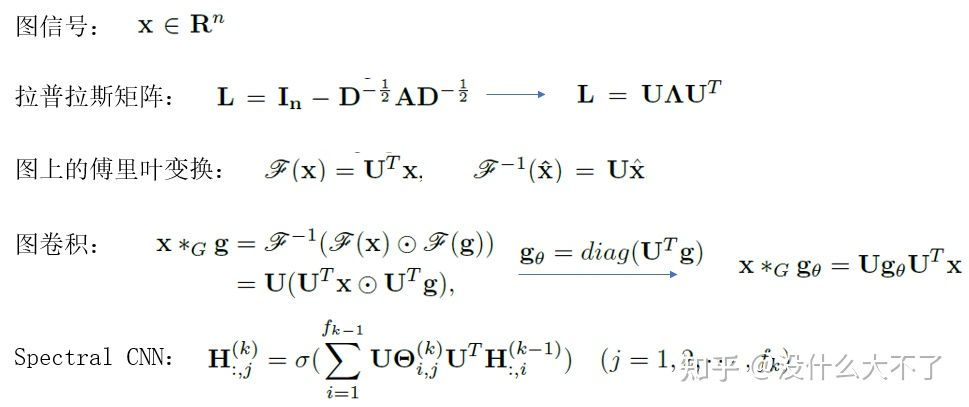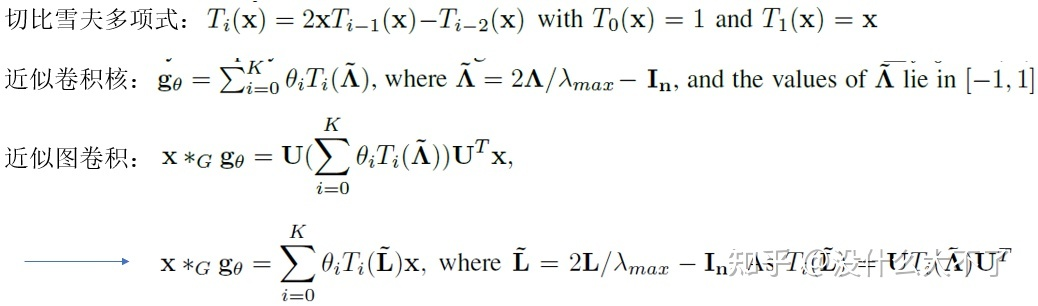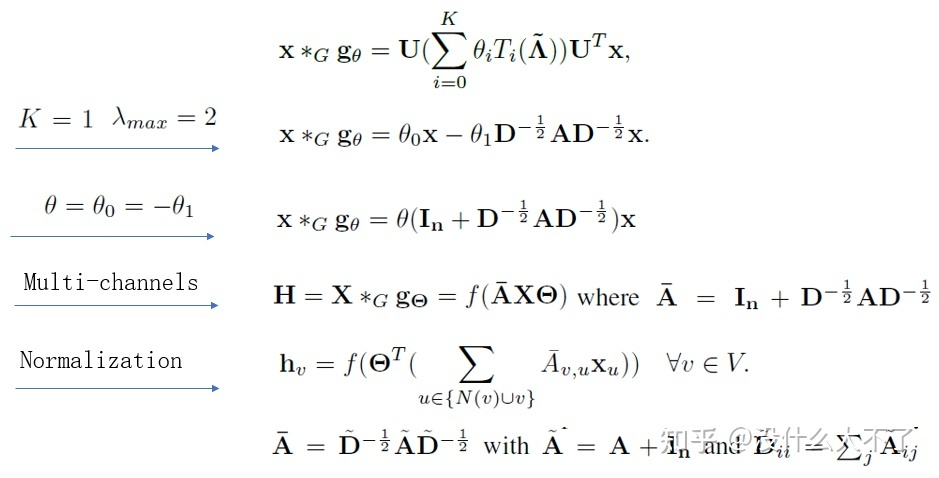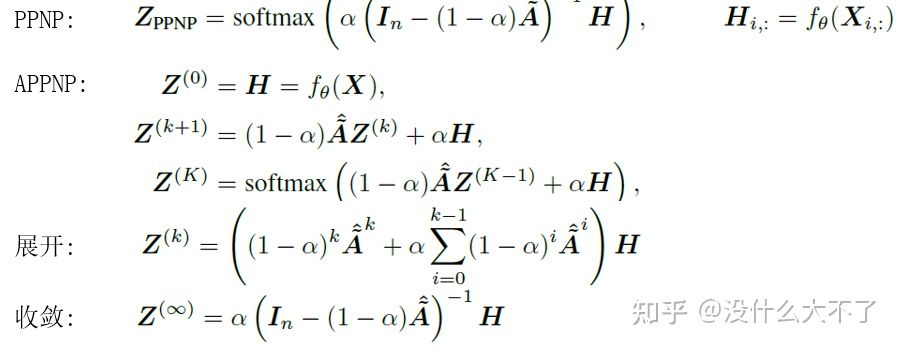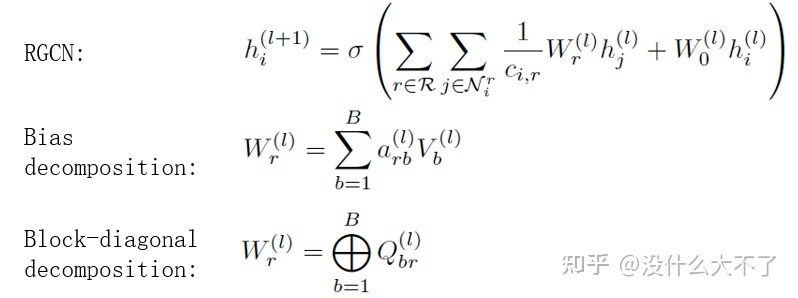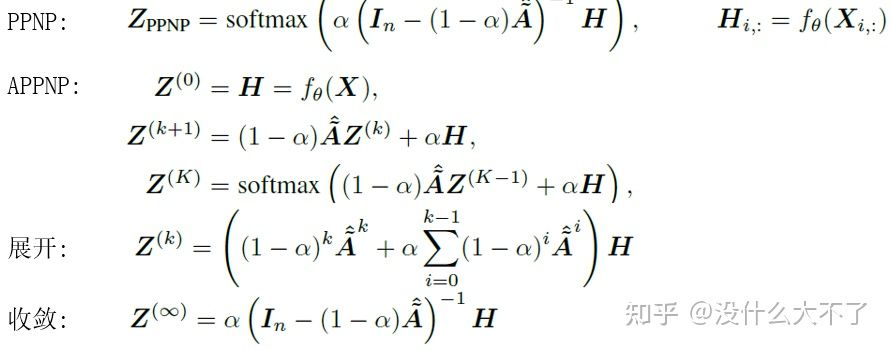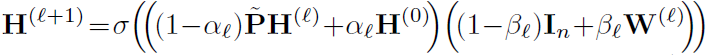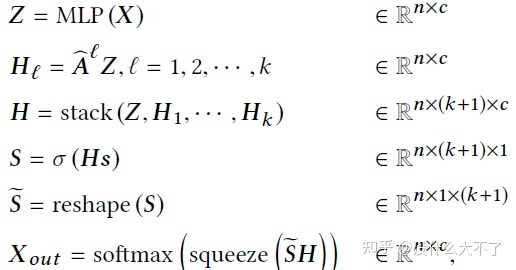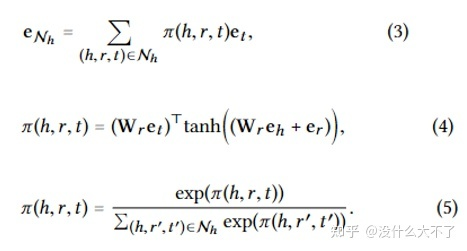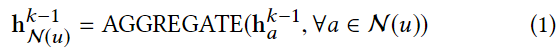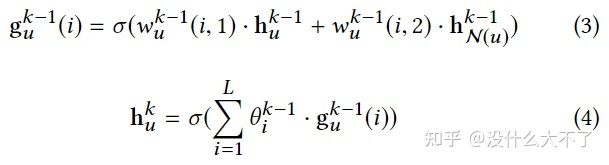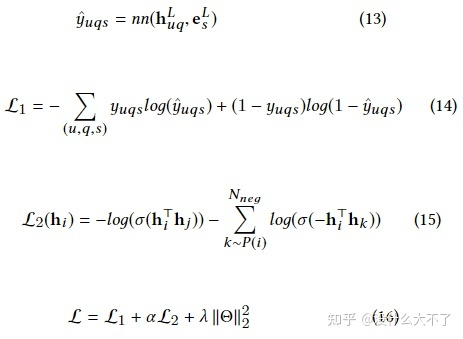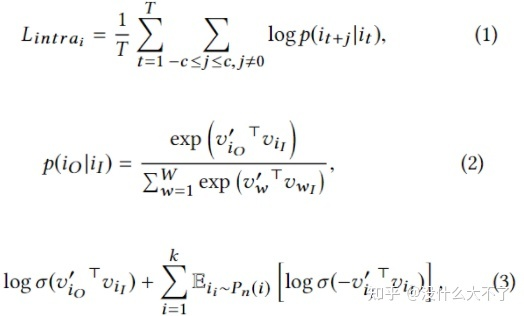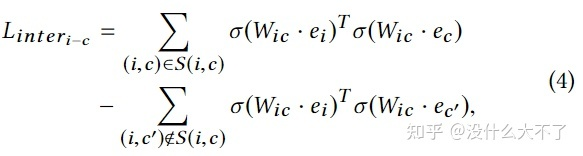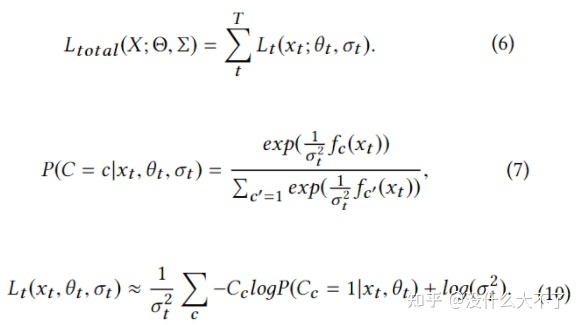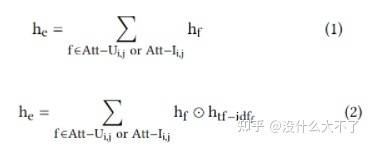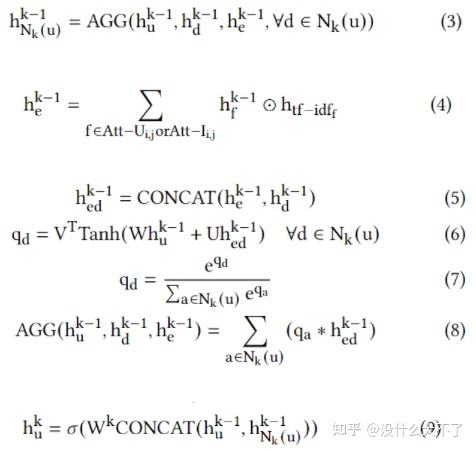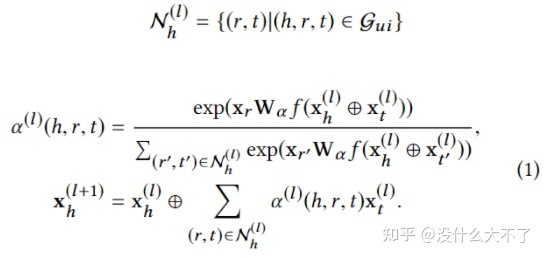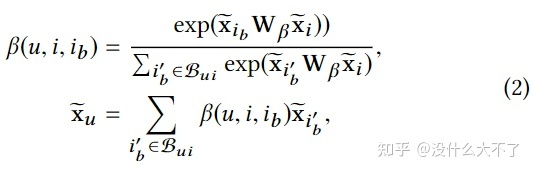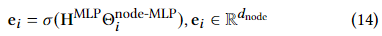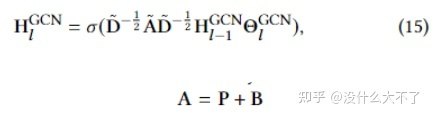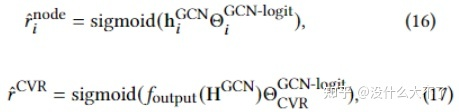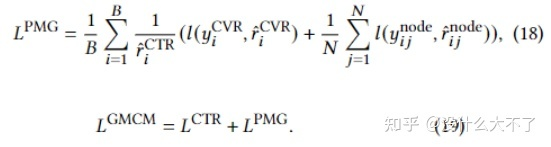本文约20000字 15分钟
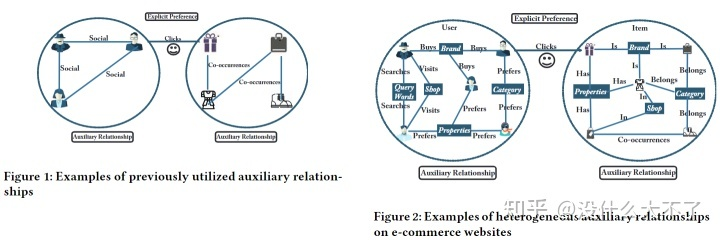
本文介绍了一些企业关于业务场景的大规模数据集的文章。 图神经网络是近年来很火的一个研究方向,在生物化学,推荐系统,自然语言处理等领域都得到了广泛应用。其中图神经网络在推荐系统的应用方面,已有几篇综述[1][2][3]做过详细的归纳总结。但是让人感到美中不足的是,综述中总结的多是学术型工作,偏向于GNN模型上的微调,部分工作其实就是将上游的SGC[4],GrapSage[5],JKNet[6]等模型在几个祖传玩具数据集上刷一下结果讲一个故事,很少关心模型的扩展性,也很少关心图的构建,特征处理,线上打分等不可或缺的环节。 因此本文选取了一些近几年阿里,腾讯,京东,华为等企业在KDD,SIGIR,CIKM等会议发表的文章,这些工作的实验至少是在真实业务场景的大规模数据集(千万级或亿级)上进行的,部分工作也成功在线上AB实验中取得了一些效果。全文分为三部分,第一部分简单介绍涉及较多的几个GNN研究方向,包括Deeper GNN(GNN加深),Scalable GNN(大图训练),Heterogeneous GNN(异构GNN);第二部分从几个不同的角度总结选取的文章,包括应用阶段,图的构建,特征使用,采样方法,模型结构;第三部分会逐篇介绍这些工作的重点内容。 链接:
https://zhuanlan.zhihu.com/p/423342532 1. GNN介绍
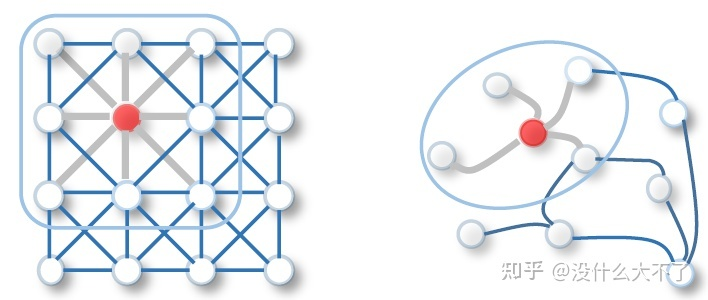
不同于传统的MLP,CNN,RNN等模型,GNN可以建模邻居顺序与数量不定的非欧式数据,常被用来处理结点分类,链接预测,图分类等任务。可以从两个角度理解GNN,谱图卷积与消息传递,今年我们在ICML的工作则是从迭代算法求解目标函数的角度解释GNN[7],同时在该理论框架内还能解释并解决过平滑,边的不确定性等问题。针对不同类型的任务,不同类型的图数据(异质图,动态图,异构图)等,存在许多特定的GNN模型,此外,还有图的池化,图预训练,图自监督等方向,相关的内容可以参考综述[8]。第一小节会简单介绍一些基础通用且有代表性的GNN模型,后三小节分别介绍Deeper GNN,Scalable GNN和Heterogeneous GNN三个方向,这些都是在将图神经网络应用到推荐系统时经常涉及的知识。最后一节谈谈个人对图神经网络的优势的理解。 1.1 Common GNN
Spectral CNN[9]:利用拉普拉斯矩阵定义了图上的卷积算子,其特点如下: 参数的量级是O(n),与结点数量正相关,难以扩展到大图。
Spectral CNN ChebNet[10]:利用切比雪夫多项式近似,降低了计算量和参数量,其特点如下:
GCN[11]:进一步简化了ChebNet,将谱图卷积与消息传递联系起来,其层级结构便于和深度学习结合。 SGC[4]:解耦了消息传递和特征变换, [公式] 部分可以预计算,简化后仍然可以在大多数数据集上取得和GCN相当的结果。 GAT[12]:将注意力机制引入GCN,建模了邻居结点的重要性差异,增强了模型的表达能力。 一方面,将消息传递框架范式化,分为Aggregate(聚合邻居)和Concat(融合自身)两个步骤。
另一方面,提出了一种简单有效的邻居采样方法,可以在大图上进行Mini-Batch训练,并且当有新的结点加入时,不需要在全图上聚合邻居,也不需要重新训练模型,可以用训练好的模型直接推断。
PPNP[13]:同样采用消息传递和特征变换分离的结构,并基于个性化PageRank改进消息传递,使模型可以平衡局部和全局信息。 RGCN[14]:对于不同类型的边对应的邻居结点采用不同的参数矩阵从而建模边的异构性。当边的类型很多时,参数也会变得很多,容易造成过拟合,并且不易训练,需要对参数进行规约,使用了一下两种方式: Bias decomposition(定义一组基向量)不仅可以减少参数量,同时对于那些样本较少的边也能得到充分学习(参数共享)。 Block-diagnoal decomposition只能减少参数量,实验下来效果也不如Bias decomposition。
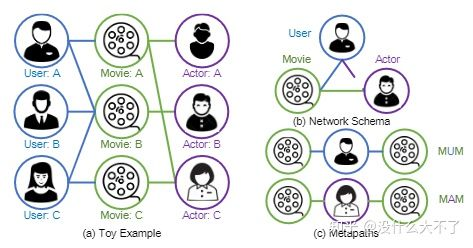
