
FaceShifter:一秒换脸的人脸交换模型
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
如今,深度学习已近在图像合成、图像处理领域中取得惊人的成果。FaceShifter [1]便是其中之一,它是一种深度学习模型,可以非常先进的技术实现人脸交换。在本文中,我们将了解它是如何工作的。
01.问题描述
我们有一张源人脸图像Xₛ和一张目标人脸图像Xₜ,我们想要产生一个新的人脸图像Yₛₜ。它具有Xₜ图像中的属性(姿势,照明,眼镜等)和Xₛ图像中人的身份。图1总结了该问题陈述。现在,我们继续解释模型。
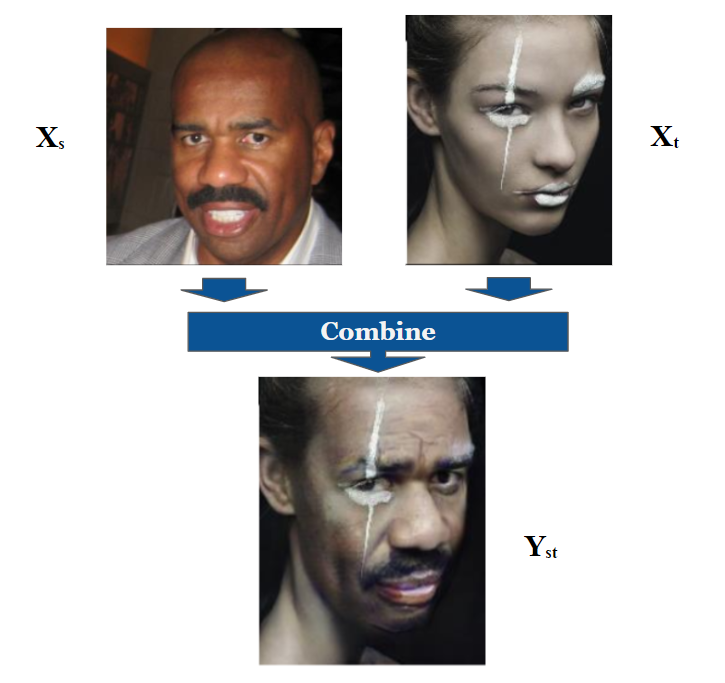
图1.换脸的问题描述,所示结果来自FaceShifter模型
02.FaceShifter模型
FaceShifter由AEI-Net和HEAR-Net的两个网络组成。AEI-Net产生初步的面部交换结果,而HEAR-Net对该输出进行细化。
AEI-Net
AEI-Net是“自适应嵌入集成网络”的缩写,AEI-Net包含3个子网:
1.身份编码器:与将Xₛ嵌入描述图像中人脸身份的空间有关的编码器。
2.多级属性编码器:一种与将X emb嵌入到空间中有关的编码器,该空间描述了交换面部时要保留的属性。
3.AAD生成器:一种生成器,它集成了前面两个子网的输出,以生成Xₜ的面与Xₛ的标识交换。
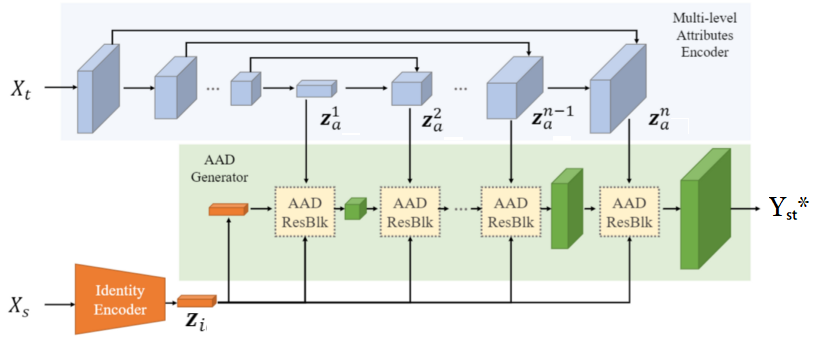
图2. AEI-Net的体系结构
身份编码器
该子网将源图像Xₛ投影到低维特征空间。输出只是一个矢量,我们将其称为zᵢ,如图3所示。此矢量编码Xₛ中人脸的身份,这意味着它应提取人类用来区分不同人的人脸的特征,例如眼睛的形状,眼睛与嘴巴之间的距离,嘴巴的弯曲度等。
使用了经过训练的人脸识别网络。这可以满足我们的要求,因为区分面部的网络必须提取与身份相关的特征。
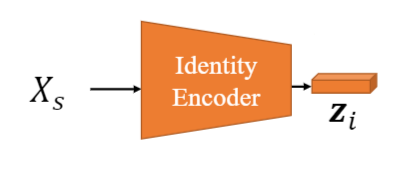
图3.身份网络
多级属性编码器
该子网对目标图像Xₜ进行编码。它产生多个向量,每个向量以不同的空间分辨率描述X的属性,称为zₐ。这里的属性表示目标图像中人脸的配置,例如人脸的姿势,轮廓,面部表情,发型,肤色,背景,场景照明等。它是具有类似U-Net结构的ConvNet,例如可以在图4中看到,其中输出矢量只是放大/解码部分中每个级别的特征图。但是这里的子网并没有经过预训练。
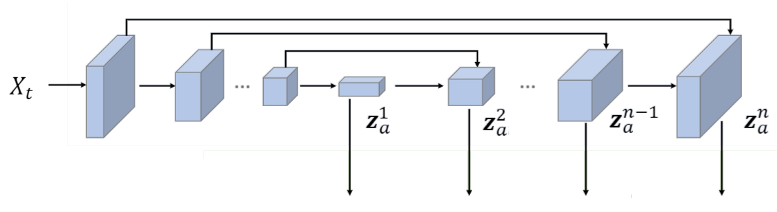
图4.多级属性编码器体系结构
我们需要将Xₜ表示为多个嵌入的形式,因为在单个空间分辨率下使用会导致生成需要交换面部的输出图像所需的信息丢失(即,我们想从X from保留太多精细的细节,使压缩图像不可行)。这在作者进行的烧蚀研究中很明显,他们尝试仅使用前3个zₐ嵌入而不是8个嵌入来表示Xₜ,从而导致图5所示的输出更加模糊。

