TDSQL PG版分布式关系型数据库,是一款同时面向在线事务交易和MPP实时数据分析的高性能HTAP数据库系统。面对应用业务产生的不定性数据爆炸需求,不管是高并发交易还是海量实时数据分析,TDSQL PG版都能够轻松处理。目前TDSQL PG版已经在金融、保险、通信、税务、政务等多个行业的核心交易系统上线运行。
1. TDSQL PG版介绍

自2008年诞生,TDSQL PG版已有13年的发展历史,产品全面兼容PostgreSQL,高度兼容Oracle语法,采用无共享架构,在提供大型数据仓库处理能力的同时还能完整支持分布式事务。此外,TDSQL PG版的三权(安全、审计、管理)分立安全体系也充分满足企业对数据安全的需求。
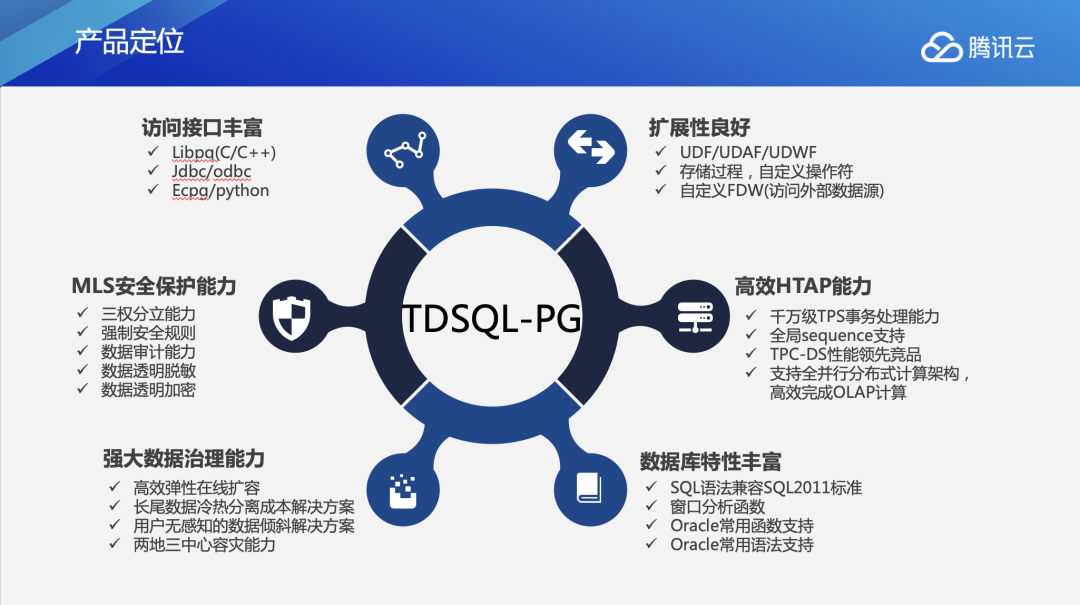
TDSQL PG版具有六个方面的产品特性:
- 访问接口丰富。支持C/C++、jdbc/odbc、python等各种常用语言接口。
- MLS安全保护能力。使用三权分立安全体系,支持数据透明脱敏加密。
- 高效HTAP能力。支持千万级TPS事务处理,全并行分布计算框架可高效完成OLAP计算。
- 强大数据治理能力。支持高效在线扩缩容、用户无感知数据rebalance和冷热数据分级存储,节省用户成本。
- 数据库特性丰富。支持各种窗口分析函数,高度兼容Oracle常用函数和语法。
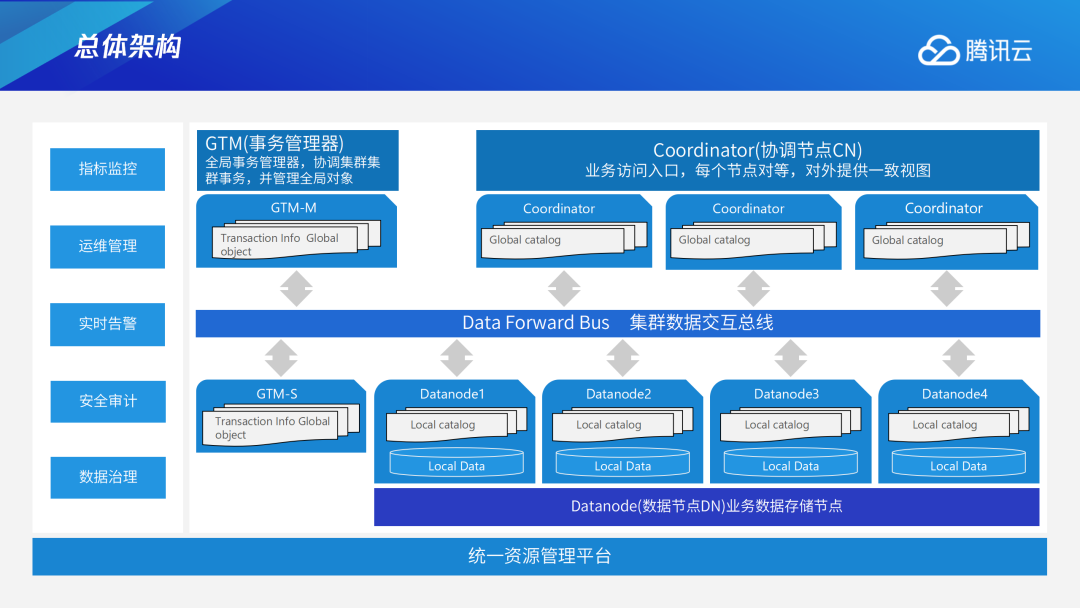
TDSQ PG版的应用场景满足以下业务特征,即:数据量上OLTP场景超过1T或OLAP场景超过5T;并发连接数超过2000,峰值业务100w/s;需要在线水平扩展能力,需要兼顾OLTP以及OLAP的HTAP场景,还需要严格的分布式事务保证。在满足这些业务特征的情况下,TDSQL PG版将会是合适的选择。此外,TDSQL PG版也适用于地理信息系统、实时高并发系统以及数据库国产化等场景。上图为TDSQL PG版的总体架构。左上角GTM是事务管理器,主要提供全局事务信息同时管理全局对象。右上角Coordinator是协调节点CN,主要提供业务访问入口,每个CN节点角色完全对等。下方是DN数据节点,即实际存储数据的地方,每个数据节点会存储一部分用户数据,所有的DN节点合起来形成完整的用户数据集。管控系统则负责整个集群的节点资源分配、监控告警、运维管理、自动化操作过程等工作。
