
hystrix-go 使用与原理

开篇
这周在看内部一个熔断限流包时,发现它是基于一个开源项目 hystrix-go 实现了,随即看了两天的源码,因此有了这篇文章。
Hystrix
Hystrix 是由 Netflex 开发的一款开源组件,提供了基础的熔断功能。 Hystrix 将降级的策略封装在 Command 中,提供了 run 和 fallback 两个方法,前者表示正常的逻辑,比如微服务之间的调用……,如果发生了故障,再执行 fallback 方法返回结果,我们可以把它理解成保底操作。如果正常逻辑在短时间内频繁发生故障,那么可能会触发断路,也就是之后的请求不再执行 run, 而是直接执行 fallback。更多关于 Hystrix 的信息可以查看 https://github.com/Netflix/Hystrix,而hystrix-go 则是用 go 实现的 hystrix 版,更确切的说,是简化版。只是上一次更新还是 2018 年 的一次 pr, 也就毕业了?
为什么需要这些工具?
比如一个微服务化的产品线上,每一个服务都专注于自己的业务,并对外提供相应的服务接口,或者依赖于外部服务的某个逻辑接口,就像下面这样。
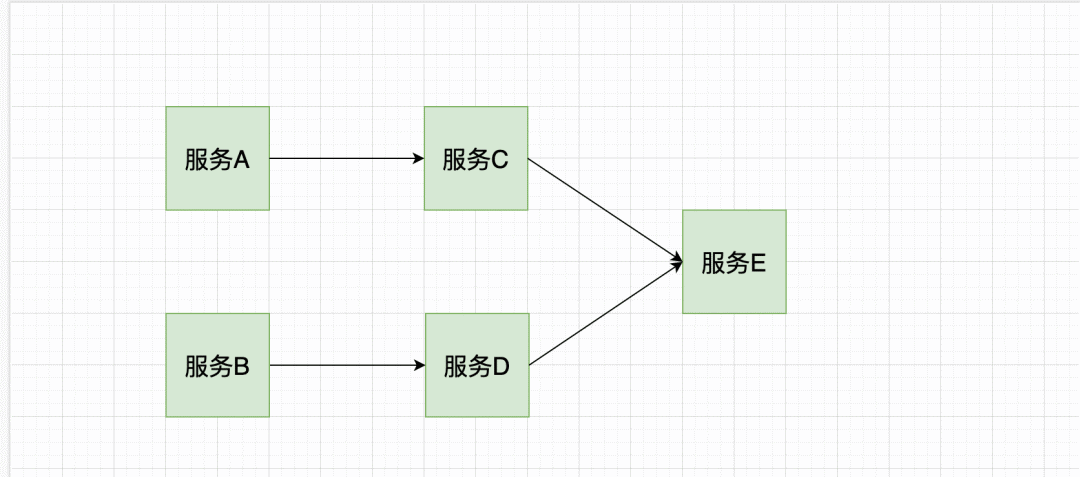
假设我们当前是 服务A,有部分逻辑依赖于 服务C,服务C 又依赖于 服务E, 当前微服务之间进行 rpc 或者 http 通信,假设此时 服务C 调用 服务 E 失败,比如由于网络波动导致超时或者服务 E 由于过载,服务E 已经 down 掉了。
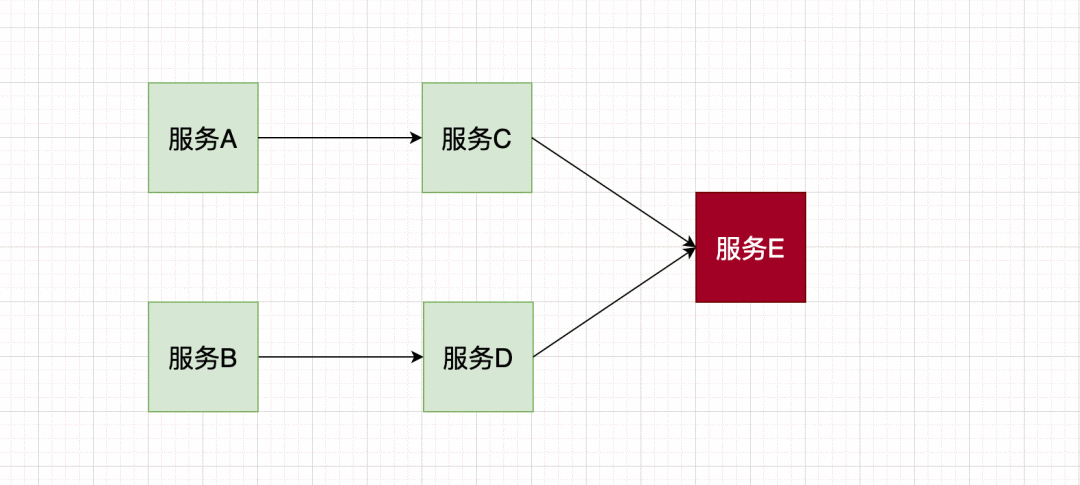
调用失败,一般会有失败重试等机制。但是再想想,假设服务 E 已然不可用的情况下,此时新的调用不断产生,同时伴随着调用等待和失败重试,会导致 服务 C 对服务 E 的调用而产生大量的积压,慢慢会耗尽服务 C 的资源,进而导致服务 C 也 down 掉,这样恶性循环下,会影响到整个微服务体系,产生雪崩效应。
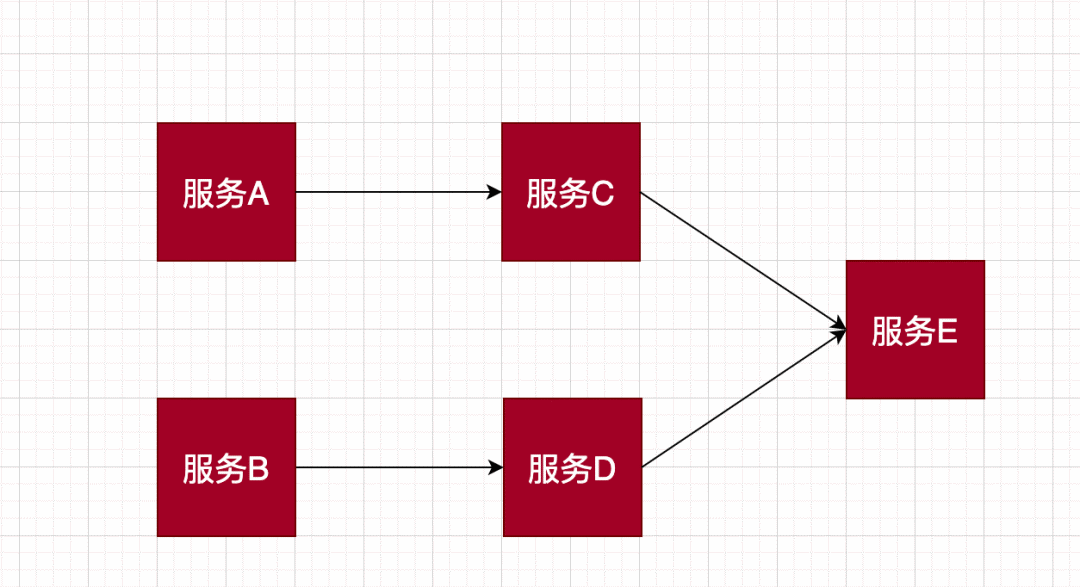
虽然导致雪崩的发生不仅仅这一种,但是我们需要采取一定的措施,来保证不让这个噩梦发生。而 hystrix-go 就很好的提供了 熔断和降级的措施。它的主要思想在于,设置一些阀值,比如最大并发数(当并发数大于设置的并发数,拦截)。错误率百分比(请求数量大于等于设置 的阀值,并且错误率达到设置的百分比时,触发熔断)以及熔断尝试恢复时间等。
使用
hystrix-go 的使用非常简单,你可以调用它的 Go 或者 Do 方法,只是 Go 方法是异步的方式。而 Do 方法是同步方式。我们从一个简单的例子开启。