HAN[15]:将GAT扩展到了异构图上,不仅考虑了不同邻居结点的重要性差异,也考虑了不同语义的meta-path的重要性差异。 对于邻居结点的重要性,例如,考虑meta-path:Paper-Author-Paper以及结点分类任务,Paper A、C是数据库算法论文,Paper B是图神经网络论文,它们都是Author A的发表的文章,即PaperB、C都是Paper A的邻居,但是在聚合时显然Paper C与Paper A更相关,需要给与更大的权重。 对于meta-path的重要性,例如,考虑meta-path:Paper-Author-Paper以及Paper-Institution-Paper,通常同一个作者发表的文章,比同一个机构产出的文章更相关。
1.2 Deeper GNN
1.2.1 问题背景
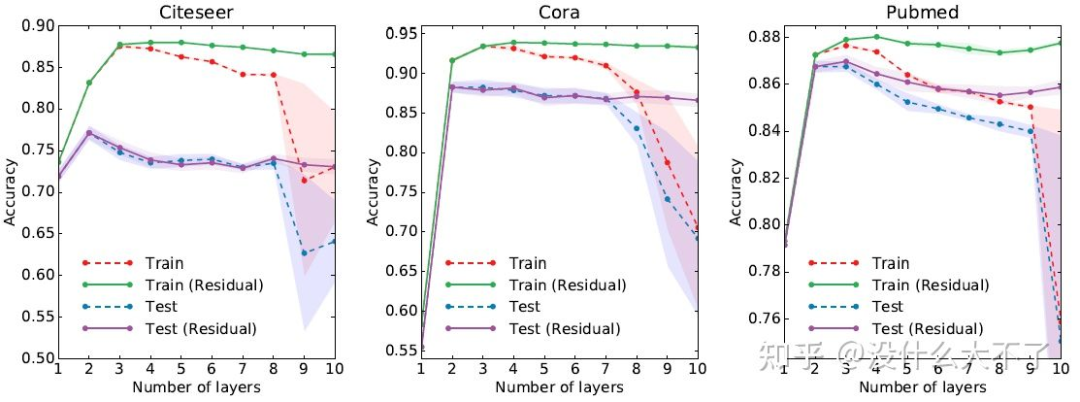
在GCN的实验中发现[11],一般2-3层的GCN可以取得最好的性能,继续增加层数GCN的性能会开始下降,达到8层以上会发生大幅度的下降。 1.2.2 理论分析
研究者证明了,随着SGC(不考虑层间的非线性)层数的加深,所有结点会收敛到同一个表征(简单的线性代数知识可证)[16]。直观上看,一个K层的SGC相当于聚合了K-Hop的邻居特征,当K大于或等于图的直径时,每个结点都聚合了整张图上所有结点的特征,从而每个结点都会收敛到同一个表征,结点之间自然会变得难以分辨。该现象被称为过平滑问题。 也有人证明了,随着GCN(考虑层间的非线性)层数的加深,所有结点的表征会收敛到同一个子空间[17]。 也有工作表示,消息传递和特征变换的耦合才是阻碍GCN加深的主要原因,不过并没有从理论上证明只是通过实验进行了验证[18]。 1.2.3 个人吐槽
实际上不考虑层之间的非线性时,不断加深SGC的层数甚至达到80层,只要给予模型更多的Epoch训练,整体上最终结果并不会有什么下降,这与很多论文里报告的SGC加深到10层以上效果骤降根本不符合。随着层数的增加,所有结点确实会收敛到同一个表征,然而这需要非常深,只要计算机底层表示的精度能够区分结点的差异,SGC的效果就不会有什么下降,无非是模型需要更多Epoch训练收敛。感兴趣的同学可以实验验证一下。 1.2.4 加深意义
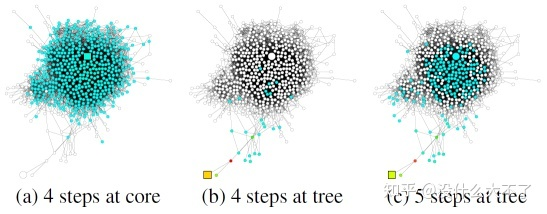
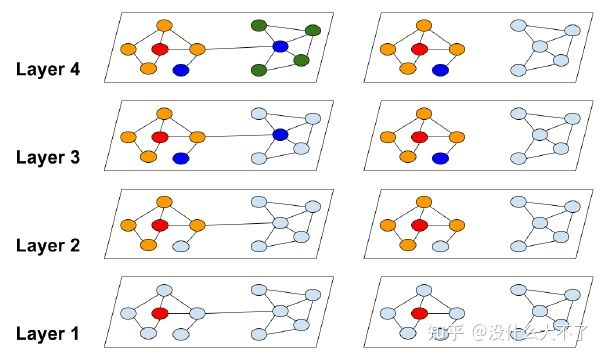
既然2-3层的效果最好,为什么还非要加深呢?这个问题不少工作都不太关心,它们的实验结果也很一般,只是缓解了加深过程的下降,并没有带来什么额外的收益。一种说法是,加深可以增强模型的表达能力(真是个万能理由),就像CNN那样通过加深提升效果。比较靠谱的两种说法是,一是加深可以学习更高阶的邻居信息,这也是不少GNN4Rec工作提到的,高阶信息蕴含了多跳的关联。JKNet中细致分析了中心结点和边缘结点的情况,如下图所示,边缘结点的邻居非常稀疏,需要加深获取更大范围的邻居信息。二是对于半监督结点分类任务来说,通过加深GCN建立长距离的依赖,可以将带标签结点的Label信息传播给更多结点。 1.2.5 代表工作
Deeper GNN的许多工作,只是缓解了加深的性能下降,并没有通过加深带来正向收益。以下是几个确实可以通过加深提升模型效果的工作。整体上看,比较有效的方法都是在以不同的方式组合不同范围的邻居信息,类似于Inception组合不同的感受野。PPNP[13]相当于引入了先验“近距离的邻居更重要,并且邻居的重要性随距离指数衰减”,DAGNN[19]则是通过不同Hop的聚合结果去学习潜在的重要性分布。 JKNet[6]:GCN的第K层包含了K-Hop范围的邻居信息,只使用最后一层的输出存在过平滑问题,因此JKNet保留了每一层的输出结果,最后综合融合不同范围的邻居信息。 PPNP[13]:采用消息传递和特征变换分离的结构,并基于个性化PageRank改进消息传递,使模型可以平衡局部和全局信息。 GCNII[20]:除了使用个性化PageRank改进消息传递,还引入了Residual Connections保持恒等映射的能力。 DAGNN[19]:自适应地学习不同范围的邻居信息的重要性。 1.3 Scalable GNN
1.3.1 问题背景
一方面,GCN在设计之初其卷积操作是在全图上进行的,在每一层对于所有结点聚合1阶邻居并融入自身表征,这样第K层的输出表征就包含了K阶邻居的信息。另一方面,图数据不同于其他数据集,结点之间存在边这种关联,无法直接通过随机采样进行Mini-Batch训练。因此GNN的许多模型无法直接扩展到大图上,然而真实业务场景中的图数据往往都是亿级别的。该章节介绍一些大图上训练GNN的方法,主要分为基于采样的方法和基于预处理的方法。 1.3.2 基于采样的方法
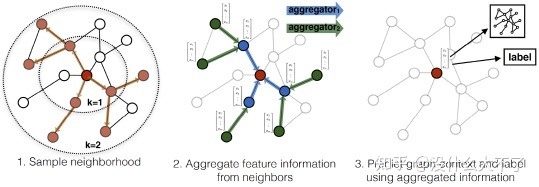
基于采样的方法可以分为三小类,Node-Wise Sampling,Layer-Wise Sampling和Subgraph-Wise Sampling。其中Node-Wise Sampling是一种比较通用有效的方法,在GNN4Rec方向中应用得最多;Layer-Wise Sampling其实就是一种弱化地Node-Wise Sampling,效果不咋地意义不大;Subgraph-Wise Sampling比较受限于场景,这一点在后面总结GNN4Rec工作时会提到。 Node-Wise Sampling[5]:由GraphSage首次提出,首先随机采样一个batch的root结点,接着从root结点出发迭代地采样1-K阶邻居,在训练时则迭代地聚合K-1阶邻居,最终得到每个root结点融合了K-Hop邻居信息的表征。这种方法主要存在以下几个缺点:
Layer-Wise Sampling[21]:由FastGCN首次提出,对于每一层都采样固定数量的结点,最终采样的结点数量与层数成线性关系;同时分析了采样带来的偏差与方差(做了大量简化),确保采样方法尽可能无偏有效。但是,该方法采样到的结点连接非常稀疏,不利于进行有效地消息传递,实际上实验效果也确实比较差。 Subgraph-Wise Sampling[22]:由ClusterGNN首次提出,首先用图划分算法(Metis等)将原图划分为一些子图,这些子图具有“高内聚,低耦合”的特点,接着在每个Batch随机采样一个子图(或多个子图合并为更大的子图从而降低方差),在该子图上训练完全的GCN。GraphSAINT进一步考虑了子图采样的偏差,通过两个正则化系数来修正子图采样给“邻居聚合”与“损失函数”带来的偏差,不过从之前个人复现的情况来看[23],GraphSAINT的实验结果主要是靠论文中没有提到的代码中的一系列Trick。 1.3.3 基于预处理的方法
基于预处理的方法是针对一类特定的GNN模型设计的,不具有通用性,这类模型将消息传递与特征变换解耦,对于消息传递部分可以预计算(例如SGC,PPNP,SIGN[24]),最后退化为数据预处理+MLP(也可以是其他模型),而MLP部分是可以直接随机采样做Mini-Batch训练的。特别地,对于PPNP,迭代计算的方式复杂度还是挺高的,因此可以进一步使用传统的Push算法[25]或蒙特卡罗算法[26]近似计算。 1.4 Heterogeneous GNN