图5.使用多个嵌入表示目标的效果。如果使用前3个zₐ嵌入,则压缩为输出
而当使用全部8个z 8嵌入时,则为AEI-Net
AADGenerator
AAD Generator是“ Adaptive Attentional Denormalization Generator”的缩写。它以提高的空间分辨率集成了前两个子网的输出,以生成AEI-Net的最终输出。它是通过堆叠如图6所示的称为AAD Resblock的新块来实现的。
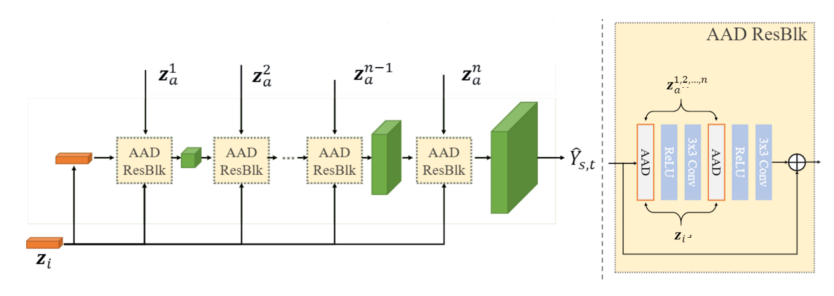
图6.左图为AAD Generator架构,右图为AAD ResBlock
此块的新块是AAD层。让我们将其分解为3部分,如图7所示。从较高的层次来看,第1部分告诉我们如何在属性方面将输入特征映射hᵢₙ编辑为更像Xₜ。具体来说,它输出两个张量,它们的大小与hᵢₙ相同。一个包含比例值,该比例值将与hᵢₙ中的每个单元相乘,另一个包含位移值。第1部分层的输入是属性向量之一。同样,第2部分将告诉我们如何将特征图hᵢₙ编辑为更像Xₛ。
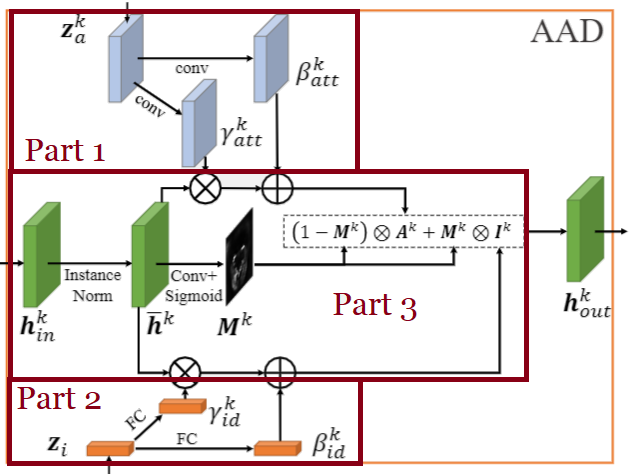
图7. AAD层的体系结构
第3部分的任务是选择每个单元/像素应听哪一部分(2或3)。例如,在与嘴相关的单元/像素处,该网络将告诉我们更多地收听第2部分,因为嘴与身份之间的关系更大。通过图8所示的实验以经验证明了这一点。