_ = hystrix.Do("wuqq", func() error {// talk to other services_, err := http.Get("https://www.baidu.com/")if err != nil {fmt.Println("get error:%v",err)return err}return nil}, func(err error) error {fmt.Printf("handle error:%v\n", err)return nil})
Do 函数需要三个参数,第一个参数 commmand 名称,你可以把每个名称当成一个独立当服务,第二个参数是处理正常的逻辑,比如 http 调用服务,返回参数是 err。如果处理或者调用失败,那么就执行第三个参数逻辑, 我们称为保底操作。假设服务错误率过高而导致熔断器开启,那么之后的请求也直接回调此函数。
既然熔断器是按照配置的规则而进行是否开启的操作,那么我们当然可以设置我们想要的值。
hystrix.ConfigureCommand("wuqq", hystrix.CommandConfig{Timeout: int(3 * time.Second),MaxConcurrentRequests: 10,SleepWindow: 5000,RequestVolumeThreshold: 10,ErrorPercentThreshold: 30,})_ = hystrix.Do("wuqq", func() error {// talk to other services_, err := http.Get("https://www.baidu.com/")if err != nil {fmt.Println("get error:%v",err)return err}return nil}, func(err error) error {fmt.Printf("handle error:%v\n", err)return nil})
稍微解释一下上面配置的值含义:
Timeout: 执行
command的超时时间。MaxConcurrentRequests:
command的最大并发量 。SleepWindow:当熔断器被打开后,
SleepWindow的时间就是控制过多久后去尝试服务是否可用了。RequestVolumeThreshold:一个统计窗口 10 秒内请求数量。达到这个请求数量后才去判断是否要开启熔断
ErrorPercentThreshold:错误百分比,请求数量大于等于
RequestVolumeThreshold并且错误率到达这个百分比后就会启动熔断
当然你不设置的话,那么自动走的默认值。

我们再来看一个简单的例子:
package mainimport ("fmt""github.com/afex/hystrix-go/hystrix" "net/http" "time")type Handle struct{}func (h *Handle) ServeHTTP(r http.ResponseWriter, request *http.Request) {h.Common(r, request)}func (h *Handle) Common(r http.ResponseWriter, request *http.Request) {hystrix.ConfigureCommand("mycommand", hystrix.CommandConfig{Timeout: int(3 * time.Second),MaxConcurrentRequests: 10,SleepWindow: 5000,RequestVolumeThreshold: 20,ErrorPercentThreshold: 30,})msg := "success"_ = hystrix.Do("mycommand", func() error {_, err := http.Get("https://www.baidu.com")if err != nil {fmt.Printf("请求失败:%v", err)return err}return nil}, func(err error) error {fmt.Printf("handle error:%v\n", err)msg = "error"return nil})r.Write([]byte(msg))}func main() {http.ListenAndServe(":8090", &Handle{})}
我们开启了一个 http 服务,监听端口号 8090,所有请求的处理逻辑都在 Common 方法中,在这个方法中,我们主要是发起一次 http 请求,请求成功响应 success, 如果失败,响应失败原因。
我们再写另一个简单程序,并发 11 次的请求 8090 端口。
package mainimport ("fmt""io/ioutil""net/http""sync""time")var client *http.Clientfunc init() {tr := &http.Transport{MaxIdleConns: 100,IdleConnTimeout: 1 * time.Second,}client = &http.Client{Transport: tr}}type info struct {Data interface{} `json:"data"`}func main() {var wg sync.WaitGroupfor i := 0; i < 11; i++ {wg.Add(1)go func(int2 int) {defer wg.Done()req, err := http.NewRequest("GET", "http://localhost:8090", nil)if err != nil {fmt.Printf("初始化http客户端处错误:%v", err)return}resp, err := client.Do(req)if err != nil {fmt.Printf("初始化http客户端处错误:%v", err)return}defer resp.Body.Close()nByte, err := ioutil.ReadAll(resp.Body)if err != nil {fmt.Printf("读取http数据失败:%v", err)return}fmt.Printf("接收到到值:%v\n", string(nByte))}(i)}wg.Wait()fmt.Printf("请求完毕\n")}
由于我们配置 MaxConcurrentRequests 为 10,那么意味着还有个 g 请求会失败:

和我们想的一样。
接着我们把网络断开,并发请求改成 10 次。再次运行程序并发请求 8090 端口,此时由于网络已关闭,导致请求百度失败:
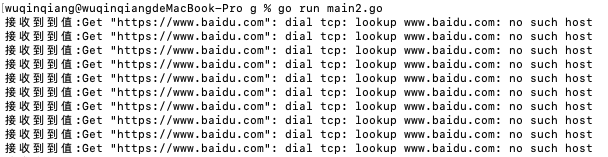
接着继续请求:
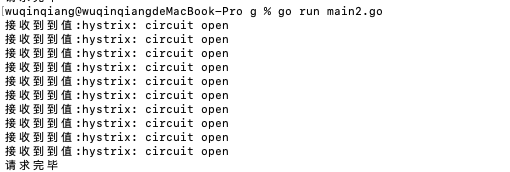
熔断器已开启,上面我们配置的 RequestVolumeThreshold 和 ErrorPercentThreshold 生效。
然后我们把网连上,五秒后 (SleepWindow 的值) 继续并发调用,当前熔断器处于半开的状态,此时请求允许调用依赖,如果成功则关闭,失败则继续开启熔断器。
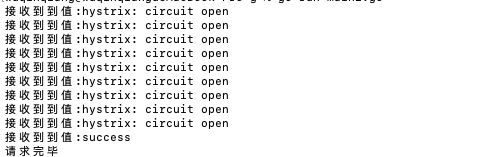
可以看到,有一个成功了,那么此时熔断器已关闭,接下来继续运行函数并发调用:
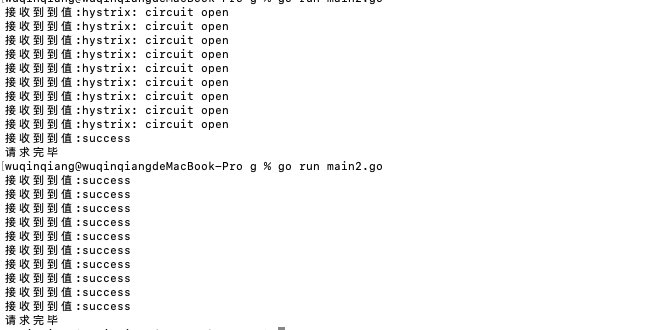
可以看到,10 个都已经是正常成功的状态了。
那么问题来了,为什么最上面的图只有一个是成功的?5 秒已经过了,并且当前网络正常,应该是 10 个请求都成功,但是我们看到的只有一个是成功状态。通过源码我们可以找到答案:
具体逻辑在判断当前请求是否可以调用
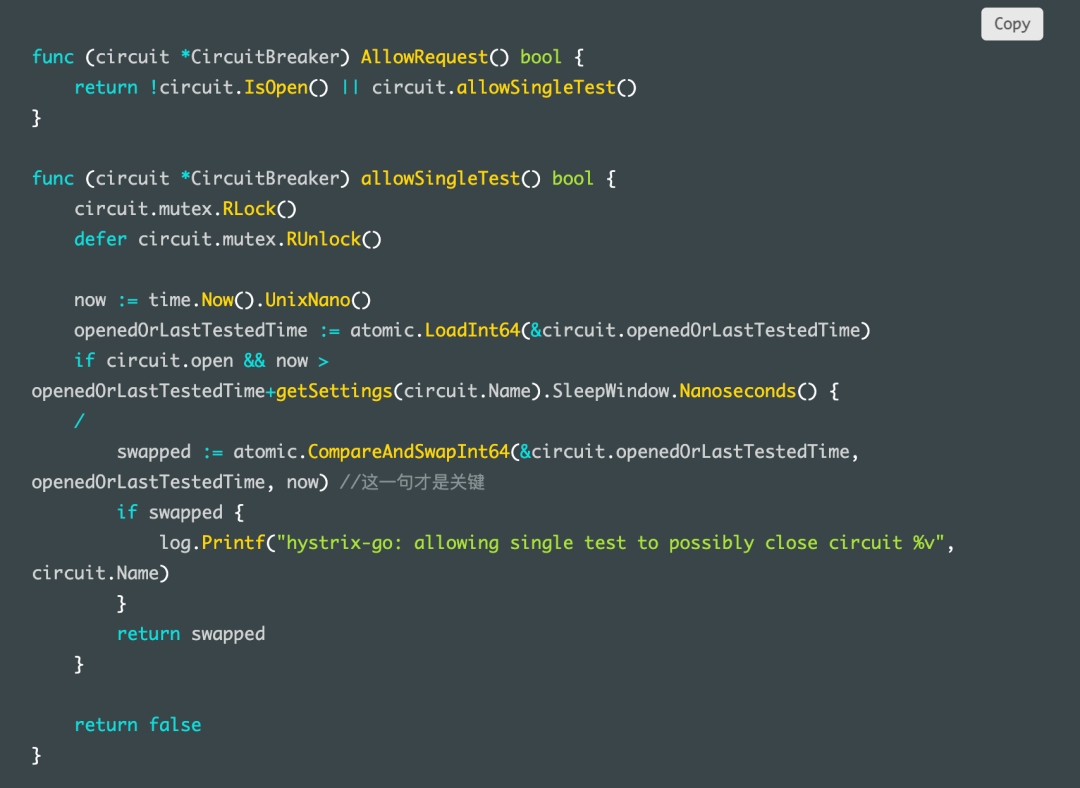
这段代码首先判断了熔断器是否开启,并且当前时间大于 上一次开启熔断器的时间 + SleepWindow 的时间,如果条件都符合的话,更新此熔断器最新的 openedOrLastTestedTime , 是通过 CompareAndSwapInt64 原子操作完成的,意味着必然只会有一个成功。
此时熔断器还是半开的状态,接着如果能拿到令牌,执行 run 函数(也就是 Do 传入的第二个简单封装后的函数),发起 http 请求,如果成功,上报成功状态,关闭熔断器。如果失败,那么熔断器依旧开启。


以上就是大体的流程讲解,本来想当一篇文章搞定,但是我又想好好梳理源码,再写下去文章太长了,因此花两篇文章来介绍,下一篇纯讲源码部分。
参考:https://www.cnblogs.com/li-peng/p/10997140.html。
推荐阅读