1.4.1 问题背景
现实场景中大多是异构图,结点类型和边类型是多样的,例如,在电商场景,结点可以是Query,Item,Shop,User等,边类型可以是点击,收藏,成交等,GCN,GAT等模型无法建模这样的异构性:一方面,不同类型的结点的Embedding维度就没法对齐;另一方面,不同类型的结点的Embedding位于不同的语义空间。这限制了模型做特征融合和Attention计算。以下会介绍几个比较典型的异构GNN模型,它们都是通过Node or Edge Type-Specific Transformation来建模结点或边的异构性。不过KDD 2021[27]一篇工作通过实验比较发现,对异构性的建模带来的提升十分有限,该方向的工作大多存在不公平比较的问题,实际上只使用简单的GCN或GAT就能取得非常好的效果,吊打一堆所谓的SOTA Heterogeneous GNN。最近也有在做异构图建模的工作,业务场景是手淘的下拉推荐(搜索场景),从离线的实验结果来看,当结点的特征比较复杂且数据的规模比较庞大时,对异构性的建模效果还是比较明显的。 1.4.2 代表工作
RGCN[14]:RGCN可能是最早考虑异构性的GNN模型了,通过Edge-Type-Specific Transformation建模边的异构性。 HAN[15]:通过Node-Type-Specific Transformation建模结点的异构性,在计算Attention时不仅考虑了某Meta-Path下邻居的重要性,还考虑了不同Meta-Path之间的重要性。不过HAN比较依赖Meta-Path的人工选择。 KGAT[28]:通过Edge-Type-Specific Transformation + Ralation Embedding(类似于TransR)建模结点和边的异构性。 HGT[29]:在Attention计算和Message Passing阶段都考虑到了对异构性的建模,分别使用Node-Type-Specific Transformation和Edge-Type-Specific Transformation建模结点和边的异构性(不过这参数量相当大呀)。 1.5 图神经网络的优势
在应用某项技术解决业务场景中的某个问题时,我们需要充分了解这项技术的特点和优势,以下从五个方面谈谈个人对GNN优点的理解。 GNN VS MLP/CNN/RNN:图数据中结点邻居具有两个特点,一是数量不定,二是顺序不定,因此MLP/CNN/RNN无法直接处理这样的非欧式数据而只能用GNN建模。实际上,我们可以将GNN看做一种更加泛化的模型,例如,RNN相当于线性图上的GNN,而Transformer相当于完全图上的GNN。 GNN VS Graph Embedding:在GNN火起来之前已经涌现出很多Graph Embedding方法,并被广泛应用在搜推的向量召回阶段,这类方法受Word2vec[30]启发设计,从最初的的Item2Vec[31]的Item Sequence+Skip-Gram,到DeepWalk[32]的Random Walk+Skip-Gram;到Node2Vec[33]基于平衡同质性和结构性的考虑改进Random Walk部分;到MetaPath2Vec[34]基于对图的异构性的考虑改进Random Walk部分;到EGES[35]引入属性数据缓解行为数据的稀疏性,可以发现这类方法都遵循着Skip-Gram的范式。GNN相比这些方法的优点主要体现在四处: GNN可以结合目标任务端到端地训练,而Graph Embedding更像是预训练的方式,其学习到的Embedding不一定与我们的目标任务相关,特别是在样本规模庞大的业务场景,端到端训练得到的Embedding比预训练得到的Embedding更有效。 GNN的层级网络结构方便与其他深度学习技术结合(缝合怪水论文最爱),例如GCN+Attention=GAT。 GNN可以适用Inductive的任务,即当图的结构发生变化后,例如加入了一些新的结点,Graph Embedding方法就需要重新训练模型,而GNN可以使用类似GraphSage Node-Wise Sampling的方式,使用已经训练好的模型直接对新的结点进行推断。 GNN可以使用更加丰富的特征,Graph Embedding方法本质上使用的是ID特征,GNN在消息传递的过程中可以使用多种特征。 GNN VS Feature Concat & Collaborative Filtering & Proximity Loss:GNN相比后三种方法的优点可以统一归纳为:通过堆叠多层显示地学习高阶的关联信息。Feature Concat表示将特征拼接到一起然后通过特征交叉(例如FM,NFM等)可以学习到一阶的属性关联信息(区别于交叉特征的阶数),例如,user a买过item b,item b和item c都具有属性attribute a,那么user a也有可能购买item b,但是Feature Concat不保证能学到高阶的属性关联信息;Collaborative Filtering可以通过用户历史行为学习到一阶的行为关联信息,例如,user a和user b都购买过item a, user b又购买过item b,那么user a也有可能购买item b;Proximity Loss表示在损失函数中加入正则项使得相邻的结点更相似,但是一方面它是一种隐式的方式,另一方面想确保学习到高阶的相似关系,就需要加入更复杂的2,3,...,K阶正则项,实际上这也是GCN提出时的出发点之一。
2. 论文总结
该章节对选取的工业界的文章的共性部分进行总结,除了有人比较喜欢用来水论文的模型结构也涉及了图的构建,特征使用,采样方法,结合方式等部分。可以看到,对GNN的应用基本遵循着这套框架。 2.1 应用阶段