2. 语法差异对比
2.1 数据类型
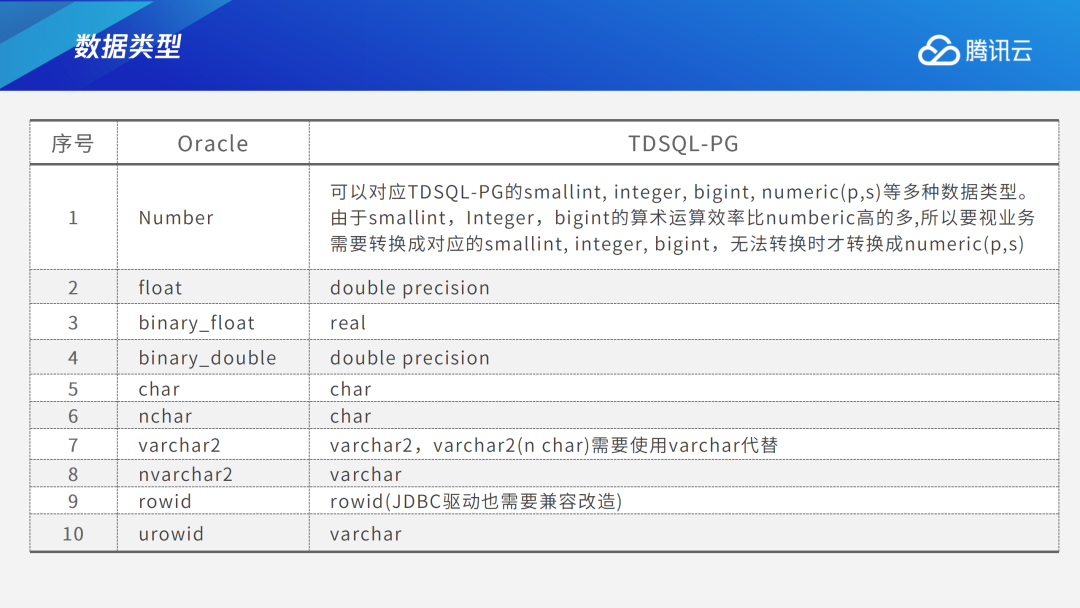
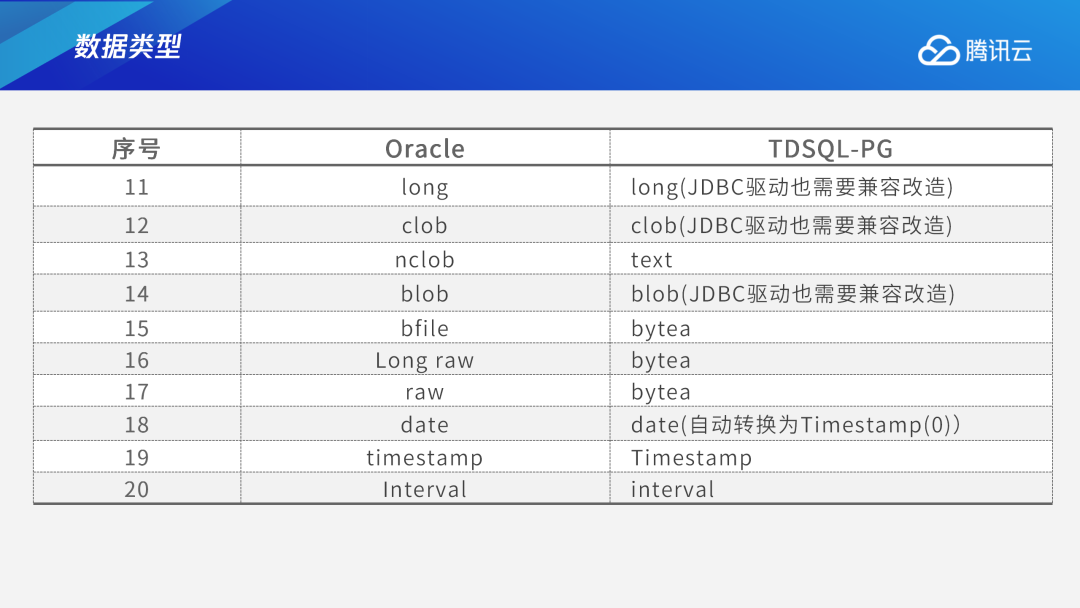
Oracle中的许多数据类型都可以与TDSQL PG版相互对应。比如Oracle中的number数据类型,对应到TDSQL PG版里,可以用smallint、integer、bigint、numeric(p,s)等多种数据类型进行类比替换。但受底层存储的影响,smallint、integer、bigint的算术运算效率比numberic高,因此要视业务需要转换成对应的smallint、integer、bigint,如若无法转换时才转换成numeric(p,s)。又例如Oracle中的float对应TDSQL PG版中的double precision,Oracle中的binary_float对应TDSQL-PG中的real,Oracle中的binary_double 对应TDSQL PG版中的double precision等,这些都是两者可对应的数据类型。此外Oracle中也有部分特有的数据库类型如rowid,PostgreSQL中并没有,但TDSQL PG版对此做了兼容,添加了这种数据类型。又如urowid ID在Oracle中是可变长的字符存储,TDSQL PG版中则可以用varchar进行替换。long、clob、blob等都是PostgreSQL中没有的数据类型。针对这些类型,TDSQL PG版做了大量兼容。如果用户需要在应用层用JDBC进行连接,JDBC驱动也需要同步进行兼容改造。Oracle中的date类型也和PostgreSQL不同,Oracle中可以精确到时分秒,而在PostgreSQL中只有年月日。为了兼容这一数据类型,TDSQL PG版在Oracle兼容开关打开的情况下底层用户定义时写Date类型,但下方会转成Timestamp(0),可以直接精确到秒级。(Oracle兼容开关打开就是Oracle模式,不打开就是PG模式)。2.2 存储过程语法差异
