
搜狐智能媒体数据仓库,给了我什么启示?
点击蓝色“有关SQL”关注我哟
加个“星标”,天天与10000人一起快乐成长

图 | Lenis | 乌鲁木齐路夜拍
作为四大门户之一的搜狐,它的数据仓库会有哪些精彩之处?
说到搜狐,可能会暴露年龄。它是典型的综合性网站,门户新闻,视频娱乐,社交媒体,应有尽有。这么多应用,数据仓库团队会怎么玩,我特别好奇。
与美团外卖一样,和传统行业最大的区别,就是包含了实时性数据仓库的建设。要知道,实时性数据仓库,加上大数据量的分析计算,除了特别耗资源,架构设计还要着重保证低延时。
传统的数据仓库基建,基于关系型数据库,加上一些OLAP引擎,在聚合操作,宽带提炼比较耗时的任务下,很难做到实时产生输出。因此必须使用和RDBMS不一样的存储和计算引擎,才能够克服困难。这个时候,选型一个OLAP引擎就显得十分严肃。
MPP被证明优于Hadoop、Hive的架构,所以考察什么是MPP就成为重点。与美团一样,搜狐使用了Doris作为实时OLAP引擎。并且这次分享更多的指出数据治理的重要性和实践方法。搜狐自研的任务调度,元数据管理,数据质量管理和数据权限,都十分耀眼。
