
韩松团队新作 | MCUNet | IoT设备+微型机器学习时代已经到来了
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达

【Happy导语】MIT韩松团队提出了一种适用于IoT设备的模型设计方案,它将NAS与Engine进行了协同设计,从而确保了模型可以更好的在微型处理器上运行,同时具有更高的精度。该文的研究成果将进一步加速IoT设备端的AI应用,这个方向具有非常大的市场前景,期待各位同学能在该领域取得更多的成果。
Paper: https://arxiv.org/abs/2007.10319
Abstract
基于单片机(Microcontroller Units, MCU)的微型IoT设备上的机器学习应用是非常有价值的,但同时也极具挑战:单片机的内存要比手机内存小的多(比如ARM Cortex-M7 MCU仅有320kb SRAM与1MB Flash存储)。
作者提出了MCUNet,一种高效网络架构搜索(TinyNAS)与轻量推理引擎(TinyEngine)联合设计的方案,它可以使得ImageNet级别的推理在微处理器上进行运行。TinyNAS采用了两阶段的网络架构索索,在第一阶段优化搜索空间以适配资源约束,在第二阶段进行网络架构搜索。TinyNAS可以在低搜索复杂度下自适应处理不同的约束问题(比如设备、延迟、功耗以及内存等),并与TinyEngine协同设计。TinyEngine是一种内存高效的推理库,它按照整体网络采用了内存机制设计,而非传统的layer模式,它可以降低2.7x的内存占用并加速1.7-3.3x的推理速度(相比TF-Lite Micro与CMSIS-NN)。
MCUNet是首个在现有微处理器产品上达到70%精度的模型(ImageNet数据),相比MobileNetV2与ResNet18,它的更低的SRAM(3.6x)和Flash占用(6.6x)。在视觉&语音唤醒任务上,MCUNet取得了SOTA精度,比MobileNetV2和ProxylessNAS快2.4-3.4x,同时具有更低的SRAM占用(2.2-2.6x)。该研究意味着:永远在线的IoT设备上微型机器学习时代已经到来了。
Introduction