推荐系统不同阶段的特点影响着我们对某项技术的使用,召回阶段可以说是样本的艺术,而排序阶段可以说是特征的艺术。其中向量召回是一类常用的个性化召回方法,一般在离线训练时存下User和Item的Embedding,线上推断时通过LSH等方法从海量候选集中快速选出用户可能感兴趣的Items。以下总结了召回阶段常见的几个特点: 召回模型一般不会使用太多复杂的特征,以ID特征为主;排序模型会上很多特征尽可能描述用户,物品及行为过程。 召回模型一般使用PairWise Loss,排序模型一般使用PointWise Loss。个人理解一方面是因为召回阶段的目标是筛选出用户可能感兴趣的Item,至于感兴趣的程度是多少那是排序模型的职责,因此只需要使用PairWise Loss将正负样本尽可能区分开即可。另一方面是因为召回阶段的负样本不一定表示用户不感兴趣,只是没有曝光而已,如果用PointWise Loss建模会导致模型受噪声的干扰。 召回模型一般要从全库随机选取负样本,排序模型一般将曝光未点击作为负样本。在训练召回模型时时将曝光未点击作为负样本存在两个问题,一是线下线上的不一致,线上召回时面对的是全库的候选集;二是在上一轮能够得到曝光的物品已经属于用户比较感兴趣的,只不过同时曝光的还有更符合用户需要的选项,将这些样本直接作为召回模型的负样本不太合适。这里的“全库”也会根据场景变化,例如在搜索场景,由于Query的相关性限制,所以会在同类目下采样负样本。 GNN由于其构图,采样和计算的复杂性,更多被应用在召回阶段做向量召回。常见的一种方式是将Item推荐建模为User结点与Item结点的链接预测任务,同样在离线存下训练好的User和Item Embedding用于线上召回。不过在建模链接预测任务时,很容易产生信息泄露的问题,即在做消息传递时,没有将待预测的边从图中去掉,例如预测user a对item a是否感兴趣,没有去掉图中两者之间的边,user a和item a作为邻居直接融合了彼此的Embedding,导致模型难以学习到有效的信息。在复现一些论文的代码时,我发现这个问题还挺常见的。当然在召回阶段我们也可以结合目标任务端到端地训练。GNN也可以应用在排序阶段[36][37][38][39][40][41][42][43],此时存在两种结合方式,一种是先预训练[42],得到的Embedding以特征初始化或Concat的方式辅助排序模型的训练,另一种是GNN模块与排序模型整体一起做端到端地训练,不过这样需要考虑到线上打分时的效率,特别是GNN采样以及聚合带来的开销。当然我们可以将GNN模块作为Embedding Layer的一部分,在离线训练时得到包含了图信息的Embedding,在线上打分时直接使用该Embedding而无需调用GNN模块。 2.2 图的构建
“Garbage in, garbage out”,图数据构建不好,GNN魔改得再花哨也难奏效。对于构建图的数据,从数据来源来看,分为行为数据,属性数据和社交数据;从时间跨度来看,分为短期数据和长期数据;从用户粒度来看,分为单个用户和群体用户;不同种类的数据构建的图蕴含着不同的特点,下面一一介绍。 行为数据:行为数据是搜推广场景最常见也最重要的一类数据,应用很广的行为序列建模就是建立在该数据上,详情可以参考之前写的一篇文章:没什么大不了:浅谈行为序列建模。该数据可以构建两种类型的图: 二分图:最常见的方式是使用行为数据直接构建User-Item二分图,在user和其行为过的Item之间构建边,不过二分图的1阶邻居往往非常稀疏,因此有工作通过二分图的2阶邻居分别导出User-User和Item-Item同构子图[39],一方面通过2阶邻居的丰富性缓解了1阶邻居的稀疏性,另一方面也避免了对异构图的复杂建模,可以直接在子图上使用同构GNN。User-Item二分图的另一个缺点是难以及时反映用户的新的行为(即需要考虑图的动态性)。 共现图:共现关系表达了物品之间的关联,一方面可以在行为序列相邻的Item之间构建共现邻居关系[36],前后行为的Item一般比较相关;另一方面对于部分场景例如搜索场景,可以在某个Query下点击过的Item之间构建共现邻居关系,这些Item一般也比较相关。在这一过程中我们还可以统计共现频数[44],共现频数一方面可以用来去噪,共现频数较低的两个Item相关程度也低;另一方面可以用来计算权重分布用于Node-Wise采样,相比GraphSage随机采样,可以最大程度保留有效信息;对于计算的权重分布还可以用于指导对邻居的聚合过程。值得注意的是,在由User-Item二分图导出User-User或Item-Item子图时也可以统计类似的共现频数。 属性数据:行为数据构建的图往往是比较稀疏的,因此可以引入属性数据构建属性关系[45]。例如,Item a和Item b都具有属性Brand a,即两个商品都是同一个品牌的,这是我们可以引入Entity结点Brand,然后在Item a,b与Brand a之间构建属性邻居关系。这里让人不禁疑问为什么不直接将Brand作为Item的特征呢(Feature concat)?在上文讨论图神经网络的优点时已经提到,将Brand作为图的一部分可以用多层GNN学习高阶的属性关联信息。此外,当我们用属性数据与行为数据共同构建一张更复杂的异构图,此时还可以用GNN学习到异构的复合关联信息。 社交数据:我们还以用社交网络进一步丰富User之间的邻居关系,不过对于盲目使用社交数据的有效性我是存疑的。具有社交关系的人真的存在相似的偏好吗?首先,不同的社交关系含义不同,例如,亲戚关系更多表示血缘上的联系,不足以表达偏好上的关联。其次,社交关系表达的关联真的适用于我的场景吗?例如,朋友关系表达的更多是观点或思想上的关联,在电商场景下一对朋友不一定对商品拥有相似的偏好,但是在内容场景下例如抖音上,我和朋友确实都喜欢刷猫猫狗狗的视频。 短期数据 & 长期数据:对于行为数据,我们可以用第T-1的数据构建图用于第T天,也可以用连续N天的数据构建图用于第T天。短期数据更容易保留最近的流行趋势,例如,这两天人们抢着买压缩饼干啥的,但是构建的图会非常稀疏;长期数据更容易保留稳定的一般规律,例如,人们买完手机过阵子又买手机壳钢化膜啥的。 单个用户 & 群体用户:单个用户的行为数据构建的图更具个性化[43],所谓“一人一图”,但是同样会存在稀疏问题;群体用户的行为数据构建的图更具泛化性,并且可以缓解某些长尾物品的冷启动问题。 以上几种模式并不是孤立的,可以根据不同的场景进行组合。此外,还存在着其他一些图模式。例如,GMCM[38]构建的图的结点是各种微观行为,边是它们的转移过程,权重是其转移概率,并且将CVR预测建模为了图分类任务。 2.3 特征使用
毫无疑问,ID特征是最重要的,但是利用其他特征诸如Item的Shop,Brand,Category等可以增强我们模型的泛化能力。对于这些泛化特征,一方面,我们可以直接使用Feature Concat的方式统一作为结点的特征,另一方面,也可以把这些特征建模为Entity结点从而学习高阶的属性关联信息。利用它们的难点在于特征维度和语义空间的对齐(异构性),可以从图的构建或模型结构方面加以解决。 2.4 采样方法
