
Python是如何管理内存的?
1. 内存管理关我屁事?
内存管理是指在程序的运行过程中,分配内容和回收内存的过程。如果只分配,不回收,电脑上那点内存很快就被用光。
好的程序能够高效的使用内存,不好的程序会造成过多的内存消耗,内存泄露,栈溢出,程序死翘翘。

幸运的是,Python和Java等高级语言会自动管理内存的分配和回收。
但程序员仍然必须具有一定内存管理知识!
小白需要内存管理知识避免犯低级错误,高手需要内容管理知识来优化程序性能,就像赛车手调教汽车的性能。

举个例子:生成包含1亿个随机字符串的序列,小白可能用list,而有点经验的会用generator。内存的使用效率可能差了一亿倍。
generator出现的一个重要原因就是省内存。
2. 可变数据类型和不可变数据类型
当我们调用函数的时候,我们需要传递参数,这时候变量从一个函数传递到了另一个函数。这个传递过程发生了什么?
被传递的对象是被复制了一份呢?还是就是同一份呢?
我们得先理解变量的存储结构,尤其是list等容器类的存储。
看下面的代码:
name = '麦叔'
print(id(name)) #打印内存地址:140628480727248
name = '张三'
print(id(name)) #打印内存地址:140628480727056
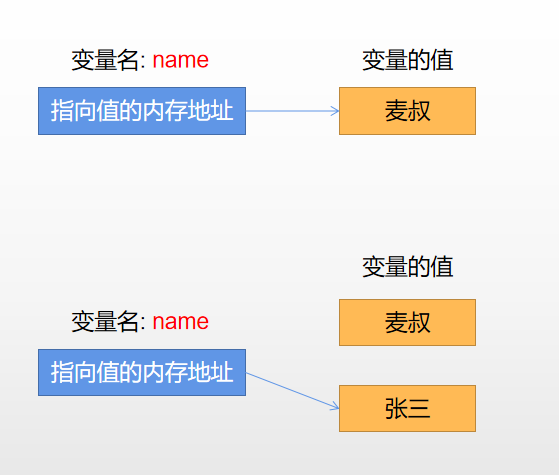
当我们定义了一个变量name = '麦叔',在内存中有两个部分:
一个是name这个变量名 一个是真正存储'麦叔'这个字符串的对象
上面的代码在内存中的过程是这样的:
开始变量名name指向了“麦叔”。 后来变量名name指向了“张三”。
注意:这时候“麦叔”不再有变量使用了,可能会被垃圾回收器销毁掉。
对于一个复杂的数据类型,比如list,原理是相同的但是更复杂:
cities = ['北京', '上海', '广州', '深圳']
print(id(cities))
cities[3]='雄安'
print(id(cities))
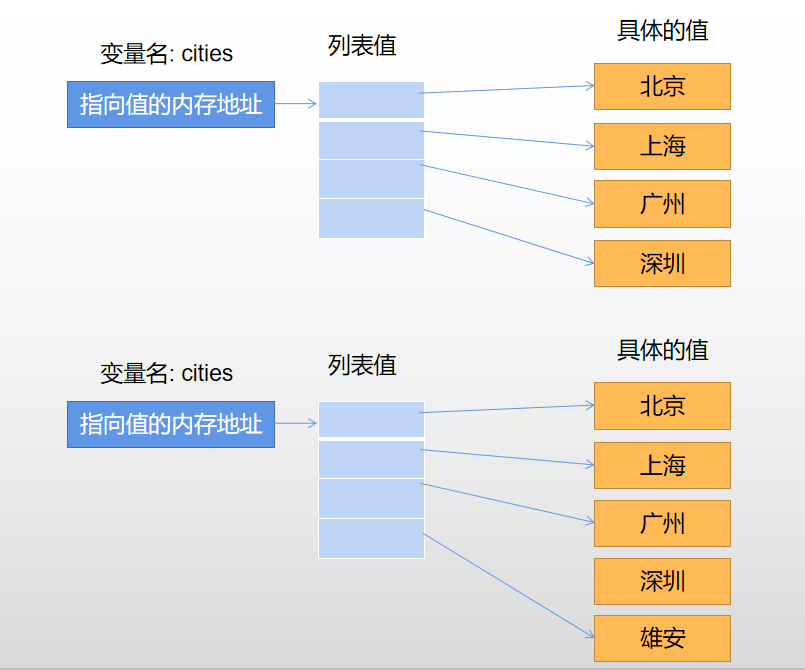
cities一直指向内存中的列表对象,列表中的值改变不会改变cities在内存中的地址。改变的是列表指向的另外一个对象的地址。
这里的要点:
name等字符串是不可变的,当变量的值变化了,实际上生成了一个新的变量,内存地址变化了。
基本数据类型都是不可变的,还有整数,小数等都是不可变。当一个变量的值发生了变化,实际上是创建了一个新的对象。
而cities是个list,是可变的,里面的值会发生变化,内存地址没有发生变化。可变还包括dict等。
3.参数传递
理解了变量的内存存储结构,来看参数传递的问题,在函数调用过程中,参数传递到底是传递了什么?是复制了一份吗?
简单说:函数参数和返回值的传递都是传递的变量指向的内存地址!
import random
name = '麦叔'
print(f'name的地址:{id(name)}')
def shuai_score(person):
print(f'name的地址:{id(person)}')
score = random.randint(1, 10)
print(f'score的地址:{id(score)}')
return score
mscore = shuai_score(name)
print(f'mscore的地址:{id(mscore)}')
对于普通对象(不可变类型)和容器类变量可能看起来效果不一样,但实际上原理是一样的。如下面的代码:
全局变量name指向张三,这一直都没有变过。 局部变量name本来是指向张三的,但是后来指向了李四,这并不影响全局变量还是指向张三。
name = 'zhangsan'
def hello(name):
print('传进来的是:'+ name)
name = 'lisi'
print('name被改成了' + name)
print(name)
对于列表,改变列表的值会影响全局变量。
cities = ['北京', '上海', '广州', '深圳']
print(f'全局cities的地址:{id(cities)}')
def change_city(cities):
print(f'局部cities的地址:{id(cities)}')
cities[0] = '雄安'
print(f'局部cities的地址:{id(cities)}')
change_city(cities)
print(cities)
print(f'全局cities的地址:{id(cities)}')
4. 引用次数和垃圾回收器
上面的知识和内存管理有什么关系?当然有!
内存管理的基本原理:回收掉没用的内存!
怎么判定有用没用呢:如果还有变量在使用就不要回收,没变量使用了就干掉它。
好可怕,做个打工人也一样吧?如果你还有用就继续打工,没用了就干掉。
上面的例子中:'麦叔'这个对象没用了,因为变量name指向了新的对象'张三'。
Python用引用次数,英文叫做reference count来表示有几个变量在使用这个对象。
通过一个叫做垃圾回收器(英文是Garbage Collector)的后台线程定期查看是否有些变量的引用次数为0,并清理掉引用次数为0的对象。

引用次数是如何产生的?
当对象被赋值给新的变量,引用次数就会增加 当变量作为参数传递给其他函数,引用次数就会增加
引用次数如何减少?
当函数执行结束,引用对象的变量不再有效,引用次数减少
我们可以通过sys.getrefcount查看一个对象的引用次数:
import sys
name = '麦叔'
print(sys.getrefcount(name)) #打印4
上面的代码会打印出4次!
这是怎么回事?明明只有一次啊!这4个引用是:
name变量 getrefcount:当name被传递给getrefcount函数的时候,函数的参数也指向了它。 Python解释器:为了执行这个脚本,Python解释器也保留了一个引用,直到脚本结束。只针对脚本全局变量。 编译优化器:当执行脚本的时候,优化器会尝试优化字节码,所以也产生了一次引用。这个引用是临时的,很快就会消失。
如果不在脚本中运行,直接在交互式Python下运行,refcount是2,因为没有后面两个引用:
>>> import sys
>>> name = '麦叔'
>>> print(sys.getrefcount(name)) #打印2
再来看一段代码:
import sys
name = '麦叔'
print(sys.getrefcount(name)) #打印4
name2 = name
print(sys.getrefcount(name)) #打印5
name3 = name
print(sys.getrefcount(name)) #打印6
因为name2和name3都指向了'麦叔',所以引用次数不断增加。
注意:getrefcount函数执行完,它产生的引用就消失了,所以不会因为调用了3次而增加3个。
5. 手工回收
正常情况下,回收垃圾这事儿都是Python的垃圾回收器的活。
就像赛车手要自己调教汽车,必要的时候我们也可以自己动手。
import sys, gc
# 这个函数创建一个自己指向自己的列表
def create_cycle():
list = [8, 9, 10]
list.append(list)
print("创建垃圾...")
for i in range(8):
create_cycle()
print("我们来强制回收...")
n = gc.collect()
print("清理掉的无头尸体:", n)
print("没清理的垃圾:", gc.garbage)
执行结果如下:
创建垃圾...
因为与引用,所以不会被自动回收...
我们来强制回收...
清理掉的无头尸体: 8
没清理的垃圾: []
运送垃圾的车有自己的时间点,比如每天早上6点。但如果垃圾太多了,也可以打电话让他们马上来过清理垃圾。
垃圾回收器有它自己的运行节奏。我们可以调用gc.collect()让它马上执行回收操作。
6. 要点
知道可变数据类型,不可变数据类型,以及参数传递原理 理解list等可变数据类型作为参数传递后修改的是同一个对象 合理使用对象,避免占用太多内存,比如大数据情况下使用generator而不是list 避免变量循环引用,造成引用数永远不为零,可能造成不可回收而引起内存泄露。
今天这些对大部分人可能够用了。其实内存管理和垃圾回收是比较高级的话题,属于编程的深水区。有兴趣的建议多研究一下,深水区里去游一下。