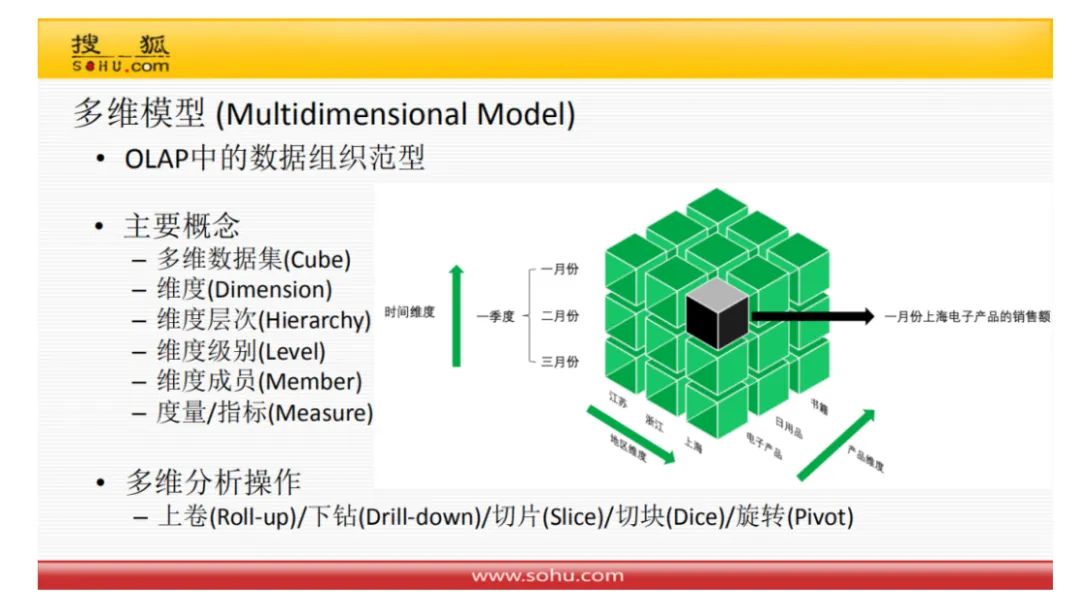
一张图解决所有多维数据模型的操作。
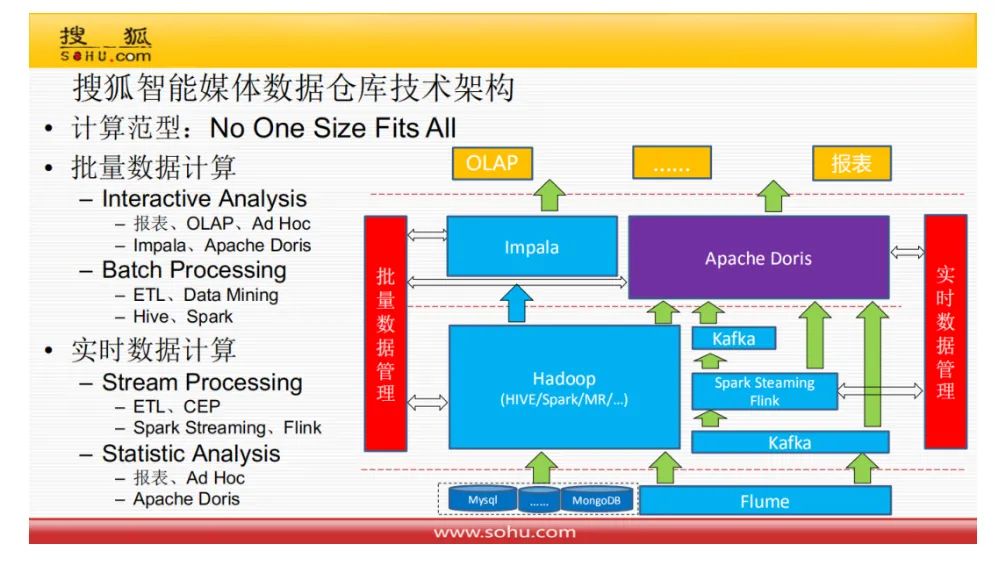
搜狐的数据仓库架构,采用了业界通用的架构,Lambda. 分为实时和批量两部分。
使用的存储和计算引擎,都和美团等十分类似,Hadoop/hive/Spark/Kylin/Doris
这篇搜狐的分享文,值得读的地方是,它对所有场景可用的工具,都做了对比。技术选型严谨,我们应该参考,但绝对不是直接搬过来就用Doris. 还是要根据自己的业务场景,去选择合适的引擎。毕竟每个引擎存在都有其存在的使用场景。

比如在选择 Kylin 这样的 MOLAP 引擎上,证据就不够充分。为什么 Keylin 不在其中使用,除了 MOLAP 与 ROLAP 的主流流向之外,还应该考虑到 Kylin 在处理时,会有极大的延迟,并且模型更改后,需要重头全量处理,所以实时性不够友好,因此弃选。这里,搜狐团队的分享,有些急躁了。
其他部分的选型对比,同样也仅做参考,分享中提到的技术点,不可全信。