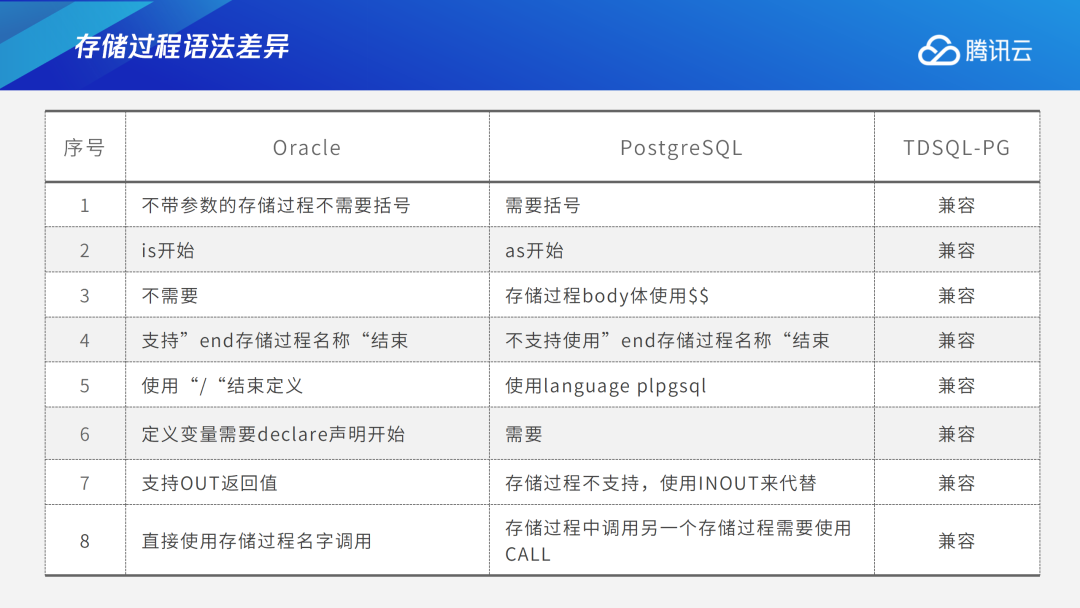
Oracle创建存储过程的语法与PostgreSQL有很大差异。比如用户在Oracle中创建存储过程,如果不需要输入参数、输出参数,则无需括号,但在PostgreSQL中则必须写括号,TDSQL PG版对此进行兼容,业务人员可根据需求选择写或不写。在函数中,Oracle是从is开始,PostgreSQL是从as开始,TDSQL PG版两者都支持。PostgreSQL中,函数存储过程body使用$$进行封装,Oracle则不需要,TDSQL PG版两者都支持。Oracle支持“end存储过程名称”结束,PostgreSQL则不支持,对此TDSQL PG版做了兼容。存储过程中,Oracle使用“/”来结尾,表示该函数存储过程创建完成,但在PostgreSQL中则采用language plpgsql,对此TDSQL PG版也做了兼容,用户可以用“/”进行结尾。在变量声明过程中,PostgreSQL需要指定Declare声明一个变量,但Oracle不需要,TDSQL PG版则完全兼容。存储过程中的输入、输出参数,Oracle支持IN、OUT和INOUT三种类型,但PostgreSQL不支持OUT,TDSQL PG版对此做了兼容,完整支持IN、OUT和INOUT三种类型。在调用方面,Oracle存储过程的调用支持三种形式:call后加存储过程名称、exec后加存储过程名称、直接调用存储过程名称,而PostgreSQL中只能使用call进行调用,TDSQL PG版对此进行兼容改造,支持三种形式。
2.3 其他兼容性介绍
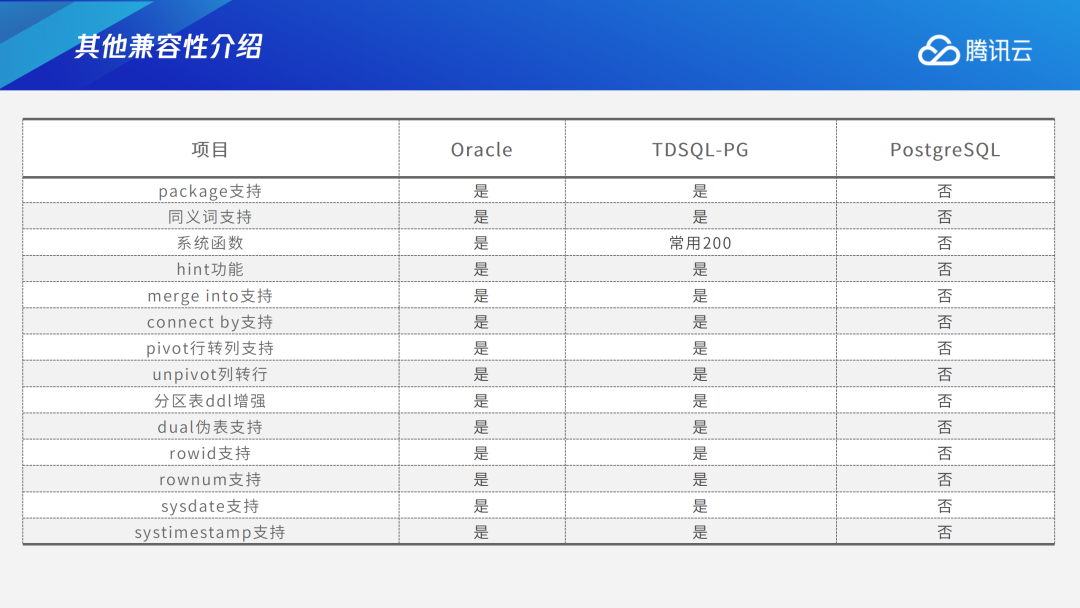
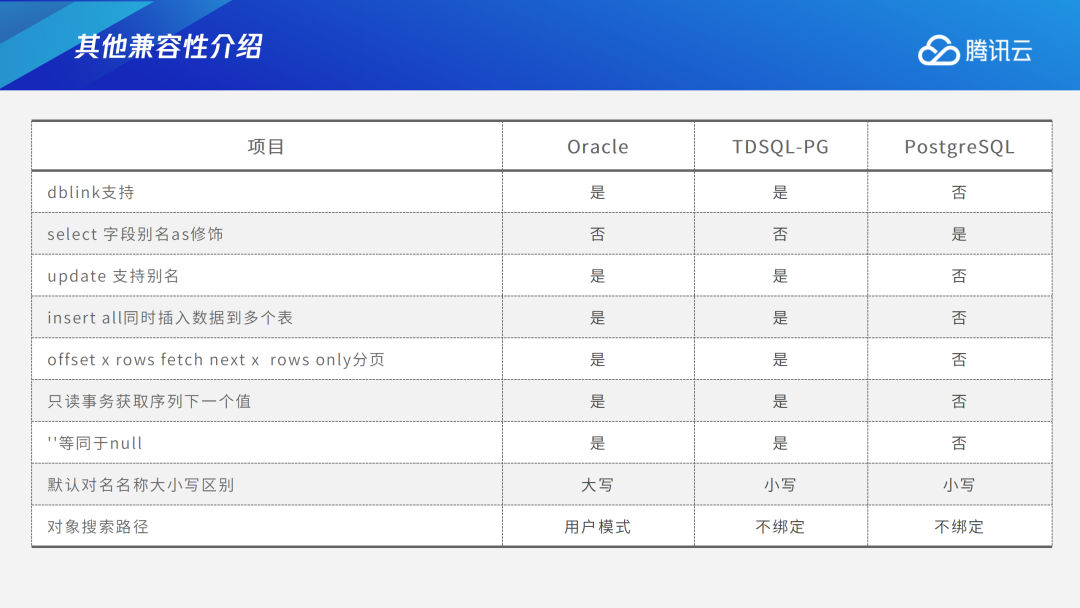