在我们的生活中,IoT设备已变得非常常见(据统计已达250B),并用于方方面面(比如智能制造、个性化医疗、农业生产、自助零售等等)。这种低成本、低功耗的微处理器也为微型机器学习的应用带来了新的机会,如能在这类设备上运行AI算法,那么我们可以在端上直接进行数据分析,进而扩大了AI的应用领域。
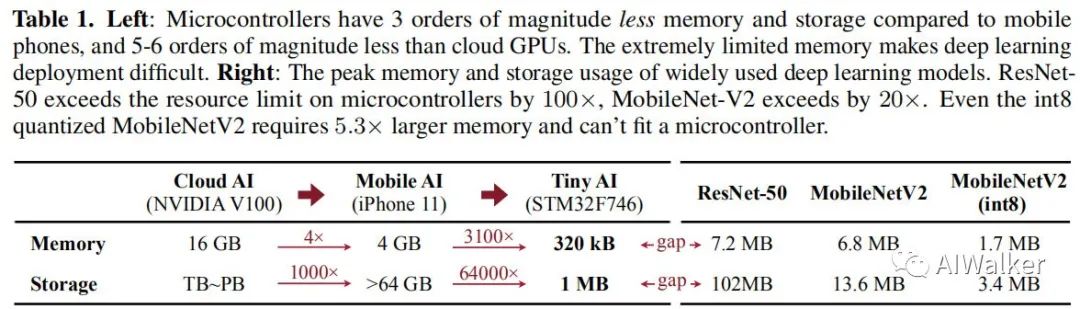
然而,微处理器具有非常有限的资源负载,尤其是SRAM和Flash,要比手机端或者GPU的资源小的多,这也使得深度学习在IoT设备上的部署具有挑战性。下图对比了GPU、手机端以及微处理器的资源信息,很明显在微处理器上运行ResNet50、MobileNetV2是不可行的。峰值内存占用远远超出微处理的最大内存,两者之间存在巨大的差距。
注:SRAM可以进行读写,约束了feature-map的大小;flash只可以进行读,约束了模型大小。
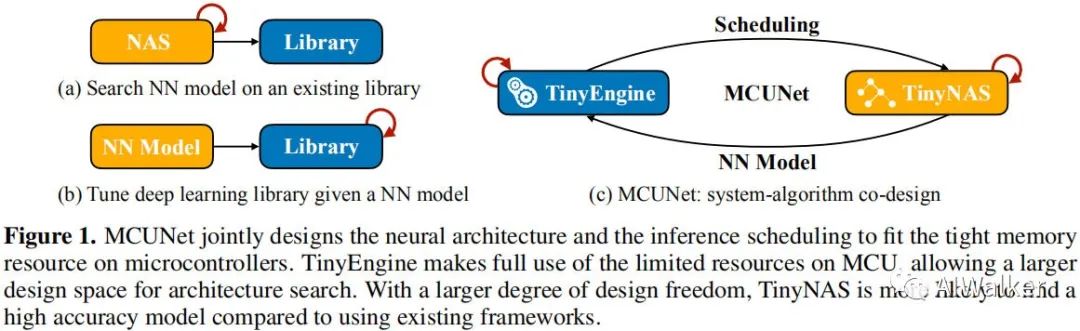
不同于云端或者手机端设备,微处理器是一种“裸设备”,它不具有操作系统。所以需要同时进行网络架构与推理库的设计以更高效的管理有限的资源并是配合内存与存储负载。而现有的NAS或手工网络架构往往聚焦于GPU端或手机端,它们仅仅对FLOPs或者推理延迟进行优化,所得模型并不适合于微处理器。
该文提出了一种系统-模型联合设计的方案MCUNet,它可以在微处理器上处理ImageNet级别的任务。为解决微处理器上稀缺内存问题,作者联合优化TinyNAS与TinyEngine以降低内存占用。TinyNAS的设计基于这样的一个假设:a search space that can accommodate higher FLOPs under memory constraint can produce better model。为处理微处理器上非常紧张的资源约束,还需要设计一种内存高效的推理库以消除不必要的内存占用。TinyEngine的改进为:TinyEngine improves over the existing inference library with code generator-based compilation method to eliminate memory overhead。它可以降低2.7x的内存占用并提升22%推理速度。
Method