在第一部分已经介绍了三种常用的采样方法,搜推中用的比较多的是Node-Wise Sampling,在这里我们进一步完善讨论下该方法。必须强调的是只有当图的规模比较大时才需要采样,对于像UaG[43]中用单个用户行为数据构建的图(一人一图)就不需要采样。我们可以将Node-Wise Sampling 抽 象为两个步骤: Root结点的采样和邻居结点的采样。 Root结点的采样:Root结点是我们在训练或推断时需要直接用到的结点,例如,使用User和Item之间的链接预测任务建模Item推荐时,首先需要采样一个Batch的待预测的边,这些边两端的User和Item作为Root结点;或者我们想用图信息丰富用户行为序列中Item的表征,则行为数据中的Item作为Root结点[36]。 邻居结点的采样:这一步为每个Root结点采样其邻居结点,都是以迭代的方式采样1-K阶邻居(包括Random Walk)。 全采样:即保留所有1-K阶邻居,邻居数量会非常庞大,适用于离线“预训练”的方式,即线上只用到训练好的Embedding,不然单采样带来的开销就无法承受。 均匀分布采样:即GraphSage中的采样方式,每个邻居结点被采样到的概率相同。 概率分布采样:区别于GraphSage的均匀分布采样,例如上文提到的在构建图时统计的共现频数,归一化后可以作为采样的概率分布,这样更容易采样到重要的邻居。 Meta-Path采样[41]:按照预定义的Meta-Path去采样邻居,实际上相当于在异构图中采样高阶邻居,例如,按照Meta-Path User-Item-User采样User的User邻居。 Random Walk采样[46]:使用Random Walk方法采样邻居,本质上也是一种概率分布采样,每个邻居被采用的概率由度数计算。我们可以使用不同的Random Walk策略,例如个性化PageRank。 2.5 模型结构
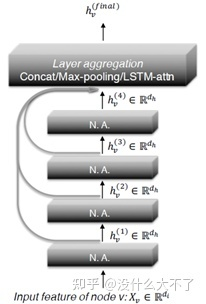
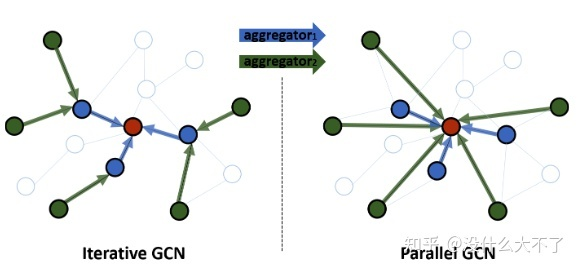
在第一部分已经介绍了一些常用的GNN模型,这里我们进一步将GNN抽象为两个步骤:邻居聚合和表征融合。在应用GNN到推荐系统时,主要从异构建模和特征交互两个角度改进模型,Attention机制和Layer Aggregation贯穿其中。 邻居聚合:顾名思义,即聚合邻居结点的信息,得到中心结点的邻域的表征。GCN是在每一层对每个结点聚合1阶邻居,则第K层的输出则包含了K-Hop范围的邻居信息,但是它需要操作全图无法扩展到大规模图数据。这里我们讨论Node-Wise Samling下邻居聚合的过程。 迭代聚合:Node-Wise Sampling实际上围绕中心结点构造了一个1-K阶的层次邻域结构,因此可以迭代地聚合K-1阶的邻居直到中心结点,这也是GraphSage采用的方式,它的一个缺点是计算是串行的,计算完第i阶才能继续第i-1阶的计算,如果线上需要用到该过程会导致RT过高。 并行聚合:我们可以直接并行地聚合1,2,...,K阶邻居,然后再融合它们得到最终的邻域表征,避免了串行计算带来的高时间开销。 表征融合:经过邻居聚合得到邻域表征后,我们还需要将它与自身表征融合。常用的几种方式是:Add[11],Concat[5],Attention。Attention主要是考虑到自身与邻域表征的重要性差异。 异构建模:第一部分提到真实场景中的图数据大多是异构的,在使用GNN时需要考虑到结点与边类型的差异性。考虑异构性后我们可以将上述过程扩展为三个步骤:邻居聚合,邻域融合,自身融合。在模型结构上基本都遵循着第一部分提到的Node or Edge Type-Specific Transformation+Attention的框架。 邻居聚合:邻居结点存在不同的类型,因此一般按类型分别聚合邻居。一种比较特殊的方式是将原来的异构图转化为一系列的同构子图,在这些子图上可以直接使用同构GNN。 特征交互:部分工作认为GNN缺少对邻居之间的交互[47][48],邻域之间的交互[48][49],邻域与自身的交互[50]的建模,因此引入元素积,self-Attention,co-attenive等方式增强特征交互。 Attention机制:Attention可以说是万金油技术了,这里主要被用来建模邻居之间的重要性差异,邻域之间的重要性差异,自身与邻域的重要性差异。 Layer Aggregation[51]:在Deeper GNN部分提到过,第K层输出包含了K-Hop邻居信息,Layer Aggregation即组合不同范围的邻居信息。 3. 论文介绍
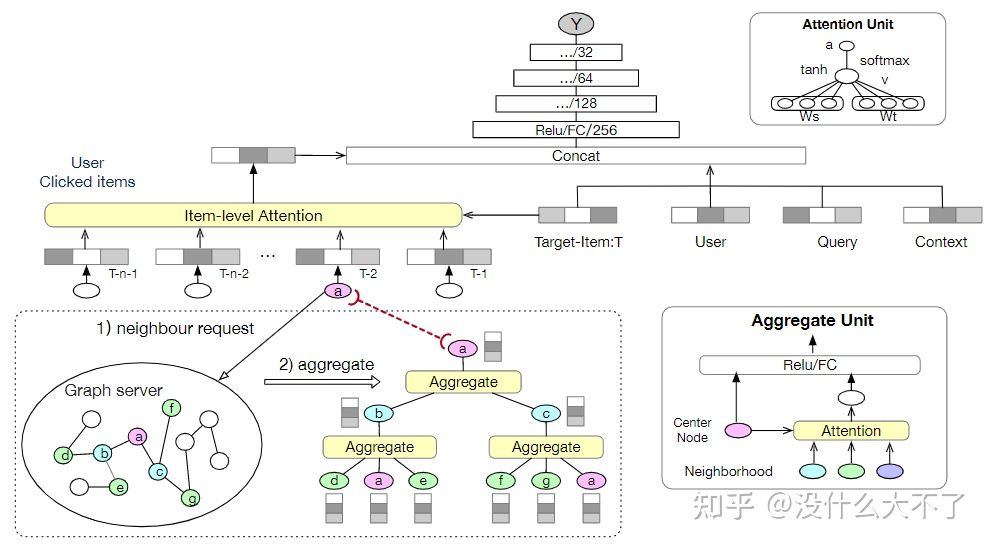
3.1 Graph Convolutional Neural Networks for Web-Scale Recommender Systems[46] [PinSage],KDD 2018,Pinterest
问题背景:现有的GNN难以在大规模图数据场景落地 业务 场景: i2i Top N推荐(似乎因为场景复杂性低的问题,这里并没有进一步分召回排序) 图的构建:Pin-Board二分图,Pin是照片,Board类似收藏夹 特征使用:Pin包含了图像特征和文本特征,Board本身没有特征,而是通过Average Pooling对应的Pin们得到 采样方法:Node-Wise Random Walk Sampling,使用个性化PageRank采样邻居,得分既可以用来加权聚合邻居,也可以用来构造Hard Sample。 Model Architecture:使用采样时的得分加权聚合邻居
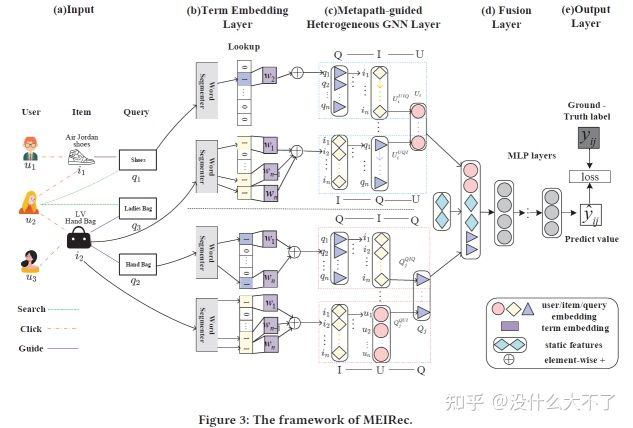
User在某个Pin下点击的Pin构成一对正例,然后从其他Pin中随机采样一部分作为Easy Negative,采样时得分位于某个范围的Pin邻居作为Hard Negative。Easy Sample往往很好区分,模型无法从中学习到有效信息,而Hard Negative则可以迫使模型学得更好,但是也容易导致收敛困难,因此可以在起初几个Epoch只使用Easy Sample,然后再逐步加入Hard Sample 3.2 Metapath-guided Heterogeneous Graph Neural Network for Intent Recommendation[41] [MEIRec],KDD 2019,阿里
问题背景:当前的方法没有充分利用关联信息,作者利用异构 图和相应模型来建模学习; 通过Term Embedding共享的方法来降低学习量。 图的构建:群体用户行为数据构建的Query-Item-User异构图,目标是学习User和Query的Embedding。特征使用: Query和Item的Title共享Term Embedding,降低了需要学习的参数量,同时可以适应新的Query和Item User的embedding通过Q-I-U、I-Q-U两条Meta-Path对应的邻居聚合得到 User Profile等静态特征最后与GNN得到的Embedding Concat后输入MLP 采样方法:Node-Wise Meta-Path随机采样 模型结构:主要是对于不同类型的邻居采用了不同的Aggregator 对于Item的Query邻居采用Mean Aggregator 对于User的Item和Query邻居采用LSTM Aggregator,考虑到了User对Item和Query的行为是有时序的 对于Query的邻居Item和User采用了CNN Aggregator