其他兼容方面,TDSQL PG版支持Oracle特有的package及200多个Oracle常用的系统函数。而Hint、Merge into语法、connect by语法、pivot行转列、unpivot列转行、分区表ddl增强、dual伪表、rowid、rownum、sysdate、systimestamp,这些在Oracle中常用的语法和函数,TDSQL PG版都可以兼容。此外,目前TDSQL PG版也支持通过dblink去访问Oracle中的数据、select字段别名不需要as修饰、update 别名支持、insert all语法同时插入多个表、特有的分页查询语法、只读事物中要获取序列等。
3. Oracle兼容能力
3.1 分区表能力
TDSQL PG版支持range、list 、hash 、高性能等间隔分区,并且可以实现多级分区级联,在分区表的访问方法上全面兼容Oracle语法,除可以直接访问子表外,还支持带父表关联子表访问。同时TDSQL PG版也支持update分区字段的值。以下图为例,0-30范围的子表中的id分区键的值通过update将其改为50时,因为50大于30,系统会自动将修改后的数据加入到30-60范围的子表,而删除0-30范围子表中的旧数据。TDSQL PG版还具备分区子表合并拆分能力及新加分区时default分区自动移动的能力。3.2 分区子表合并&拆分
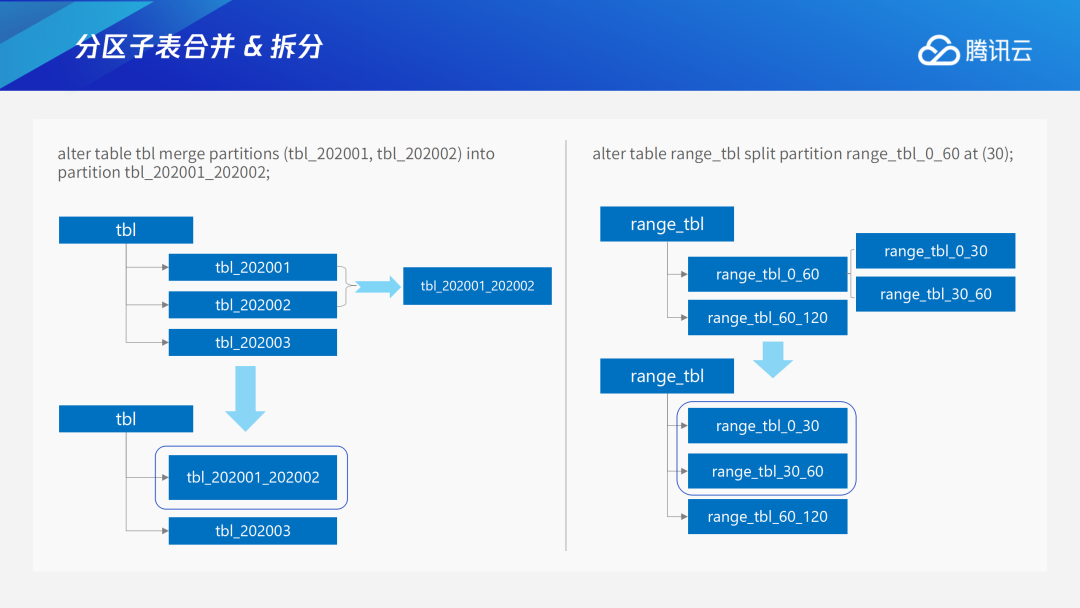
随着时间的推移,在使用过程中,系统中的分区会越来越多。为方便管理,很多用户在早期想将分区进行合并,TDSQL PG版也像Oracle一样提供了分区子表合并的能力。如图中左边所示,通过merge partitions 202001和 202001的分区,形成新的分区,可以有效减少分区数量,便于管理。如果经常访问的热点数据所在分区内数据过多,就容易扫描到很多不必要的数据,这时可将分区进行拆分。如图中右边所示,将热点分区0-60范围分区split拆分,后续访问热点数据50时就只需扫描30-60范围的分区,可以有效减少数据扫描,提高查询效率。