下图给出了作者所设计MCUNet联合设计方案与传统方案的对比示意图,相比传统方案,MCUNet可以更好的利用微处理器的资源。
TinyNAS
TinyNAS是一种两阶段的NAS方法,它首先优化搜索空间以适配不同的资源约束,然后在优化空间上进行网络架构搜索。经由该优化空间,它可以显著的提升最终模型的精度。在搜索空间方面,作者对输入分辨率和网络宽度方面进行搜索。输入分辨率范围,网络宽度因子为。大概有108个可能的搜索空间配置,每个搜索空间配置包含个子网络。第一阶段的目的是寻找具有最高精度且可以满足资源约束的搜索空间。下图给出了不同配置搜索空间的FLOPs与CDF示意图。
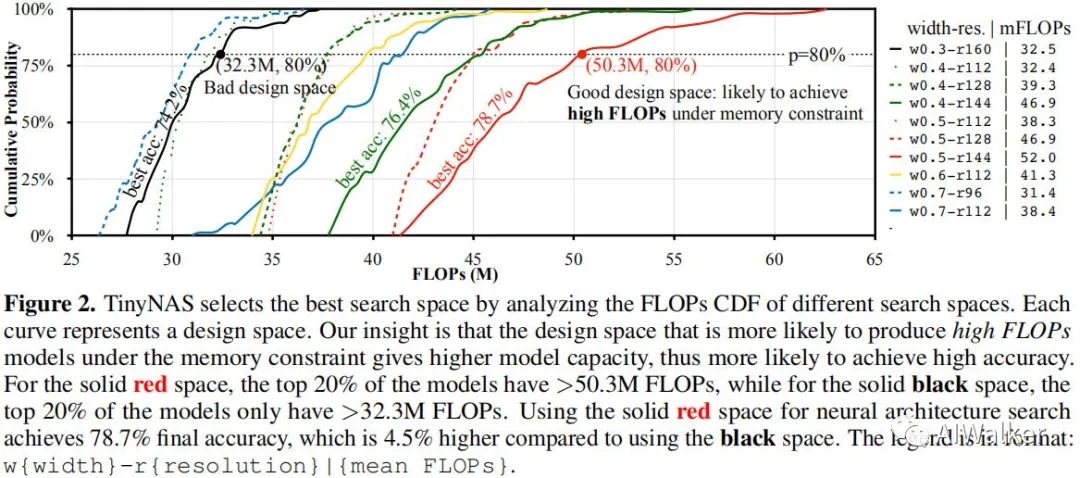
在完成搜索空间确认后,第二阶段的目的是进行网络架构的搜索。采用采用one-shotNAS技术进行网路架构搜索。关于one-shot NAS部分建议各位同学去看一下Face++的《Single Path One-Shot Neural Architecture Search with Uniform Sampling》一文。
TinyEngine
研究人员往往假设:不同的深度学习框架仅仅影响推理速度而不会影响模型精度。然而,对于TinyML而言,推理库的高效性不仅影响推理速度,同时还会影响搜索到的模型精度。一个好的推理框架可以更充分的利用MUC的有效资源,避免内存占用,从而允许更大的架构设计空间,而更大的架构设计空间也意味着更高精度模型。因此,作者将TinyNAS与TinyEngine进行协同设计,以获得内存高效的推理库。
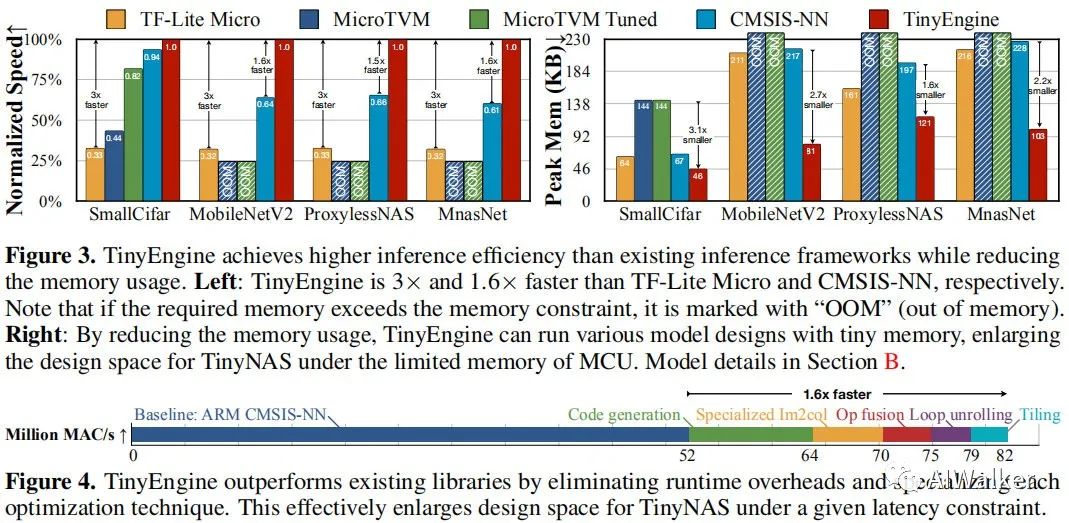
上图给出了TinyEngine与现有推理框架在不同维度的对比。现有的TF-Lite Micro与CMSIS-NN是解释型推理框架,它们易于跨平台部署,但同时需要额外的内存(在MCU上内存是最昂贵的资源)保存架构的元信息(比如网络架构参数);相反TinyEngine仅仅聚焦于MCU设备,采用code generator-based进行编译。它不仅避免了运行时解释耗时,同时释放了额外的内存占用,从而允许更大的模型。相比CMSIS-NN,TinyEngine可以降低2.7x内存占用,提升22%推理速度。