3.3 IntentGC:a Scalable Graph Convolution Framework Fusing Heterogeneous Information for Recommendation[45] [IntentGC],KDD 2019,阿里
问题背景:已有的工作大多利用社交网络或共现关联分别为User-Item二分图中的Users和Items扩充内部连接,却忽略了属性关联这一类丰富的信息。 图的构建:群体用户行为数据+属性数据构建以User和Item为主体的异构图,接着通过User-Property-User和Item-Property-Item构建User-Item异构图,属性结点的类型决定了构建的边的类型。 特征使用:双塔结构,可以用多种特征(不存在特征对齐的问题) 采样方法:先采样一些User-Item Pairs(包括负样本)作为mini-batch,然后对这些User和Item分别Node-Wise Sampling同构邻居。Faster Convolutional Network: IntentNet Vector-wise convolution operation
公式(2)有两个作用,一是以不同的重要性融合自身和邻居信息,二是concat后的各维度间的特征交叉,作者认为自身Embedding和邻居Embedding之间的特征交叉没有意义,内部的特征交叉才是有意义的
公式(3)对公式(2)进行了简化(时间复杂度和模型参数量都有所降低),在vector-wise的层次以不同重要性融合自身和邻居信息,并且通过多组融合操作得到不同角度的信息(类似多个不同的卷积核),最终再进行一次加权融合。
IntentNet:再经过一个多层MLP进行特征交叉 Heterogeneous relationships:将Vector-wise convolution operation推广到了存在多种类型关系的情形,对不同类型关系对应的邻居分别聚合然后对得到的邻域表征再加权融合
Dual Graph Convolution in HIN:对于User-User和Item-Item分别应用上述模型(双塔结构),最终得到User和Item Embedding做点积,使用Pair-Wise Margin Loss训练。
3.4 A Dual Heterogeneous Graph Attention Network to Improve Long-Tail Performance for Shop Search in E-Commerce[44] [DHGAT],KDD 2020,阿里
问题背景:shop name和query的语义存在gap,很多时候shop name并不能表明含义;shop search场景的行为数据比较稀疏,特别是对于长尾的Query和Shop效果不佳 图的构建:长期群体用户行为数据构建的shop-query-item异构图 对于Query,某个用户同一个Session内的Query之间构成邻居;引导点击同一个Shop的Query之间构成邻居 对于Shop,同一个Query下点击的Shop之间构成邻居 Query下点击的Shop,它们之间构成邻居(但是这种关系是非常稀疏的) 某个shop提供的item在某个query下被成交过,则该shop和query构成邻居(本质上是二阶邻居,该关系相对丰富) shop提供的item,query下点击的item,它们之间构成邻居 DHGAT部分用的是Query、Shop、Item的ID特征 TKPS部分用的是Query、Shop、Item的Term特征 采样方法:Node-Wise Sampling,对于Shop和Query,分别采样N个Homogeneous和Heterogeneous邻居,即2N个邻居(防止热门shop或query的影响)。 Dual Heterogeneous Graph Attention Network:
先对同构邻居和异构邻居分别Attention Pooling,然后再对不同类型的邻域Embedding加权融合,最后再与自身Embedding进行concat融合 在对异构邻居进行聚合时使用heterogeneous neighbor transformation matrix建模异构性 这里item不作为target node,最终需要的是query和shop的embedding Transferring Knowledge from Product Search:利用行为数据相对丰富的product search场景的数据促进对shop search场景的学习 这里使用的是query,item和shop的terms mean pooling特征
由于quey和shop name语义的模糊性,聚合时不适合用Attention pooling,而是直接使用mean pooling Incorporating User Features:用户自身的特点也会影响偏好,预测用户在某query下是否会点击某shop需要考虑该信息 Two-tower Architecture:对shop和query embedding的学习可以并行进行,线下训练时可以存下user,query和shop embedding,其中shop embedding存的是最后一层的输出(线上不可能再将所有的shop过一遍右塔),线上打分时获取到user和query embedding,然后需要经过左侧的塔得到一个融合的embedding(这个过程只需要进行一次,其线上开销是可以接受的),接着通过LSH等方法召回相关的shop Objective and Model Training
使用交叉熵损失训练CTR预估任务,不过值得注意的是召回阶段负样本的选择,不能是曝光未点击的作为负样本 CTR Loss可能会导致不能充分学习到图的拓扑信息,这里又进一步加了graph loss,从loss角度促进同构邻居更相似 3.5 M2GRL: A Multi-task Multi-view Graph Representation Learning Framework for Web-scale Recommender Systems[52] [M2GRL],KDD 2020,阿里
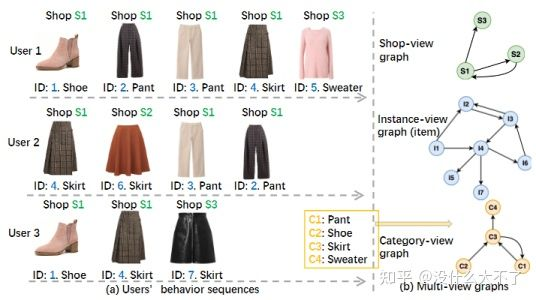