接下来的分享,才是本文的重点。
数据管理
数据流,任务流都是数据仓库建设的基础概念。由此催生的数据质量管理,元数据管理,属数仓独有。
这一块没有项目的完整实践,一般不能清晰掌握。即使有机会接触了这样的项目,但缺少理念,也不会认识到,原来还有数据管理规范,这么个理论的东西存在。
就好比,很多前端开发会做报表,会写 D3.js,但不知道报表其本质是决策支持,隶属于数据仓库组件。缺少这样的理念,做出来的报表,徒增信息孤岛。
理论指导实践,实践反哺理论。良性发展,需要从开始就认知和承认,我们每个人的知识盲点。

从数据的流向性入手,数据流是由数据任务驱动的,有着明确的流动方向,从源数据系统流向处理层,流向加工层,流向应用层。每一次的流动,停顿都会有记录,整个过程中都有详细的元数据记录,且每一次的流动都要考虑数据的质量,最终通过质量验证,并且经过权限校验,才开放给外部调用者。
所以整个数据流的过程中,上面的4个管理组件都会有涉及,是数据仓库不可或缺的一部分。
数据任务管理
数据任务,其实在传统数据仓库中,我们称之为 ETL. 有任务流,也有数据流的概念。但在大数据背景下,这样的 ETL 工具,被称为数据任务管理。传统的ETL工具肯定不能在大数据背景下的数据任务流中,因此可以选择开源的数据仓库workflow管理系统,比如Azkaban, Oozie, Airflow 等。
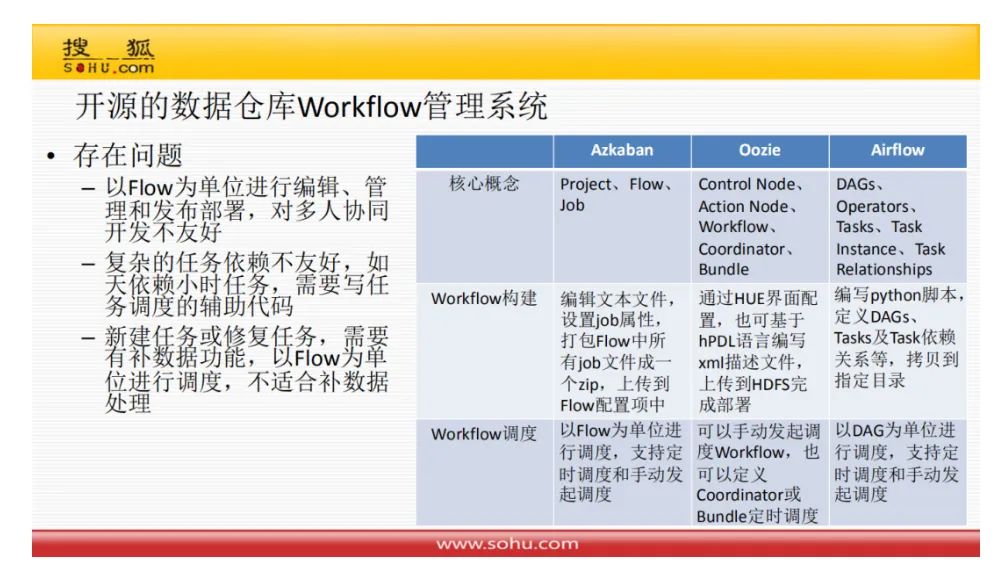
这又是一次选型。开源的东西是免费,但不具备专业性。某个行业用的很好,但用在自己的业务中,就捉襟见肘,需要自定义化,因此有了企业自研的需要。
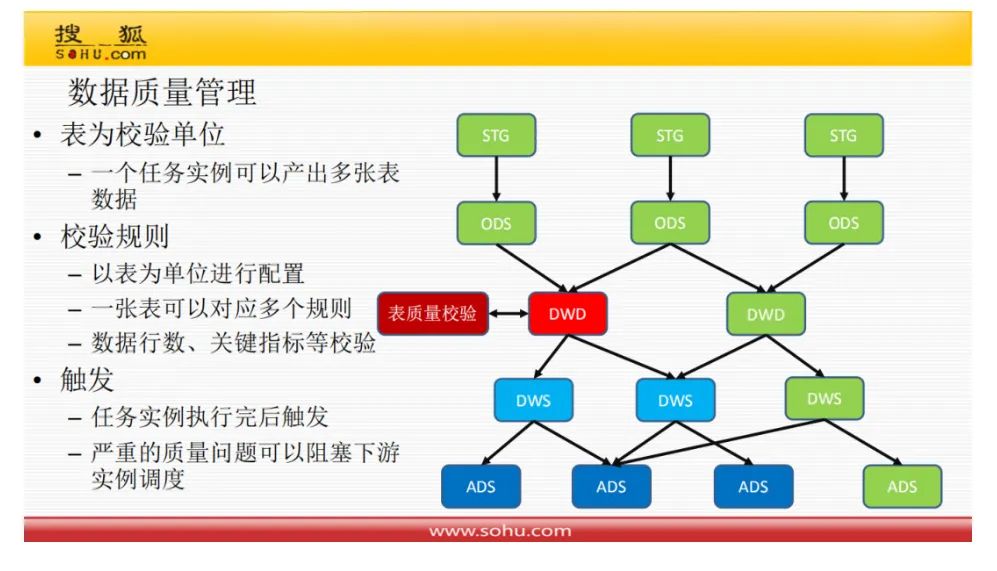
数据质量管理
数据质量检验也没有通用的软件可以使用,必须针对每张表(每种关系)自定义质量校验规则,不满足质量要求,则可以中断数据任务流的下一步执行。通常,质量检验规则就是一段对关系的测试代码,放在某个任务结束后执行。
数据元信息管理
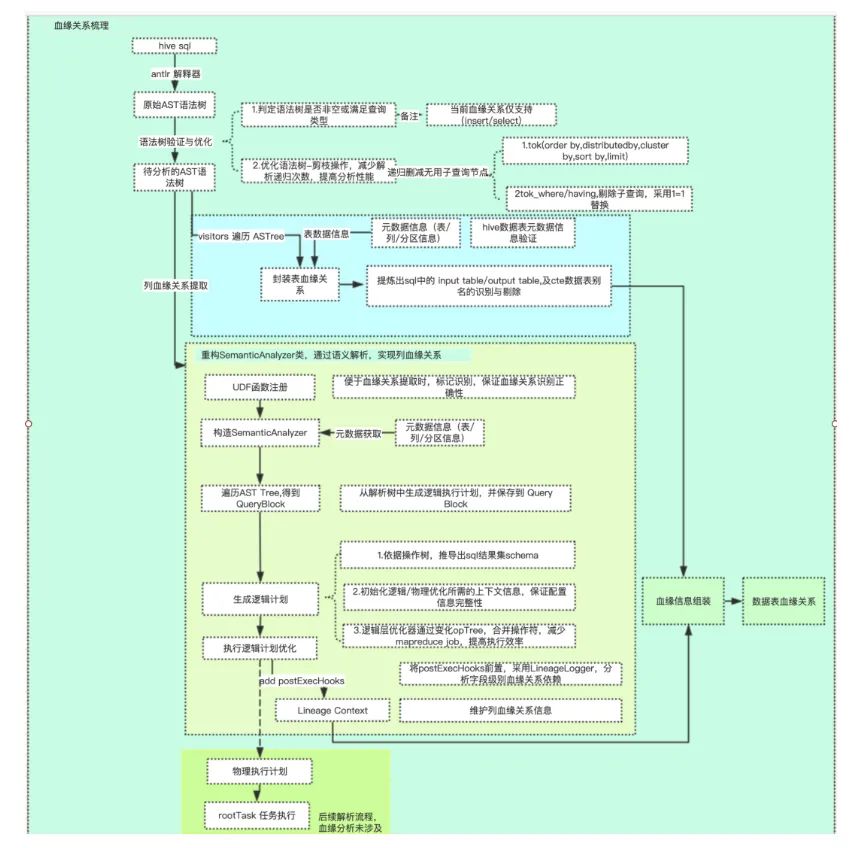