与此同时TinyEngine的库文件非常轻量,这使得其非常适合于MCU。不同于TF-Lite Micro需要准备所有的操作(比如conv、softmax)以支持跨模型推理;而TinyEngine仅仅需要编译必要的操作。下图给出了TF-Lite Micro、CMSIS-NN与TinyEngien的大小对比。
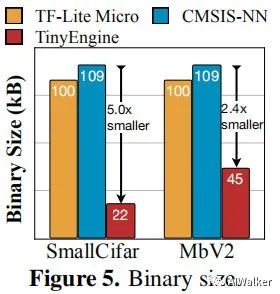
TinyEngine为不同层制作特定的核优化方案:loops tiling is based on the kernel size and available memory; inner loop unrolling is also specialized for different kernel size。同时,TinyEngine还进行了操作合并,比如Conv+PAd+BN+ReLU。上述优化方案可以为模型推理带来22%的加速。
Experiments
在实验方面,作者选用了ImageNet、Visual Wake Word以及Speech Command三个数据集。ImageNet代表了大尺度图像分类任务,VWW用于判别是否有人存在,而SC代表了主流的微处理器应用场景:语音唤醒。
在模型部署方面,作者采用int8线性量化后部署。MCU选型为STM32F746,它具有320kb SRAM与1MB Flash。直接上结果咯。Table2的结果很震撼哦,最优模型可达60.1%精度。


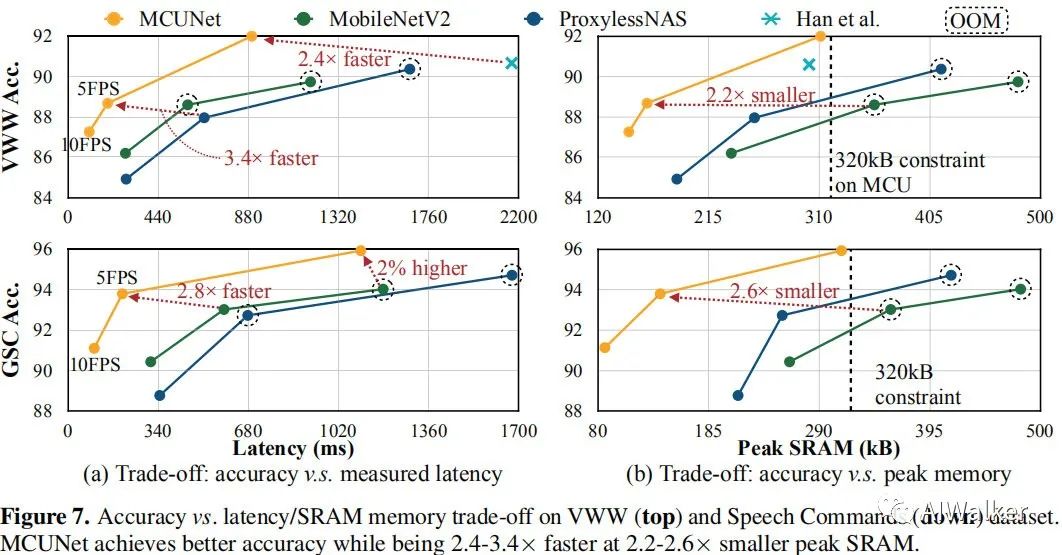
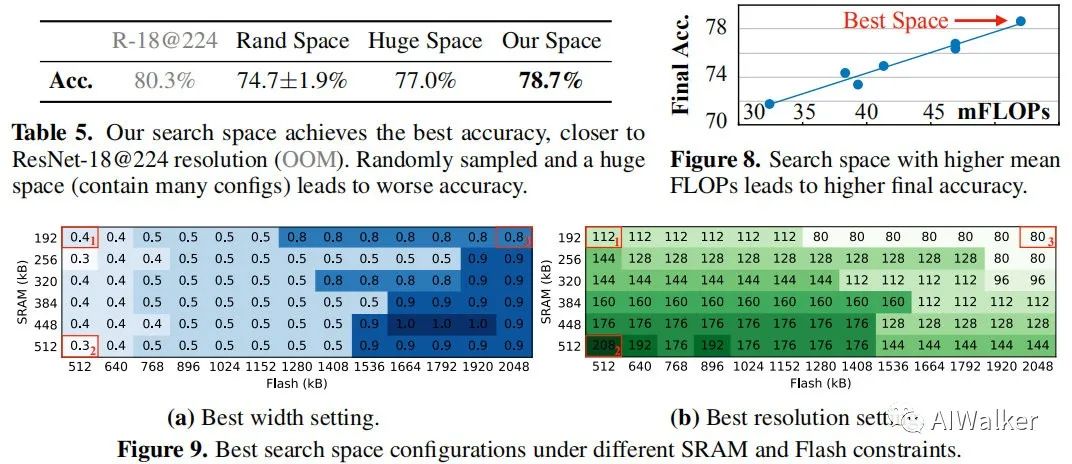
好了,全文到底结束。上面已经对该文的核心进行了简单的介绍。但美中不足的是:该文尚未开源。
Conclusion
作者提出了一种网络架构搜索与推理库协同设计方案MCUNet,它可以使得深度学习在微型硬件设备(IoT)上运行。所提方案在现有微处理器产品中取得前所未有了70.2%(ImageNet)的精度,同时具有更快的推理速度。该研究意味着:永远在线的IoT设备上微型机器学习时代已经到来了。
最后的最后求一波分享!
YOLOv4 trick相关论文已经下载并放在公众号后台
关注“AI算法与图像处理”,回复 “200714”获取
个人微信 请注明:地区+学校/企业+研究方向+昵称 如果没有备注不拉群!
