
【关于 Bert 越大越精序列】那些的你不知道的事(二)
作者简介
作者:杨夕
介绍:本项目是作者们根据个人面试和经验总结出的搜索引擎(search engine) 面试准备的学习笔记与资料,该资料目前包含 搜索引擎各领域的 面试题积累。
NLP 百面百搭 地址:https://github.com/km1994/NLP-Interview-Notes
推荐系统 百面百搭 地址:https://github.com/km1994/RES-Interview-Notes 手机版推荐系统百面百搭
搜索引擎 百面百搭 地址:https://github.com/km1994/search-engine-Interview-Notes 【编写ing】
NLP论文学习笔记:https://github.com/km1994/nlp_paper_study
推荐系统论文学习笔记:https://github.com/km1994/RS_paper_study
GCN 论文学习笔记:https://github.com/km1994/GCN_study
关注公众号 【关于NLP那些你不知道的事】 加入 【NLP && 推荐学习群】一起学习!!!



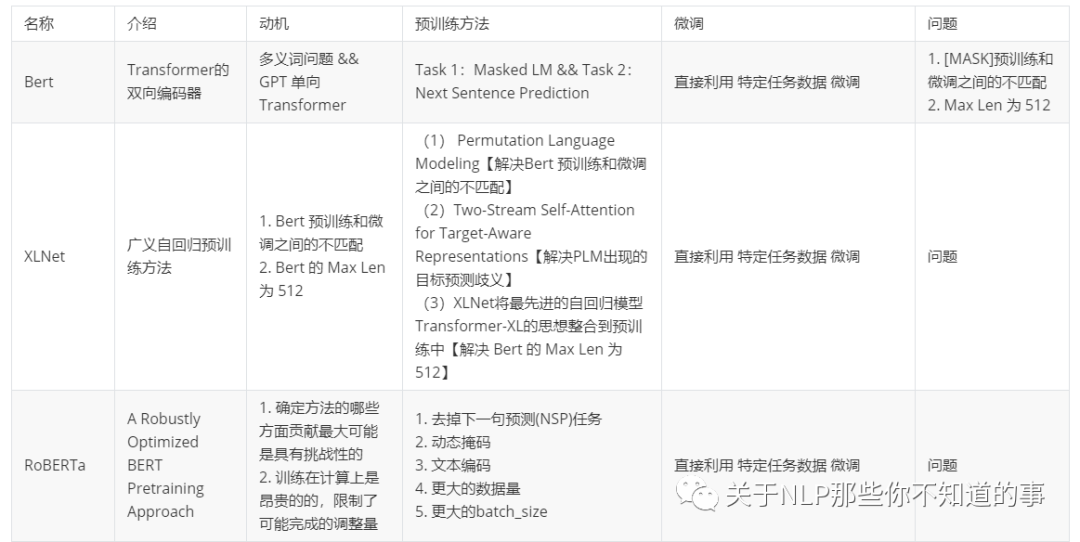

四、ELECTRA
论文名称:《ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generator》
论文:https://arxiv.org/abs/2003.10555
代码:https://github.com/google-research/electra
4.1 【ELECTRA】动机
Bert MLM 方式:在训练Bert的时候,在输入上操作把15%的词语给替换成Mask,然后这其中有80%是Mask,有10%是替换成其他词语,最后剩下10%保持原来的词语。
问题:可以看到,Bert的训练中,每次相当于只有15%的输入上是会有loss的,而其他位置是没有的,这就导致了每一步的训练并没有被完全利用上,导致了训练速度慢。换句话说,就是模型只学习到 15%的 token 信息;
4.2 【ELECTRA】介绍
提出了一种更有效的样本预训练任务,称为替换令牌检测。我们的方法不是掩盖输入,而是通过使用从 small generator network 采样的合理替代物替换一些令牌来破坏输入。然后,我们训练一个判别模型,该模型预测损坏的输入中的每个标记是否被生成器采样器代替,而不是训练一个预测损坏的令牌的原始身份的模型。
4.3 【ELECTRA】核心任务
核心:将生成式的Masked language model(MLM)预训练任务改成了判别式的Replaced token detection(RTD)任务,判断当前token是否被语言模型替换过;
思路:利用一个基于MLM的Generator来替换example中的某些个token,然后丢给Discriminator来判别
4.4 【ELECTRA】判别器 & 生成器