元信息,就是为了提供字段的血缘关系。而字段又是以表为基础,以分区为存储单元。所以这一系列的目的,最终就是为了我们点到哪里,就反应那里的数据上下游关系。比如点了某个字段,就知道这个字段起始字段从哪里来,最终落在哪个字段上。用一张图来表达,原信息管理的目的就是产生血缘关系图。
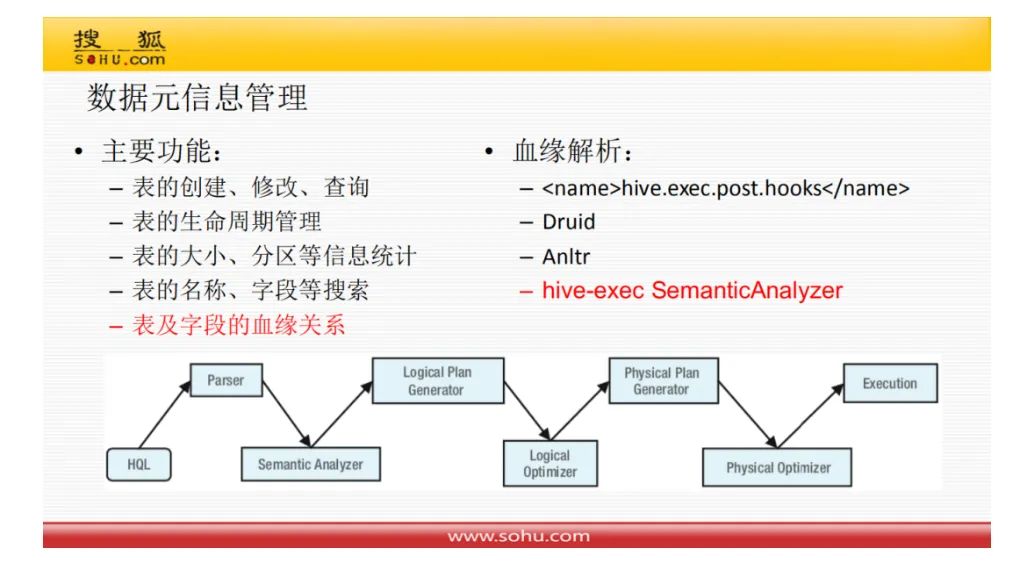
搜狐的血缘关系图,是非常有技术力的体现:
数据安全管理
即使对于开发人员,数据安全管控也非常有必要。
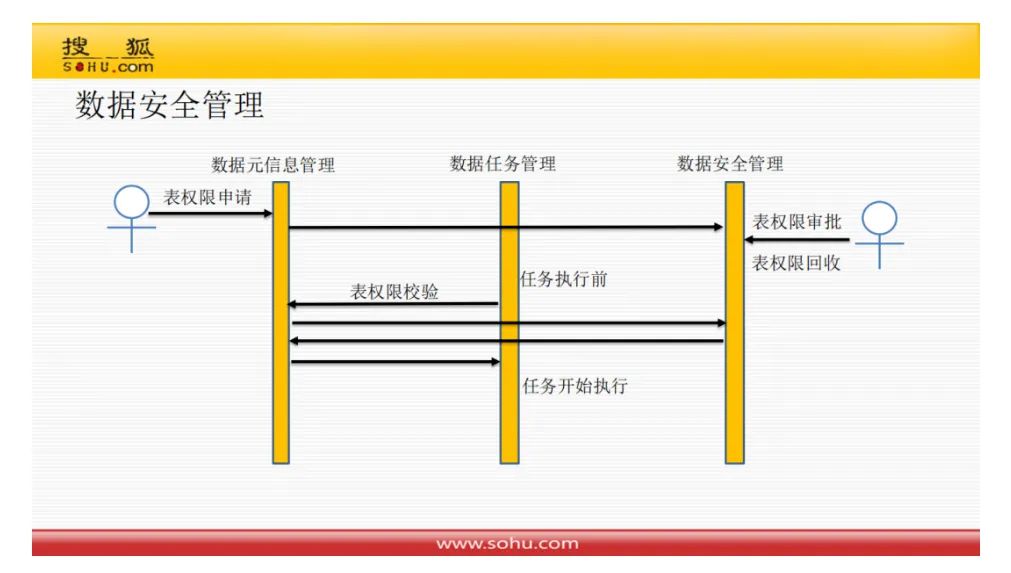
在搜狐,数据写权限可以彻底放开,但是读的权限控制的很严格(表级别)。不免觉得,如果没有表的读权限,为什么写权限却放开,万一把数据都给重写了呢。而且,字段级的读写控制,尤其读控制,并不难。对于读数的API,做好加密,就可以。
纵观全文,文章给我们提了醒。技术选型是关键,业界有成熟方案可以参考,但不能照搬。在数据管理方向上,搜狐做得很突出,几乎都自研。
不过,似乎这块管理不自研,也没有成熟的方案可以套用。这些产品,交给传统的SQL Boy/Girl 处理会很难,至于原因,大家都懂的,SQL写得溜,Java/.Net 可不一定。兄弟们,我们还有很长的路要走!
往期精彩: