
干货 | 如何利用Python处理JSON格式的数据,建议收藏!!!
JSON数据格式在我们的日常工作中经常会接触到,无论是做爬虫开发还是一般的数据分析处理,今天,小编就来分享一下当数据接口是JSON格式时,如何进行数据处理进行详细的介绍,内容分布如下
什么是JSON JSON模块的使用方法

JSON(JavaScript Object Notation, JS对象简谱)是一种轻量级的数据交换格式,通常是以键值对的方式呈现,其简洁和清晰的层次结构使得JSON成为理想的数据交换语言,而在Python中处理JSON格式的模块有json和pickle两个
json模块和pickle都提供了四个方法:dumps, dump, loads, load 序列化:将python的数据转换为json格式的字符串 反序列化:将json格式的字符串转换成python的数据类型
首先我们来看一下序列化是如何操作的,我们首先用json.dump()将字典写入json格式的文件中

能够进行类似操作的则是dataframe当中的to_json()方法,比方说

而当你分别打开这两个文件时,里面的内容分别是以键值对呈现的json数据。另外,我们看到有json.dumps()和json.dump(), 两者看着十分的相似,但是在功能上可是大相径庭,json.dump()进行的是对json文件的读写操作,就比如上述的例子中,我们将字典数据写入json的文件中用的就是json.dump,而json.dumps()则是聚焦于数据本身类型的转换,对数据的操作,比如

在反序列化的过程中,我们需要用到的则是json.load()和json.loads()方法,比如说
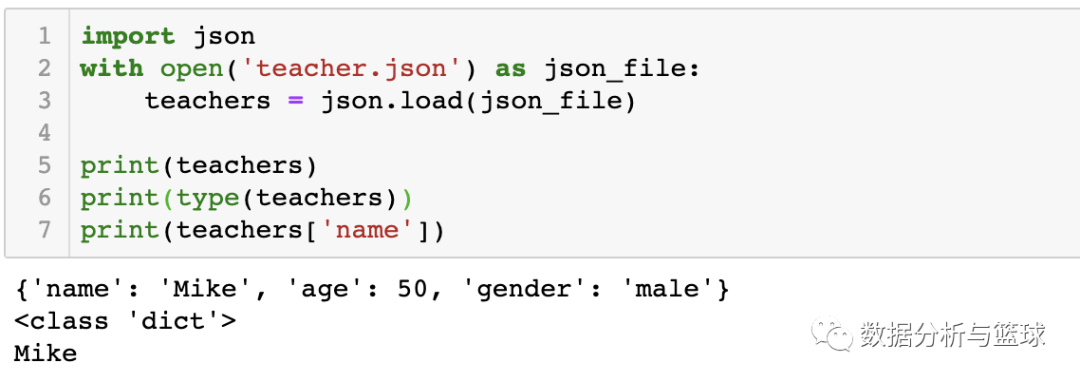
可以看到的是变量teachers的类型是字典类型,所以可以通过相应的方式来获取以及改变其中的数值以及格式,另外一种方法则是通过pandas模块中的read_json()方法,例如
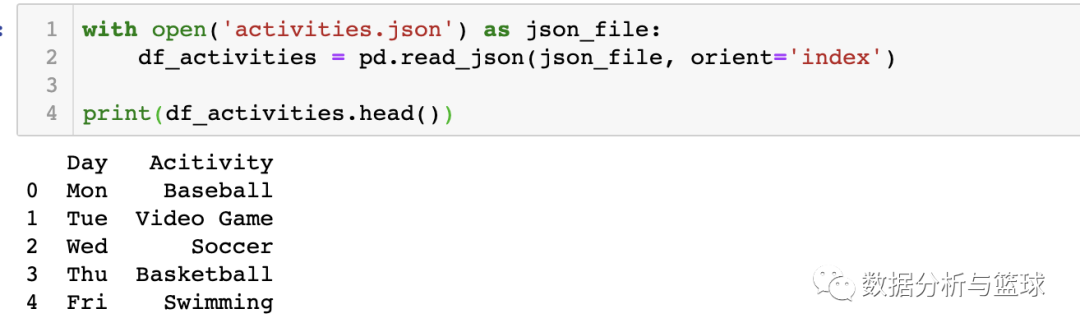
从上述的例子中可以看出,json.load()主要处理的是json格式的文件,而json.loads()主要是对JSON编码的字符串进行数据类型的转换,

本文主要是讲了序列化与反序列化的相关操作步骤,读者需要在其中留心的则是json.loads()与json.load(),以及json.dumps()和json.dump()之间的区别和使用场景,总的来说
json.loads():是将json格式的字符串(str)转换为字典类型(dict)的数据 json.dumps():返回来,是将字典类型(dict)的数据转换成json格式的字符串 json.load():用于读取json格式的文件,将文件中的数据转换为字典类型(dict) json.dump():主要用于存入json格式的文件,将字典类型转换为json形式的字符串