具体的实现方式为:merge时数据库底层会新建一个分区,将指定要合并的分区数据全面迁移,再删除旧的分区。Split时,数据库底层会创建出新的2个分区,将旧分区的数据按照大于/小于拆分点进行划分,分别插入不同的新的小分区,再删除旧分区。
3.3 Default分区数据维护
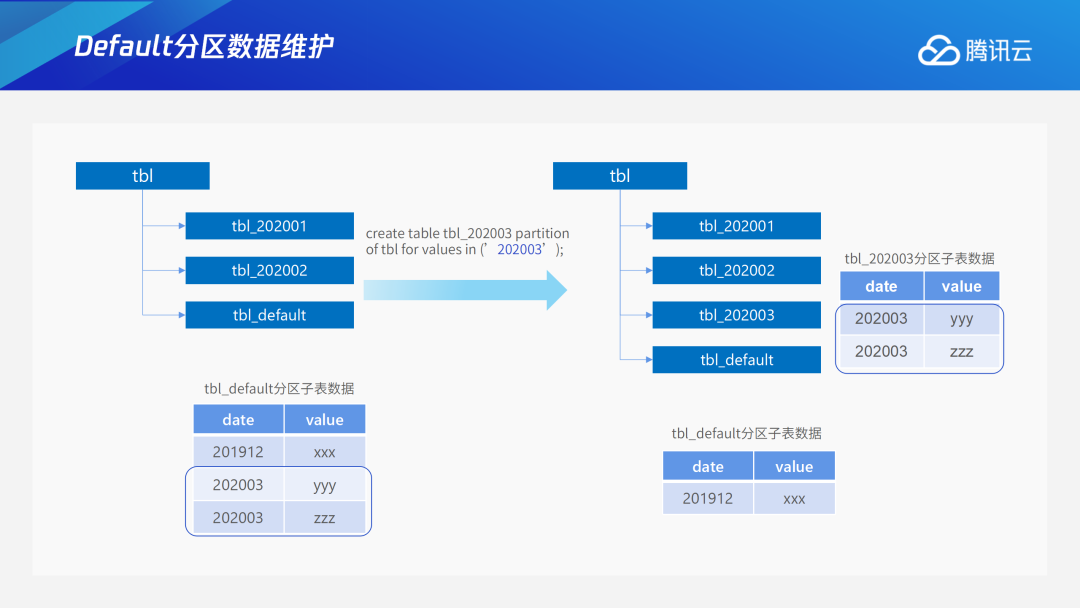
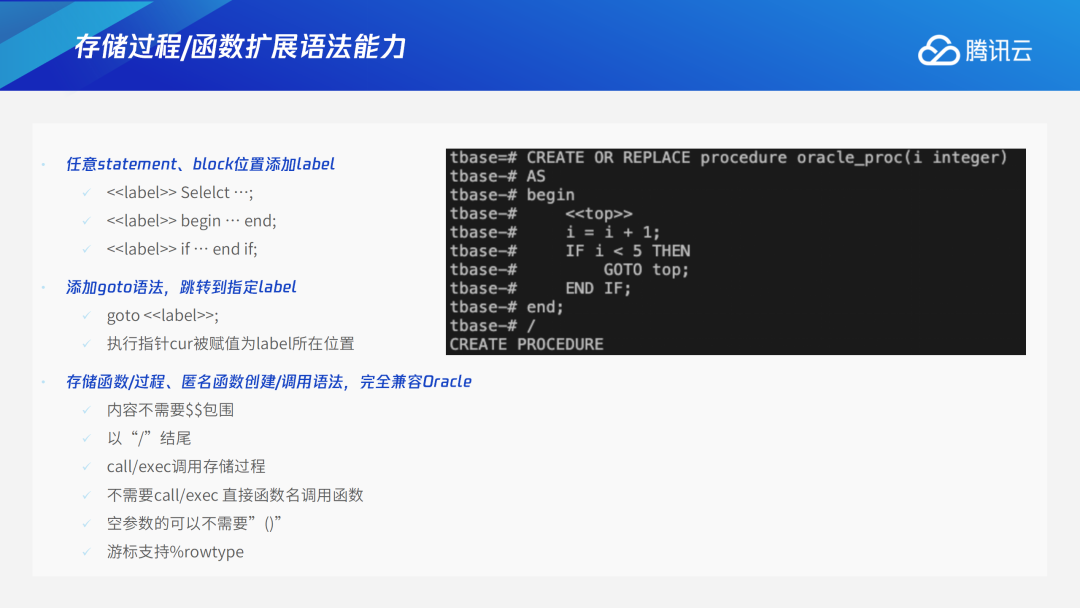
分区表中一般会有一个默认的default子分区,用于存储不属于其他子分区的数据。比如在下图中,2019年12月、2020年3月的数据,都不属于已有的2020年1、2月的分区,因此这些数据会自动放在default子分区中。如果后续用户新创建了2020年3月的分区,TDSQL PG版可以像oracle一样,自动将属于2020年3月的数据从default子分区迁移到新分区中,在default子分区中就只剩2019年12月的数据。整个过程中用户完全无感知,只需要创建分区,TDSQL PG版内部会自动进行迁移。TDSQL PG版底层具体的实现方法:扫描default分区表,将满足新分区的数据插入新分区,删除default分区表中这些数据。3.4 存储过程/函数扩展语法能力
为全面兼容oracle,TDSQL PG版的存储过程和函数在创建调用语法上也进行了适配,除前面提到的函数体不需要$$包围、以/结尾、空参数不需要括号等细节外,TDSQL PG版还支持在任意的statement语句、block代码块前添加label标签,再goto跳转到指定的标签,而原生PostgreSQL只能在循环前加label。实现方式是将执行指针cur被赋值为label所在位置,再从label所在的位置继续往下执行。3.5 WITH FUNCTION语法支持
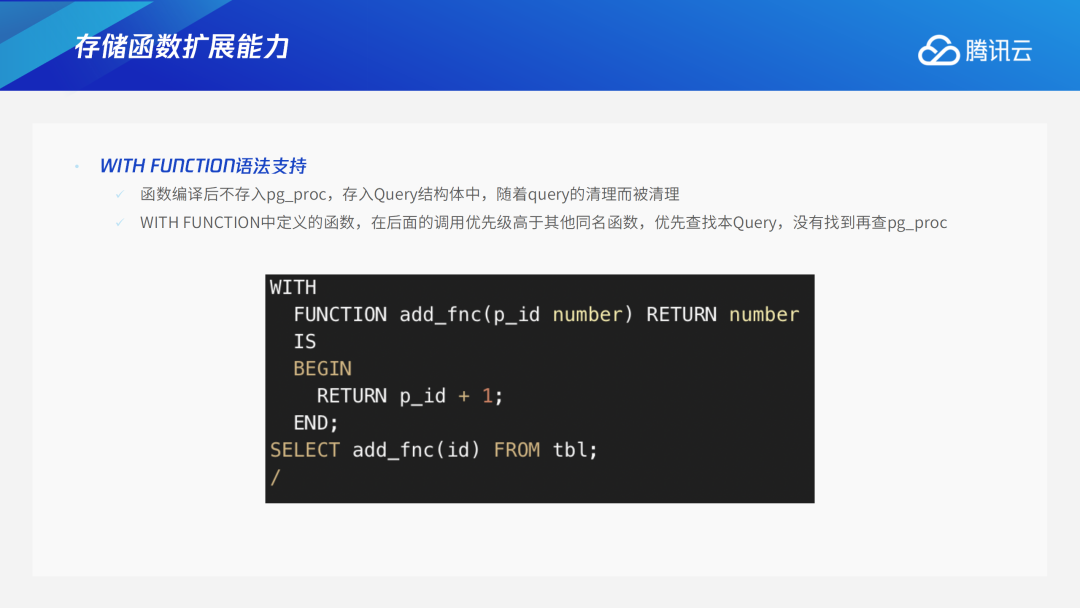
