReportSdk({
appId: 'appid_test',
});
//再次重写fetch,拦截请求并跳过上报
const monitorFetch = window.fetch;
let reportData;
window.fetch = function () {
//sdk上报的数据我们会做一个type标记,避免SDK收集它自己发出的请求信息
if (arguments[1] && arguments[1].type === 'report-data') {
//获取请求内容
reportData = JSON.parse(arguments[1].body);
return Promise.resolve();
}
return monitorFetch.apply(this, arguments);
};
const mockData = {
name: 'xxx.com/api/getData',
entryType: 'resource',
startTime: 90427.23999964073,
duration: 272.06500014290214,
initiatorType: 'fetch',
nextHopProtocol: 'h2',
...
}
test('web api: fetch', (done) => {
//GET
const requestAddress = mockData.name;
fetch(requestAddress, {
method: 'GET',
});
//发送请求后,需要模拟浏览器performace数据监听
window.mockPerformanceEntriesAdd(mockData);
//需要一定延迟
setTimeout(()=>{
expect(reportData.resourceList[0].name).toEqual(mockData.name);
//more expect...
done()
},3000)
})

如上图所示,我们主要是以这样的模式进行SDK的流程测试和代码编写。有了测试代码后,能够在很大程度上保障代码维护迭代过程中的稳定性可控性,也能省去很多后期测试成本。
五、结语
以上分享是我们在做监控SDK时比较核心的这三个方面,还有很多其它的细节和实现,比如:如何节流、上报时机、数据合并、初始化配置等。开发迭代过程中,要避免客户端SDK或者后端服务因为迭代造成的兼容性问题。还比较重要的是要考虑后期数据库查询和存储方面的需求,收集、存储和查询才能完整的构成这套前端监控系统。
- End -
Node 社群
我组建了一个氛围特别好的 Node.js 社群,里面有很多 Node.js小伙伴,如果你对Node.js学习感兴趣的话(后续有计划也可以),我们可以一起进行Node.js相关的交流、学习、共建。下方加 考拉 好友回复「Node」即可。
如果你觉得这篇内容对你有帮助,我想请你帮我2个小忙:
1. 点个「在看」,让更多人也能看到这篇文章 2. 订阅官方博客 www.inode.club 让我们一起成长 点赞和在看就是最大的支持❤️