
机器学习 Tips:关于 Scikit-Learn 的 10 个小秘密
点击上方“数据管道”,选择“置顶星标”公众号
干货福利,第一时间送达


作者 | Rebecca Vickery
编译 | NewBeeNLP
写在前面
1. 内置数据集
make_regression()、make_blobs()和make_classification()生成合成数据集。所有加载实用程序都提供了返回已拆分为X(特征)和y(目标)的数据选项,以便它们可以直接用于训练模型。2. 获取公开数据集
datasets.fetch_openml,可以让您直接从openml.org网站[2]获取数据。这个网站包含超过21000个不同的数据集,可以用于机器学习项目。3. 内置分类器来训练baseline
DummyClassifier() 和用于基于回归问题的 DummyRegressor()。4. 内置绘图api
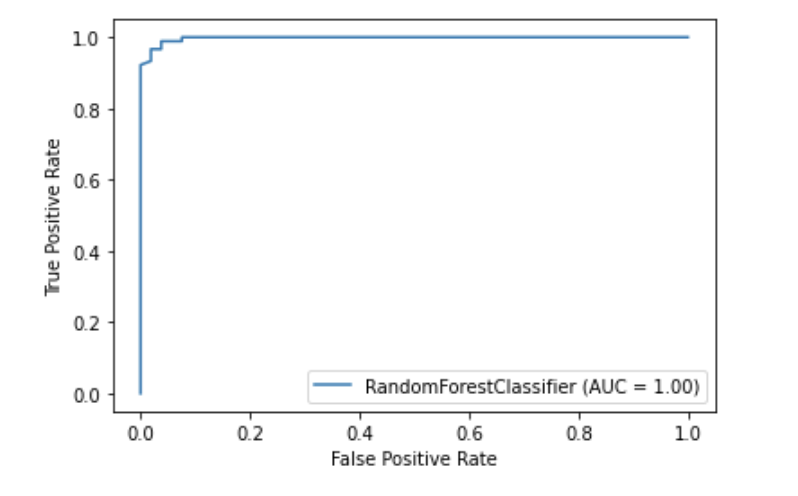
5. 内置特征选择方法
SelectPercentile(),该方法根据所选的统计方法选择性能最好的X百分位特征进行评分。6. 机器学习pipeline
7. ColumnTransformer
ColumnTransformer的函数,它允许你通过索引或指定列名来轻松指定要对哪些列应用最适当的预处理。8. 管道的HTML形式
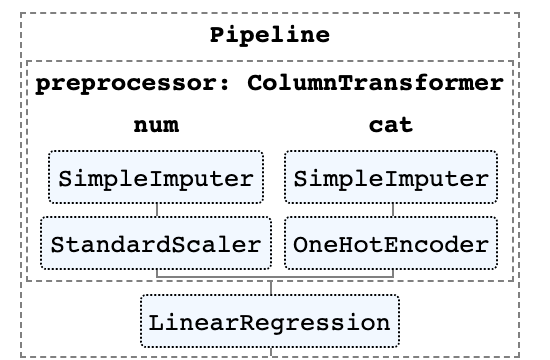
9. 可视化 树模型
plot_tree() 函数允许你创建决策树模型中的步骤图。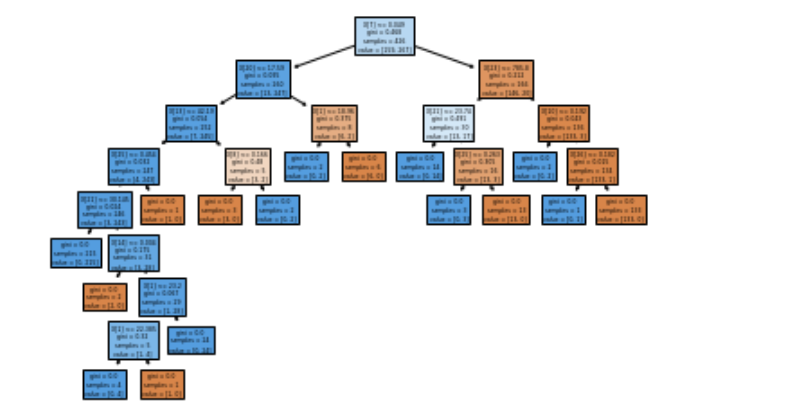
10. 丰富的第三方扩展
category-encoders库,它为分类特性提供了更大范围的预处理方法,以及ELI5包以实现更大的模型可解释性。这两个包也可以直接在Scikit-learn管道中使用。本文参考资料
toy和real-world数据集: https://scikit-learn.org/stable/datasets/index.html
[2]openml.org网站: https://www.openml.org/home
[3]HTML图表: https://scikit-learn.org/stable/modules/compose.html#visualizing-composite-estimator
评论