因此,AAD生成器将能够逐步构建最终图像,其中在给定身份和属性编码的情况下,AAD生成器将在每个步骤中确定最佳的方法来放大当前特征图。
现在,我们有了一个网络,即AEI-Net,可以嵌入Xₛ和Xₜ并以实现我们目标的方式将它们集成。我们将AEI-NetYₛₜ*的输出称为。
03.损失函数
一般而言,损失是我们希望网络做什么的数学公式。培训AEI-Net有4个损失:
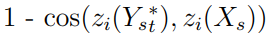
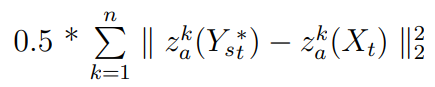

HEAR-Net
AEI-Net是一个可以进行面对面交换的完整网络。但是,在保留遮挡方面还不够好。具体来说,只要有一个项目遮挡了目标图像中应该出现在最终输出中的面部部分(例如眼镜,帽子,头发或手),AEI-Net就会将其删除。这些项目仍应保留,因为它与将要更改的身份无关。因此,作者实现了一个名为“启发式错误确认细化网络”的附加网络,该网络的工作就是恢复此类遮挡。
他们注意到,当他们将AEI-Net(即Xₛ和Xₛ)的输入设为相同的图像时,它仍然没有保留如图9所示的遮挡。

图9.当我们输入与Xₛ和Xₜ相同的图像时,AEI-Net的输出。注意头巾的链子如何在输出中丢失
因此,他们没有将其输入到HEAR-NetYₛₜ*和Xₜ中,而是将其设为Yₛₜ*&(Xₜ-Yₜₜ*),其中Xₜₜ和Xₜ是同一图像时,Yₜₜ*是AEI-Net的输出。这会将HEAR-Net指向未保留遮挡的像素。HEAR-Net可以在图10中看到。
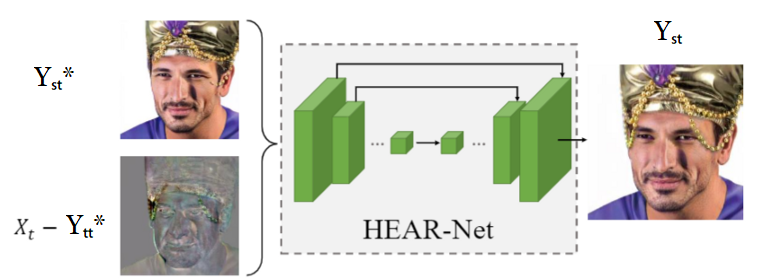
图10. HEAR-Net的体系结构
培训损失
HEAR-Net的损失为:
1.保留身份的损失:
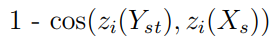
2.由于不改变Yₛₜ*而造成的损失:
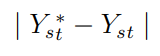
3.如果Xₛ和Xₜ是相同的图像,则HEAR-Net的输出应为Xₜ的事实造成了损失:
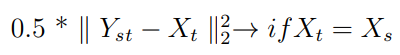
总损失是这些损失的总和。
结果
FaceShifter的结果是惊人的。在图11中,您可以找到在其所设计的数据集之外(即从野外获取)的图像上的泛化性能的一些示例。请注意,它如何能够在不同的恶劣条件下正常工作。

图11.结果证明了FaceShifter的出色性能
参考文献
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~