如下图所示,首先会训练一个生成器来生成假样本,然后Electra去判断每个token是不是被替换了。
4.5 【ELECTRA】算法流程
Generator G:
输入经过随机选择设置为[MASK];
输入给 G,G 负责把[MASK]变成替换过的词;
Discriminator D:
预测 输入的句子 每个位置上的词语是否被替换过;
注:
Discriminator是训练完之后我们得到的预训练模型,Generator在训练完之后就没有用了
五、ERNIE 1.0
论文名称:《ERNIE: Enhanced Representation through Knowledge Integration》
论文:https://arxiv.org/pdf/1904.09223.pdf
代码:https://github.com/PaddlePaddle/ERNIE/tree/develop/ERNIE
5.1 【ERNIE 1.0】动机
原生BERT是采用随机【MASK】会让模型不能充分学习到语义信息,降低学习难度。
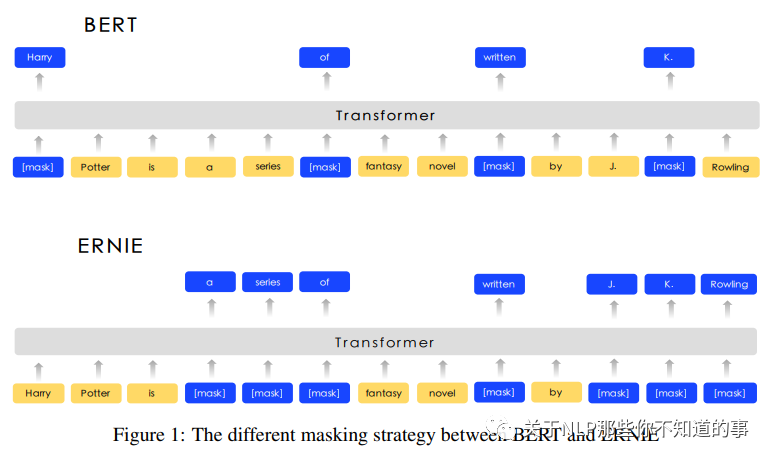
注:Harry Potter的Harry被【MASK】掉,这时候让模型去预测被【MASK】掉的token,这种情况下,模型很可能是根据Potter从而预测Harry(毕竟Harry Potter在语料中共同出现频率的比较高),在这种情况下,模型也许并不是根据Harry Potter和J.K.Rowling的关系来预测出Harry的,换个角度,这样BERT学到的是规则,而并非语义信息。
5.2 【ERNIE 1.0】预训练
5.2.1 Knowledge Integration
针对 MASK 存在问题,ERNIE 1.0 将 MASK 分为三部分:
Basic-level Masking:与BERT一样;
Entity-level Masking:把实体作为一个整体【MASK】,例如 J.K.Rowling 这个词作为一个实体,被一起【MASK】;
Phrase-Level Masking:把短语作为一个整体【MASK】,如 a series of 作为一个短语整体,被一起【MASK】。

5.2.2 Dialogue Language Model(DLM)
在 Bert 已有的预训练任务中,加入了 Dialogue Language Model 任务:
作用:ERNIE 1.0 通过引入 多轮问答数据,使 ERNIE 学习到对话中的隐含关系,增加模型的语义表达能力。
具体操作:把里面的单个token、实体、短语【MASK】掉,然后预测它们,另外在生成预训练数据的时候,有一定几率用另外的句子替代里面的问题和答案,所以模型还要预测是否是真实的问答对。
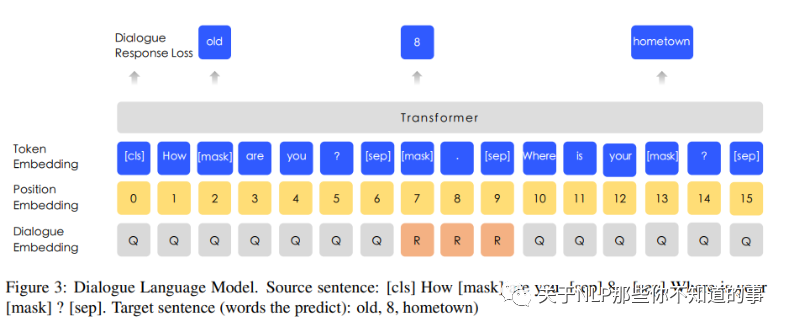
注:注意看Segment Embedding被Dialogue Embedding代替了,但其它结构跟MLM模型是一样的,所以DLM任务可以和MLM任务联合训练,即Dialogue Embedding只会跟随DLM任务更新,Segment Embedding指挥跟随MLM任务跟新,而模型其它参数是随着DLM任务和MLM任务一起更新。
六、ERNIE 2.0
论文名称:《ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding》
论文:https://ojs.aaai.org//index.php/AAAI/article/view/6428
代码:https://github.com/PaddlePaddle/ERNIE
6.1 【ERNIE 2.0】动机
近两年,以 BERT、XLNet 为代表的无监督预训练技术在多个自然语言处理任务上取得了技术突破。基于大规模数据的无监督预训练技术在自然语言处理领域变得至关重要。
百度发现,之前的工作主要通过词或句子的共现信号,构建语言模型任务进行模型预训练。例如,BERT 通过掩码语言模型和下一句预测任务进行预训练。XLNet 构建了全排列的语言模型,并通过自回归的方式进行预训练。
然而,除了语言共现信息之外,语料中还包含词法、语法、语义等更多有价值的信息。例如,人名、地名、机构名等词语概念知识,句子间顺序和距离关系等结构知识,文本语义相似度和语言逻辑关系等语义知识。那么如果持续地学习各类任务,模型的效果能否进一步提升?这就是 ERNIE 2.0 希望探索的。
6.2 【ERNIE 2.0】架构
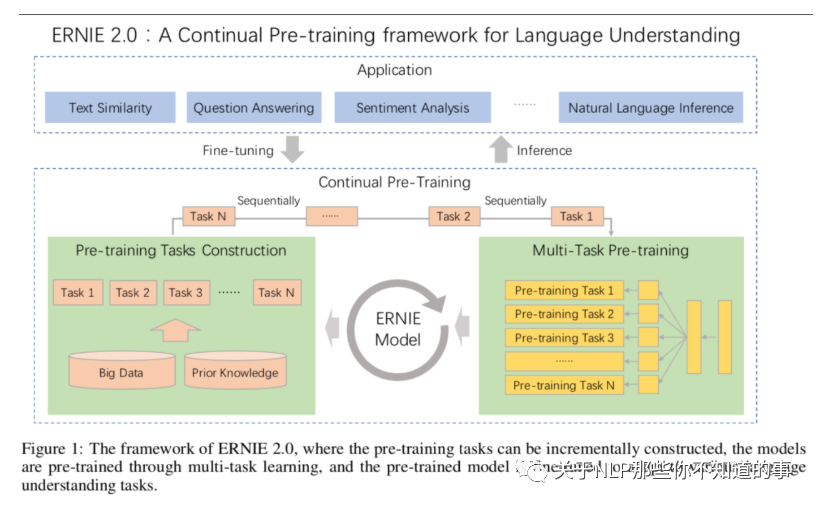
ERNIE 2.0 中有一个很重要的概念便是连续学习(Continual Learning),连续学习的目的是在一个模型中顺序训练多个不同的任务以便在学习下个任务当中可以记住前一个学习任务学习到的结果。通过使用连续学习,可以不断积累新的知识,模型在新任务当中可以用历史任务学习到参数进行初始化,一般来说比直接开始新任务的学习会获得更好的效果
6.3 【ERNIE 2.0】预训练
6.3.1 预训练连续学习
ERNIE 2.0 提出三种策略来让模型同时学习3个任务:
策略一:Multi-task Learning,就是让模型同时学这3个任务,具体的让这3个任务的损失函数权重双加,然后一起反向传播更新参数;
策略二:Continual Learning,先训练任务1,再训练任务2,再训练任务3,这种策略的缺点是容易遗忘前面任务的训练结果,最后训练出的模型容易对最后一个任务过拟合;
策略三:Sequential Multi-task Learning,连续多任务学习,即第一轮的时候,先训练任务1,但不完全让它收敛训练完,第二轮,一起训练任务1和任务2,同样不让模型收敛完,第三轮,一起训练三个任务,直到模型收敛完。
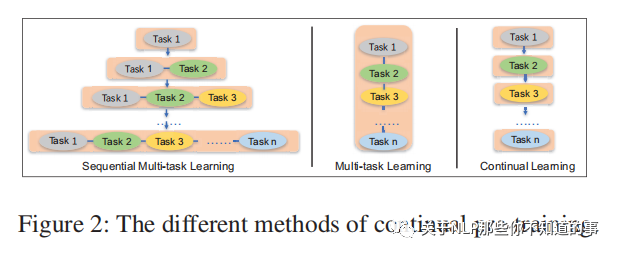
论文采用策略三的思想。具体的,如下图所示,每个任务有独立的损失函数,句子级别的任务可以和词级别的任务一起训练,相信做过联合训练的同学并不陌生。