问题背景:单个向量表达Multi-View(多种特征空间)信息可能会存在两点问题,容量不足以及分布不同 图的构建:文中没有具体谈到,应该是群体行为数据构建的多个Single-View同构图。 但是值得注意的是,本文具体实现时并没有用图结构,而是类似Item2Vec的方法直接对行为序列用skip-gram建模。 本文构建了三个Single-View图,基于Item本身构建的图,基于Item Shop构建的图,基于Item-Category构建的图
Node sequence sampling:用于下文的Skip-Gram方法,通过Session划分尽量保持滑动窗口内Item的同构性 Data Clean:去掉停留时间比较短的Item,用户可能是误点并不感兴趣 Session split and merge:用户打开和关闭淘宝的时间段作为一个Session,对于时间较长的Session(几个小时,可能是后台运行)进一步拆分,对于时间较短(小于30分钟)的两个连续的Session进行合并 Intra-view Representation Learning:随机采样上文划分后的Session序列,然后使用Skip-Gram方法训练。
Inter-view Alignment:不同View的信息存在关联,例如,某个Item属于某类Category或者某个Shop,这里进一步学习该关联使得相关的Item-Category或者Item-Shop的Embedding更加接近,使用了一个变换矩阵期望将不同View的Embedding映射到同一个特征空间。
Learning Task Weights with HomoscedasticUncertainty:考虑到许多任务联合训练,人工设置加权Loss不太现实,这里利用homoscedastic uncertainty来自动学习不同任务的重要性,最终不确定性越大(可学习的参数)的任务权重越低。
3.6 Gemini: A Novel and Universal Heterogeneous Graph Information Fusing Framework for Online Recommendations[39] [Gemini],KDD 2020,滴滴
问题背景:基于User-Item二分图的方法,一种是直接在原图上交叉聚合,另一种是借助辅助数据(如社交网络)将其划分为User-User,Item-Item同构图。前者会存在邻居稀疏的问题,后者则丢失了User-Item关联信息,并且辅助数据限制了应用场景。 图的构建:群体用户行为数据构建的二分图,接着通过User-Item-User,Item-User-Item关系导出User-User和Item-Item同构图,由于是通过二阶邻居导出的子图,在某种程度上缓解了邻居稀疏的问题。 Node Embedding:同构子图可以使用User和Item的多种特征,但是作者对边的异构性进行了建模,因此实际只能使用ID特征。
User-User子图中,边由导出时的中间Items决定(保留了原来的一阶邻居信息) 直接对Items Sum pooling无法建模重要性差异,因此作者提出了TF-IDF Pooling,其中TF是某Item在该边对应的所有Items中的占比,占比越大,说明对该边来说越重要;IDF是某Item在所有边对应的Items集合中的占比,占比越大,说明该Item重要性越低。TF-IDF=TF*IDF。 这里没有直接用TF-IDF加权求和,而是将该得分分桶离散化然后Embedding,通过元素积的方式进行特征交叉 采样方法:Node-Wise Sampling Attention based Aggregating:加性模型计算Attention,并且考虑了Edge Embedding,得到邻域Embedding后与自身Embedding进行融合。
训练推断:使用MLP计算User点击某Item的概率,损失函数交叉熵,点击Item为正样本,曝光未点击Item为负样本(因此可以断定是排序模型) Joint training:在User-User上聚合邻居时,Edge Embedding需要用到Item Embedding,反之亦然,所以User-User和Item-Item的聚合过程是相互依赖的。 Gemini-Collaboration Framework:似乎是将原来相互依赖的两个聚合过程分开,先将其中一个训练至收敛再进行另一个,从而降低训练的复杂度,类似GAN的训练方式。 3.7 Multi-view Denoising Graph Auto-Encoders on Heterogeneous Information Networks for Cold-start Recommendation[40] [MvDGAE],KDD 2021,腾讯
问题背景:User-Item行为数据往往非常稀疏,新用户或新商品存在冷启动问题。一类方法通过引入更多属性特征缓解,但是这会非常依赖特征数据的获取和质量;另一类方法通过HIN引入属性信息来缓解(这和上面的有什么区别),但是它们大多通过有监督的方式训练,会产生训练和测试阶段的不一致(训练阶段大多是old user或item,测试阶段存在更多new user或item,它们在图中的连接会比较稀疏,只存在一些属性关联)。 业务场景:文中没有具体说,从损失函数与推断方式来看似乎是物品推荐的排序阶段
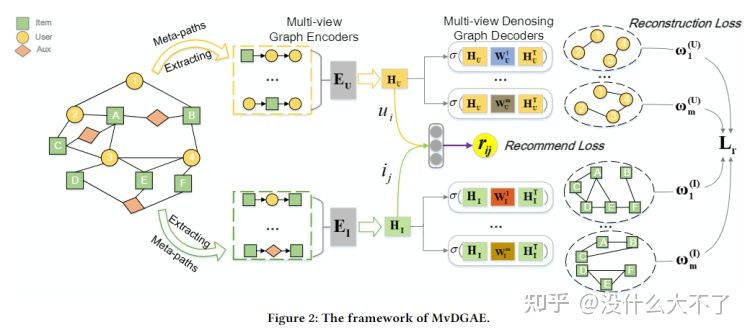
特征使用:从聚合方式来看,只用上了ID特征(需要注意的是,这里是是指单个结点的ID特征,实际上在HIN中,属性特征被建模为了结点,例如,电影的演员特征,演员被建模为了结点) 采样方法:分为两个阶段,Encoder阶段基于Meta-Path(首尾不限) Node-Wise采样,Decoder阶段基于特定的Meta-Path(首尾相同)采样出User-User和Item-Item子图,每个Meta-Path对应一个View。Multi-view Graph Encoders Node-level Aggregation based on Meta-path:通过GAT聚合Node-Wise采样到的邻居,这里不同于HAN,对于Meta-Path上的邻居(存在不同类型)都会聚合。 Dropout on Multi-views:这里是对View的Dropout,而不是某个View下Edge的Dropout,通过Dropout可以迫使学习到的Embedding更具泛化性,在测试时对于连接稀疏的new user或item有更好效果。