除了储过程,TDSQL PG版还对存储函数进行了扩展,比如在函数上添加了对WITH FUNCTION语法的支持。以下图为例,select调用的add function函数只在此语句中有效,其他语句无效。如果系统中已经有同名函数,这个select语句中的WITH FUNCTION的优先级会高于其他同名函数。实现方式为:函数编译后不存入pg_proc,存入Query的结构体中,随着query的清理而被清理;调查时优先查找Query带的function,没有找到再查pg_proc。3.6 PACKAGE
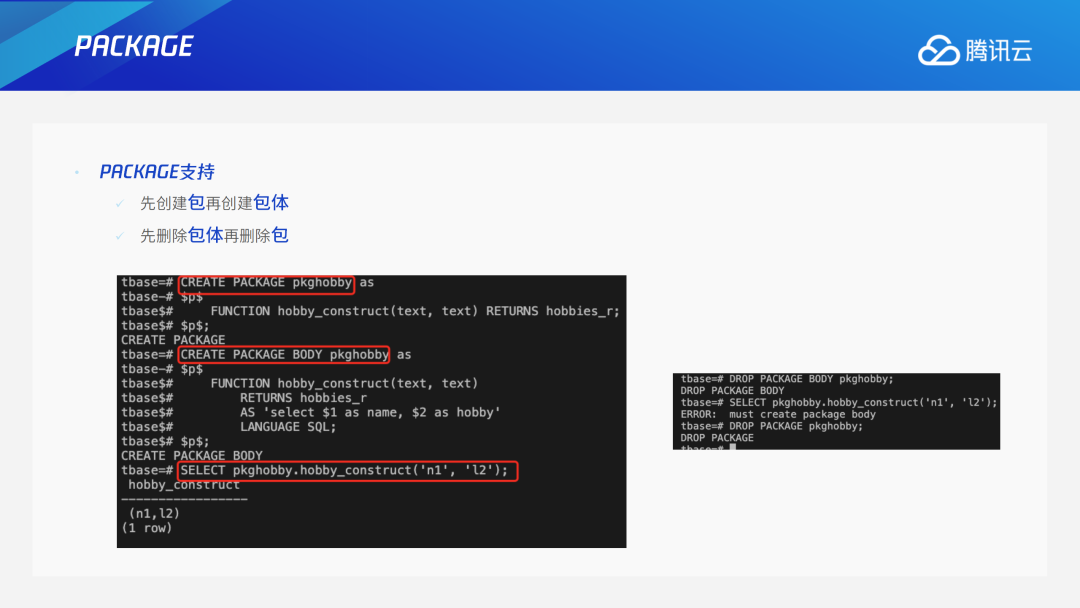
Oracle中Package比较常见,用户常用的函数大都存储在Package中。目前TDSQL PG版也支持Package,用户可以将自定义的常用函数封装到Package中,使用时指定Package来调用对应函数。具体的实现方式是:在创建package时后台会创建一个对应的schema和里面的函数(函数内容为空),创建包体的时候指定函数内容时再去alter function,包里的变量都放在schema下面,可参考PL实现PL中的变量功能。删除时则是先删除包体再删除包。3.7 ROWID & ROWNUM
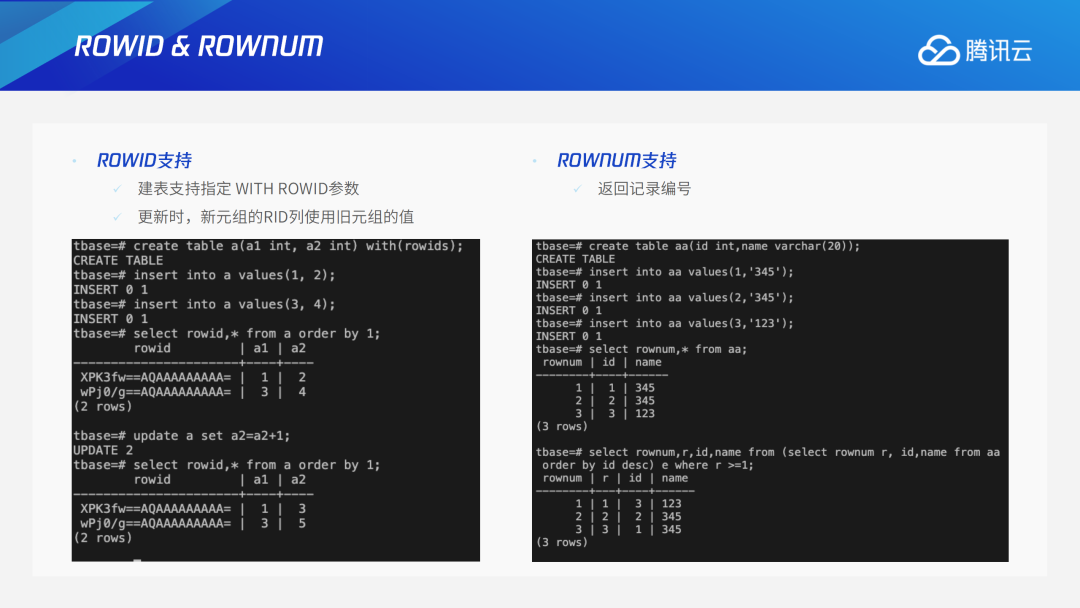
ROWID和ROWNUM都是Oracle特有的语法,PostgreSQL并不支持,TDSQL PG版对此进行兼容改造,支持ROWID和ROWNUM。两者的区别在于:ROW ID的兼容实现是在用户建表时,指定该表是With ROWID。后续查询就可以查询到ROWID具体的值,ROWID相当于唯一标识,在用户写入阶段会从本地SEQUENCE获取唯一ID值再加上分布式的nodeid进行填充,写入到用户数据文件中。ROWNUM的实现是做完过滤和投影后CN返回给用户时添加的一个编号,在用户最后返回阶段进行添加。3.8 MERGE INTO
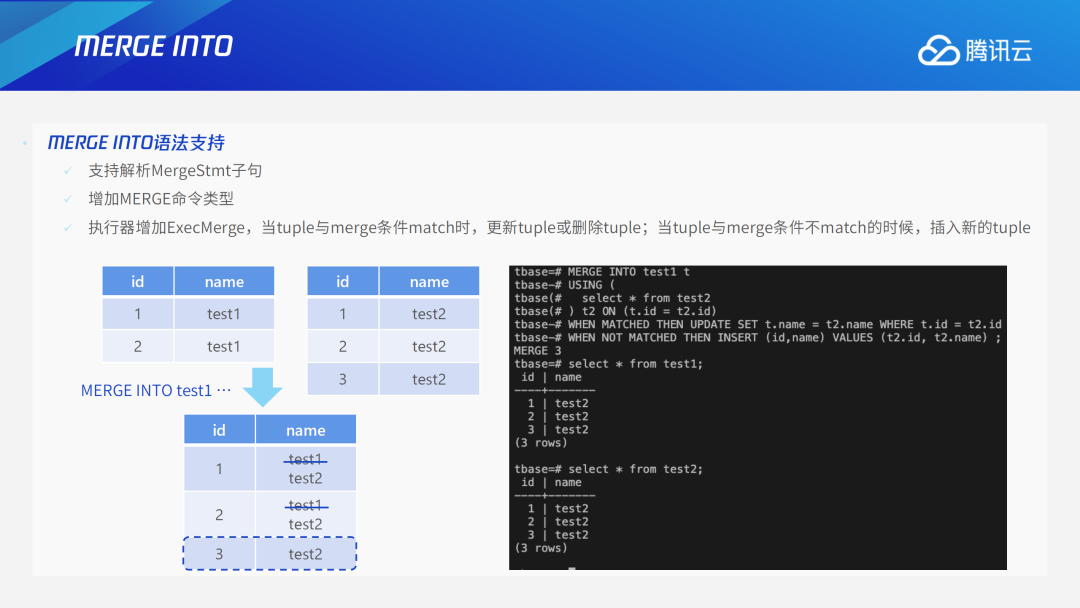
