
MySQL 亿级数据分页的优化
POST domain/v1.0/module/method?order=condition&orderType=desc&offset=1800000&limit=500select * from t_name where c_name1='xxx' order by c_name2 limit 2000000,25;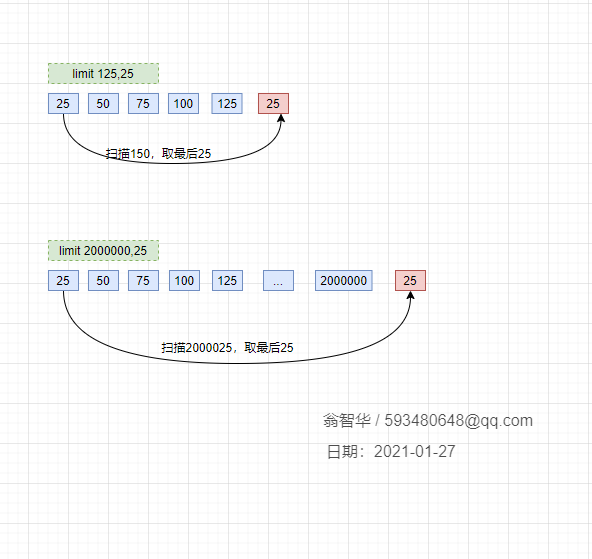
/*部门表,存在则进行删除 */
drop table if EXISTS dep;
create table dep(
id int unsigned primary key auto_increment,
depno mediumint unsigned not null default 0,
depname varchar(20) not null default "",
memo varchar(200) not null default ""
);
/*员工表,存在则进行删除*/
drop table if EXISTS emp;
create table emp(
id int unsigned primary key auto_increment,
empno mediumint unsigned not null default 0,
empname varchar(20) not null default "",
job varchar(9) not null default "",
mgr mediumint unsigned not null default 0,
hiredate datetime not null,
sal decimal(7,2) not null,
comn decimal(7,2) not null,
depno mediumint unsigned not null default 0
);/* 产生随机字符串的函数*/
DELIMITER $
drop FUNCTION if EXISTS rand_string;
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmlopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str = CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i+1;
END WHILE;
RETURN return_str;
END $
DELIMITER;
/*产生随机部门编号的函数*/
DELIMITER $
drop FUNCTION if EXISTS rand_num;
CREATE FUNCTION rand_num() RETURNS INT(5)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(100+RAND()*10);
RETURN i;
END $
DELIMITER;/*建立存储过程:往emp表中插入数据*/
DELIMITER $
drop PROCEDURE if EXISTS insert_emp;
CREATE PROCEDURE insert_emp(IN START INT(10),IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
/*set autocommit =0 把autocommit设置成0,把默认提交关闭*/
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO emp(empno,empname,job,mgr,hiredate,sal,comn,depno) VALUES ((START+i),rand_string(6),'SALEMAN',0001,now(),2000,400,rand_num());
UNTIL i = max_num
END REPEAT;
COMMIT;
END $
DELIMITER;
/*插入500W条数据*/
call insert_emp(0,5000000);/*建立存储过程:往dep表中插入数据*/
DELIMITER $
drop PROCEDURE if EXISTS insert_dept;
CREATE PROCEDURE insert_dept(IN START INT(10),IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i+1;
INSERT INTO dep( depno,depname,memo) VALUES((START+i),rand_string(10),rand_string(8));
UNTIL i = max_num
END REPEAT;
COMMIT;
END $
DELIMITER;
/*插入120条数据*/
call insert_dept(1,120);/*建立关键字段的索引:排序、条件*/
CREATE INDEX idx_emp_id ON emp(id);
CREATE INDEX idx_emp_depno ON emp(depno);
CREATE INDEX idx_dep_depno ON dep(depno);/*偏移量为100,取25*/
SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
from emp a left join dep b on a.depno = b.depno order by a.id desc limit 100,25;
/*偏移量为4800000,取25*/
SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
from emp a left join dep b on a.depno = b.depno order by a.id desc limit 4800000,25;[SQL]
SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
from emp a left join dep b on a.depno = b.depno order by a.id desc limit 100,25;
受影响的行: 0
时间: 0.001s
[SQL]
SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
from emp a left join dep b on a.depno = b.depno order by a.id desc limit 4800000,25;
受影响的行: 0
时间: 12.275s解决方案
/*子查询获取偏移100条的位置的id,在这个位置上往后取25*/
SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
from emp a left join dep b on a.depno = b.depno
where a.id >= (select id from emp order by id limit 100,1)
order by a.id limit 25;
/*子查询获取偏移4800000条的位置的id,在这个位置上往后取25*/
SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
from emp a left join dep b on a.depno = b.depno
where a.id >= (select id from emp order by id limit 4800000,1)
order by a.id limit 25;[SQL]
SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
from emp a left join dep b on a.depno = b.depno
where a.id >= (select id from emp order by id limit 100,1)
order by a.id limit 25;
受影响的行: 0
时间: 0.106s
[SQL]
SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
from emp a left join dep b on a.depno = b.depno
where a.id >= (select id from emp order by id limit 4800000,1)
order by a.id limit 25;
受影响的行: 0
时间: 1.541s/*记住了上次的分页的最后一条数据的id是100,这边就直接跳过100,从101开始扫描表*/
SELECT a.id,a.empno,a.empname,a.job,a.sal,b.depno,b.depname
from emp a left join dep b on a.depno = b.depno
where a.id > 100 order by a.id limit 25;
/*记住了上次的分页的最后一条数据的id是4800000,这边就直接跳过4800000,从4800001开始扫描表*/
SELECT a.id,a.empno,a.empname,a.job,a.sal,b.depno,b.depname
from emp a left join dep b on a.depno = b.depno
where a.id > 4800000
order by a.id limit 25;[SQL]
SELECT a.id,a.empno,a.empname,a.job,a.sal,b.depno,b.depname
from emp a left join dep b on a.depno = b.depno
where a.id > 100 order by a.id limit 25;
受影响的行: 0
时间: 0.001s
[SQL]
SELECT a.id,a.empno,a.empname,a.job,a.sal,b.depno,b.depname
from emp a left join dep b on a.depno = b.depno
where a.id > 4800000
order by a.id limit 25;
受影响的行: 0
时间: 0.000s·END·
作者:翁智华
来源:https://www.cnblogs.com/wzh2010/
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
最近给大家找了 Vue进阶
资源,怎么领取?
扫二维码,加我微信,回复:Vue进阶
注意,不要乱回复 没错,不是机器人 记得一定要等待,等待才有好东西
评论