Multi-view Graph Denoising Decoding Construct Multi-View Graph:基于首尾相同的Meta-Path构建不同View的User-User和Item-Item子图,使得那些相似的User或Item的表征也更接近。 Multi-View Graph Decoding:用Encoder得到的Embedding重构多个View的子图,即链接预测任务。 Sampling Strategy:对所有结点对预测边开销太大,需要经过采样预测部分边,这里对Meta-Path 1-hop邻居完全采样,然后对2 hop邻居部分随机采样,以缓解1-hop邻居稀疏的问题。 Bayesian Task Weight Learner:多个View子图的Encoder和Decoder是独立的,最终需要将它们的Loss整合到一起联合训练,这里也用了异方差不确定性来自动学习权重。 Optimization Objective:Loss由两部分组成,一部分是重构Loss,一部分是评分Loss(均方差)(如果只有点击数据,那就是交叉熵),所以本文其实是利用到了标签数据,是无监督+有监督的结合。 3.8 Graph Intention Network for Click-through Rate Prediction in Sponsored Search[36] [GIN],SIGIR 2019,阿里
问题背景:使用单个用户的历史行为表征用户兴趣存在行为稀疏和泛化性弱的问题;图神经网络预训练的方式得到的Embedding与目标任务不相关。 图的构建:群体用户行为数据构建Item同构图。首先将Item点击序列按照Query相关性划分为多个Session,然后在Session内相邻Item之间构建邻居关系(防止不相关的两个Item成为邻居),边的权重为共现频数。具体使用近30天所有用户的点击序列构建商品相似图。 采样方法:Node-Wise Sampling,根据共现频数计算概率分布 模型结构:为序列中的每个Item采样邻居用GNN聚合得到更一般的Embedding,即通过构建图引入额外信息丰富行为序列从而缓解行为稀疏问题和泛化性弱的问题。得到更一般的Embedding后就是常规的Target Attention抽取序列中的偏好信息。 3.9 ATBRG: Adaptive Target-Behavior Relational Graph Network for Effective Recommendation[37] [ATBRG],SIGIR 2020,阿里
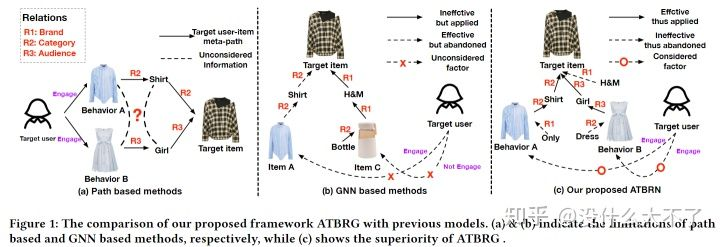
问题背景:基于Meta-Path的方法,一方面需要人工经验设计,另一方面会损失结构信息(各Meta-Path独立);基于GNN的方法,一方面对Target Item和User分别采样,缺少它们之间的交互性,另一方面随机采样邻居可能会引入噪声(这个得看图是怎么构建的吧,并且我们也可以按权重采样)。
a中由于各Meta-Path独立,衬衫和连衣裙没能建立起关联 b中一方面由于分别采样,丢失了Target Item与用户行为过的连衣裙的关联,另一方面由于随机采样反而引入了开水壶噪声 c中用本文特有的构建图的方式,最终得到的KG图既能较好地保留结构信息,又能去除一些与Target Item不相关的噪声。 采样方法:从Target Item和用户行为过的Items构成的Root Nodes合集中,分别为每个结点在图中采样K-Hop邻居,根据采样的结点集合从原图中诱导出子图(区别于独立采样,可以建立Target Item与行为过的相关的Item的联系),对于该子图中只有一个邻居的结点进行剪枝(这些结点很可能是噪声)。
Embedding Layer:User和Target Item的Embedding(ID和其他特征),异构图(KG图)中实体和关系的Embedding。 Relation-aware Extractor Layer:这里是用中心结点计算邻居结点的重要性,同时对“关系”进行了建模,即关系的类型会影响重要性,例如,点击和购买两种关系,显然表现出的兴趣程度不同
Representation Activation Layer:得到Target Item和Sequence Item的Embedding后,这里又进一步使用Target Attention筛选相关信息
Feature Interaction Layer:将所有Embedding Concat后送入MLP做特征交叉 3.10 GMCM: Graph-based Micro-behavior Conversion Model for Post-click Conversion Rate Estimation[38] [GMCM],SIGIR 2020,阿里
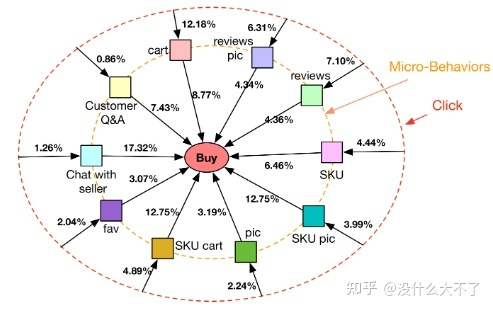
微观行为与最终是否成交高度相关,但是微观行为不适合用序列建模,不同顺序的微观行为表达的可能是同一意图,例如,用户在购买前先看评论再看问大家,和先看问大家再看评论,表达的意图一样。(这里的微观行为是指用户点击商品后,购买商品前发生的一系列行为,例如评论,收藏等)
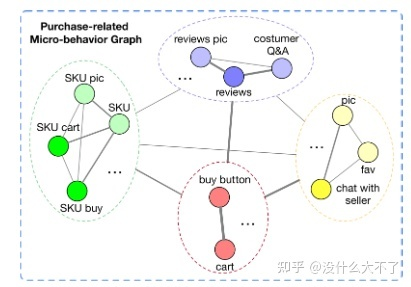
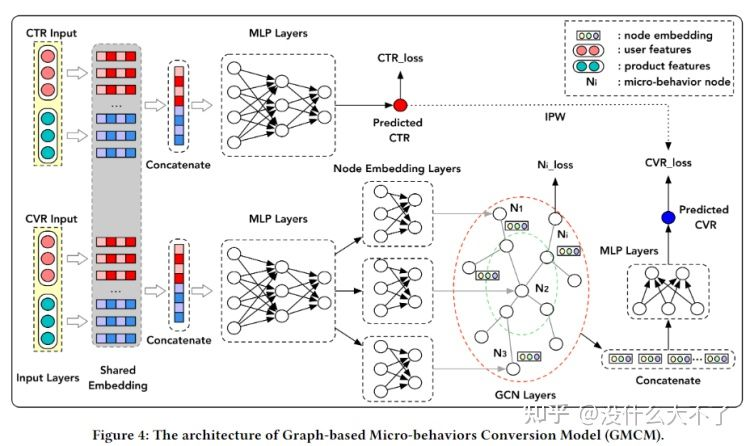
CVR任务存在数据稀疏的问题(用户的成交行为是稀疏的) CVR任务存在样本选择偏差的问题(用户是先点击后成交,但是线上CVR预估时,是从全域候选集经过召回后打分,而不是对用户发生过点击的Item打分) 业务场景:商品推荐排序阶段 微观行为图,结点是微观行为,边是共现频数归一化后的权重 用所有用户的微观行为数据构建图,即该图反映的是一般性的群体规律,对于单个用户其微观行为数据体现在Node Loss中
特征使用:上游多种特征变换对齐后的Embedding 采样方法:微观行为图是很小的,不需要进行采样 Multi-task Learning Modul:底层共享部分Embedding(特别是ID Embedding)
Node Embedding Layer:将MLP的输出通过N个1-Layer MLP映射为N个微观行为结点Embedding
Graph Convolutional Networks
这里分成了两个任务,一个是预测某个微观行为结点是否存在,即在构建图时是默认所有微观结点都存在,并且图的边权也是所有用户数据统计出的。单个用户的微观行为数据是在Node Loss中体现的。 另一个是将CVR预测转化为了图分类任务,即微观行为图可以反映用户是否会发生成交 图的Embedding通过Graph Pooling得到,例如Sum pooling,Mean pooling,Concat Pooling Loss Layer:相应的PMG Loss也由Node Loss和CVR Loss构成,最终Loss由PMG Loss和CTR Loss组合而成(也有分别训练)。这里将CTR预估分数作为了IPV来Debias。
编辑:王菁
校对:林亦霖