Merge into可以将两个表进行合并。以下图为例,目标是Merge到Test1中,但参考Test2的数据。如果能匹配上,就修改Test1里的数据,使数据与Test2的记录一致,如果不匹配,就把Test2的数据插入到Test1中。最终执行的效果类似于Test1合并了Test2,将Test2中的数据Merge到Test1中。在实现过程中,TDSQL PG版添加了merge算子,在Query结构体中新增了int mergeTarget_relation;List* mergeSourceTargetList;List* mergeActionList; /* list of actions for MERGE (only) */3.9 Start with connect by
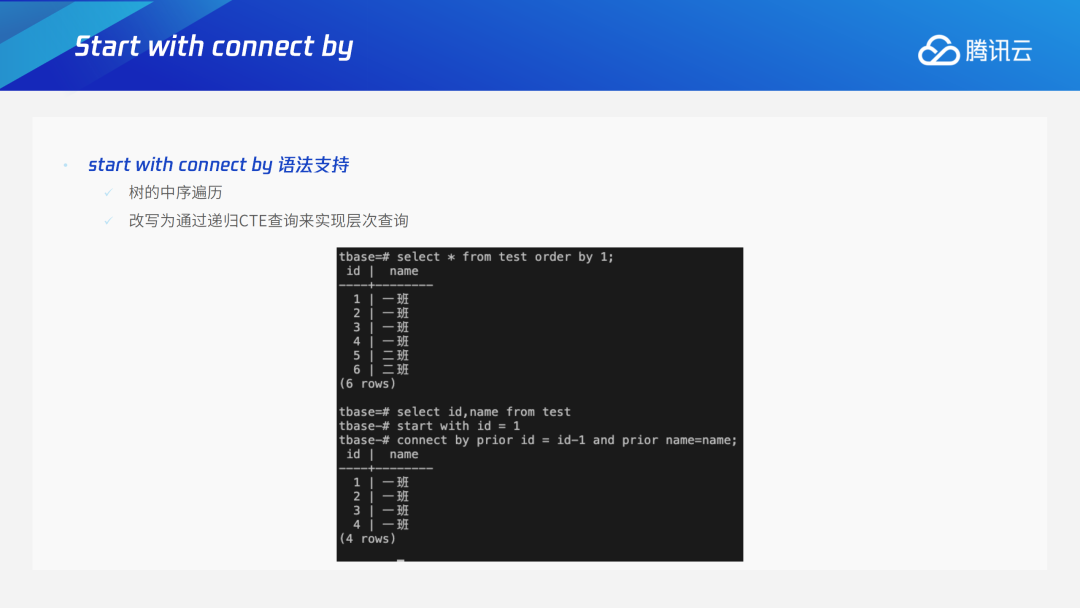
语法解析支持connect by查询。在解析时通过函数make connect by stmt将select stmt改写为通过递归CTE查询来实现start with connect by层次查询子句。后续通过TDSQL PG版本身支持的递归CTE语句来执行。
3.10 PIVOT & UNPIVOT
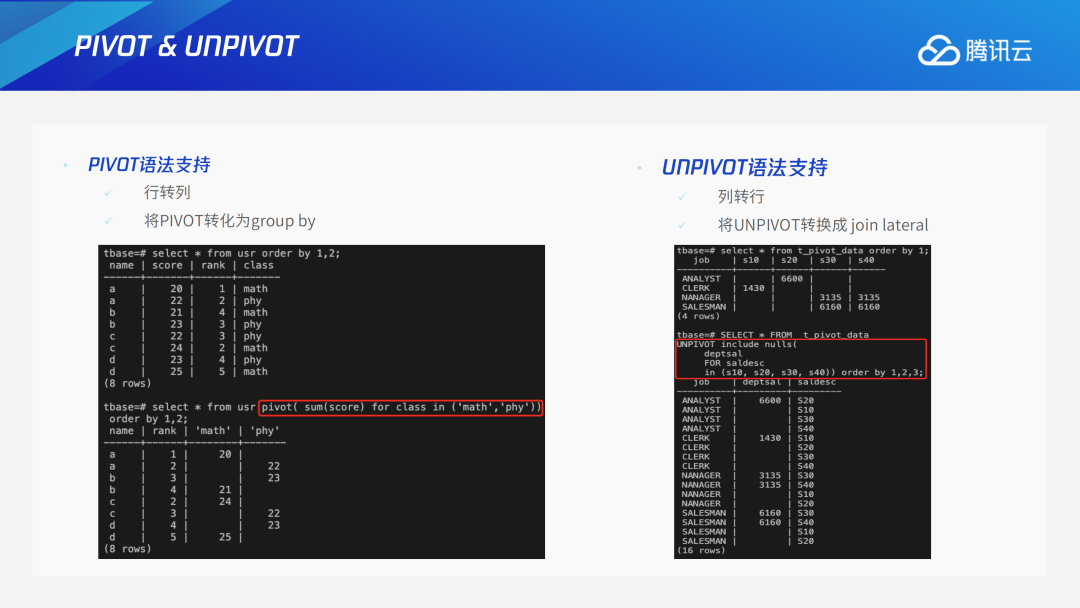
PIVOT '(' target_el FOR columnref IN_P '(' pivot_expr_list ')' ')'TDSQL PG版实现方法是将不再target_el以及columnref中的列作为group by列,通过pivot_expr_list对target_el中的聚集函数参数用case when进行重写,规则是“有值取值、没值取空”。UNPivot可以将列属性转行数据, 本质是转化为 join lateral。实现方法是获取IN中的列,拼接成VALUES(…),将UNPIVOT column和FOR column拼接成VALUES的别名,将查询中FROM后面的其他表与value rte表做 join lateral。3.11 其他兼容能力