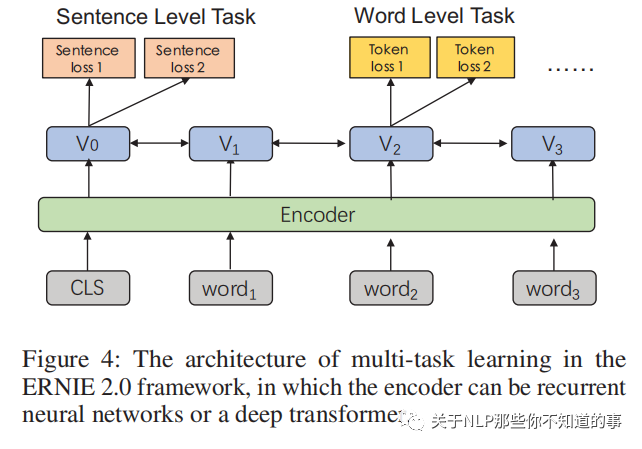
6.3.2 更多的无监督预训练任务
由于是多任务学习,模型输入的时候额外多了一个Task embedding。
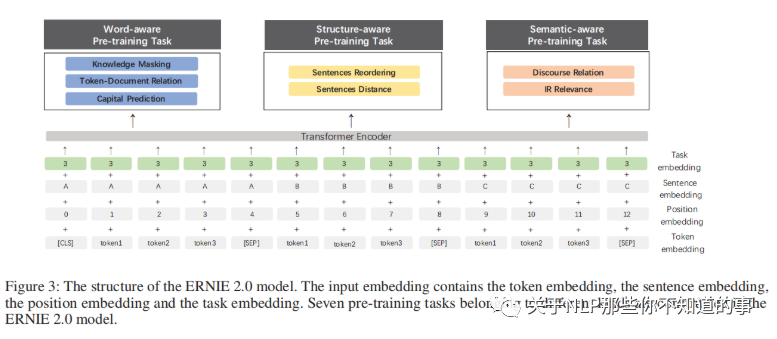
具体的三种类型的无监督训练任务是哪三种呢?每种里面又包括什么任务呢?
任务一:词法级别预训练任务
Knowledge Masking Task:这任务同ERNIE 1.0一样,把一些字、短语、实体【MASK】掉,预测【MASK】词语;
Capitalization Prediction Task:预测单词是大写还是小写;
Token-Document Relation Prediction Task:预测在段落A中出现的token,是否在文档的段落B中出现。
任务二:语言结构级别预训练任务
Sentence Reordering Task:把文档中的句子打乱,预测正确顺序;
Sentence Distance Task:分类句子间的距离(0:相连的句子,1:同一文档中不相连的句子,2:两篇文档间的句子)。
任务三:语句级别预训练任务
Discourse Relation Task:计算两句间的语义和修辞关系;
IR Relevance Task:短文本信息检索关系,搜索数据(0:搜索并点击,1:搜素并展现,2:无关)。
七、ERNIE-T
论文名称:《ERNIE: Enhanced Language Representation with Informative Entities》
论文:https://arxiv.org/pdf/1905.07129.pdf
代码:https://github.com/thunlp/ERNIE
7.1 【ERNIE-T】动机
例如下面的句子,我们的任务目标是对“Bob Dylan”进行实体类别识别(Entity Typing)。所谓Entity Typing,是指给定一个实体指代(entity mention),根据实体的上下文信息来对实体的具体语义类别进行预测。例如在示例1中,Bob Dylan的entity typing的值为“songwriter”和“writer”,因为“Blowin' in the wind”是一首歌,“Chronicies:Volume One”是一本书。对于BERT来说,仅仅通过上下文是很难预测出正确的结果的,因为它没有关于这两个作品类别的信息。
但是如果我们引入了实体额外的知识图谱呢,如图1。根据图谱提供的信息,我们知道了Blowin' in the wind”是一首歌以及“Chronicies:Volume One”是一本书,那么我们再对“Boby Dylan”进行实体类别识别时就容易多了。
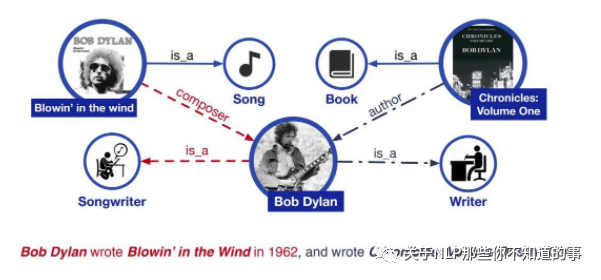
示例1:Bob Dylan wrote Blowin' in the Wind in 1962, and wrote Chronicies: Volume One in 2004.
6.2 【ERNIE-T】架构
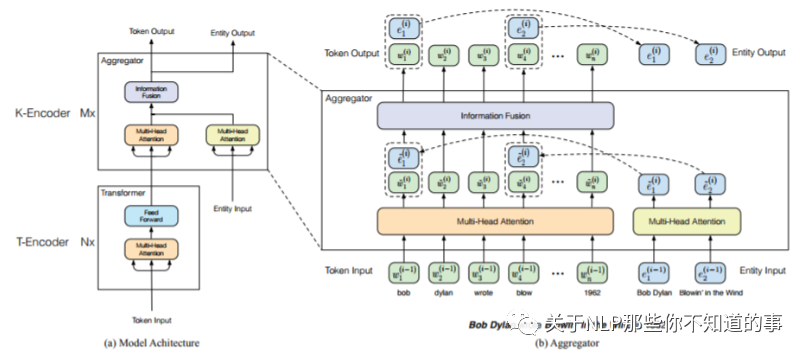
6.3 【ERNIE-T】预训练
6.3.1 引入知识图谱
ERNIE-T 引入知识图谱来增强预训练模型的语义表达能力,其实预训练时就是在原来bert的基础上增加了一个实体对齐的任务。
6.3.2 异构信息融合
因为词向量和实体的知识图谱是两个异构的信息,那么如何设计一个网络来融合这两个信息则是我们需要解决的首要问题。如图2所示,ERNIE-T由两个模块组成,它们是底层文本编码器(underlying textual encoder,T-Encoder)和上层知识编码器(upper knowledge encoder,K-Encoder)。
6.3.3 dAE
提出了随机mask tokens-entity中的entity,然后去预测该位置对应的entity,本质上和MLM(mask language model)任务一致,都属于去噪自编码。具体mask的细节:
5%的tokens-entity对采用随机用其他的entity来替换,这主要是引入噪声,因为在实际的任务中也存在这种情况。
15%的tokens-entity对采用随机maskentity,然后来预测这个entity。
80%保持正常。
这篇论文主要的工作就是增加了这个任务,另外也提出了在实体类型和关系抽取两个任务上新的预训练方式,具体如下图:
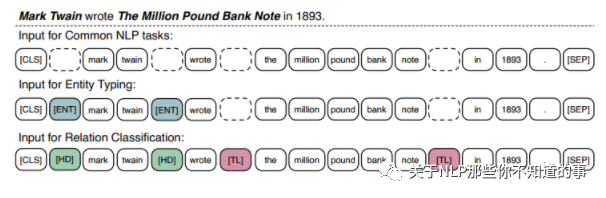
就是引入了一些特殊的token来表明另外一些特殊token的身份。因为引入了实体对齐任务,因此该模型在一些和知识图谱相关的下游任务上要优于bert。
参考
《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
《XLNet: Generalized Autoregressive Pretraining for Language Understanding》
《RoBERTa: A Robustly Optimized BERT Pretraining Approach》
《ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generator》
《ERNIE: Enhanced Representation through Knowledge Integration》
《ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding》
《ERNIE: Enhanced Language Representation with Informative Entities》
所有文章
五谷杂粮
NLP百面百搭
Rasa 对话系统
知识图谱入门
转载记录