此外,TDSQL PG版支持Oracle中的日期、时间、字符串、表达式等常用函数。目前TDSQL PG版可以兼容98%以上的运营商、保险行业常用Oracle语法,兼容85%以上的银行机构常用Oracle语法,有效降低传统IT企业的国产化及信创门槛。
4. Oracle to TDSQL PG版迁移
4.1 迁移工程面临问题
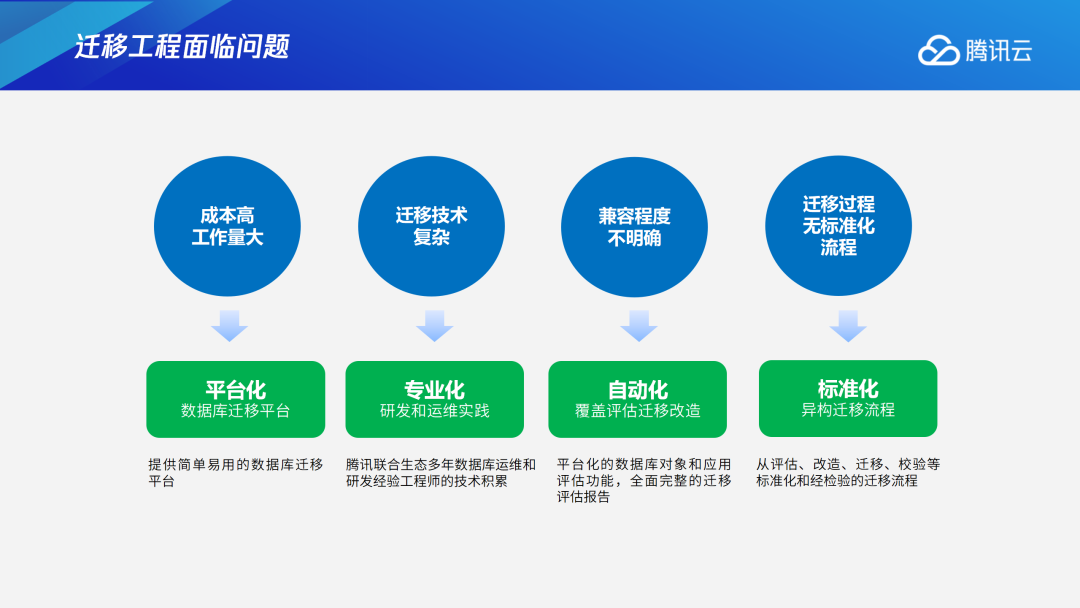
从Oracle到TDSQL PG版的迁移过程会涉及到四个问题:一是成本高且工作量大;二是迁移技术复杂;三是兼容程度不明确;四是迁移过程无标准化流程,突发问题频繁。我们将上述问题分门别类,逐一进行解决。针对工作量大的问题,可以通过TDSQL PG版提供的简易自动化迁移平台,下发一个迁移任务即可解决;针对迁移技术复杂的问题,我们会为用户提供专业的技术支持,协助用户进行迁移;针对兼容程度不明确的问题,我们会在迁移过程中进行评估,生成评估报告来说明兼容程度;针对迁移过程无标准化流程的问题,我们会在每一步都输出相关文档、报告来进行迁移,促使流程标准化。
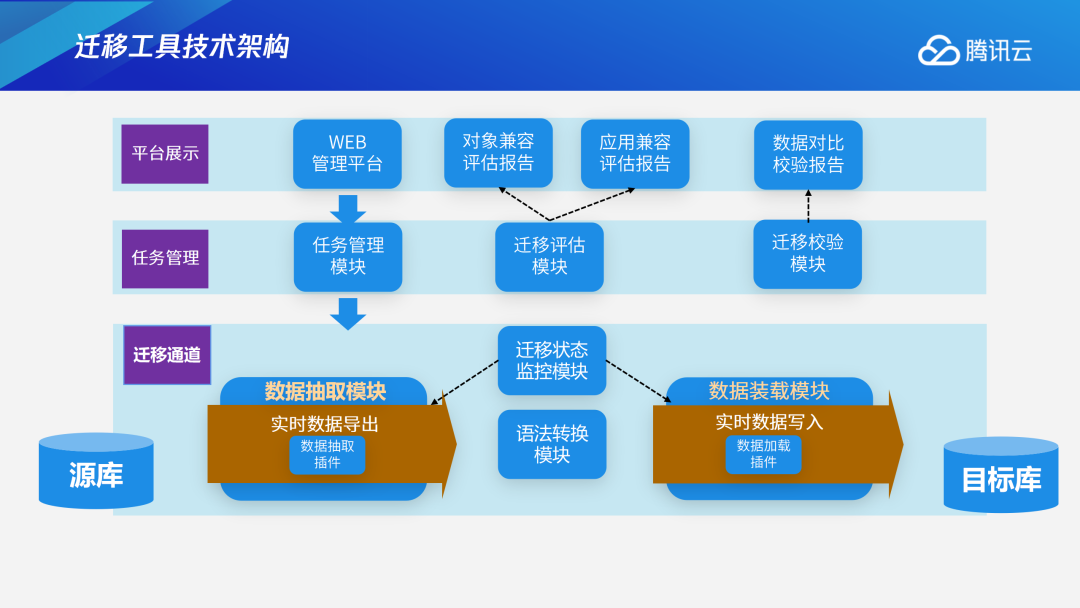
4.2 迁移工具技术架构
下图是TDSQL PG版迁移工具的技术架构,左边是源库,右边是目标库,分为数据抽取模块和数据装载模块。数据抽取模块会从源库里面抽取,实时导出用户数据。数据装载模块会在目标库里进行实时数据写入,进行数据迁移。针对部分语法不能完全兼容的问题,我们会进行语法转换,把数据传递到数据装载模块,数据装载模块会直接实时写入到目标库中。迁移过程中,监控模块会实时监控整个迁移任务,期间会输出兼容报告,迁移完后进行数据校验。4.3 兼容性评估
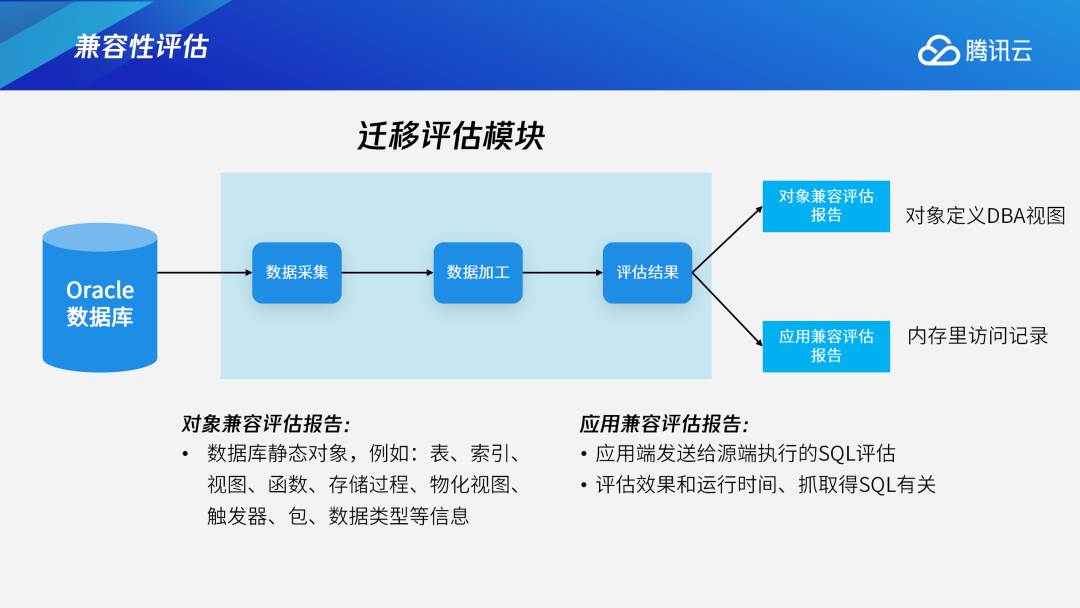
兼容性评估会输出两个报告:对象兼容报告和应用兼容报告。对象兼容是指数据库的对象,如表、索引、视图、函数或数据类型等信息;应用兼容主要是指前端应用层发送给源端执行的SQL。我们会针对这两方面输出兼容报告。4.4 兼容性评估报告
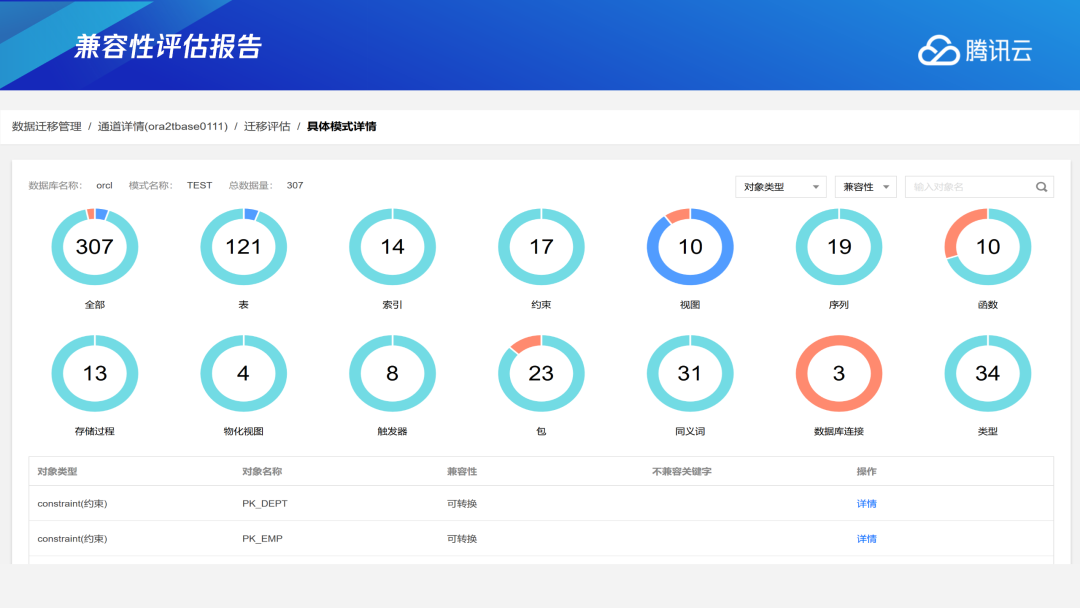
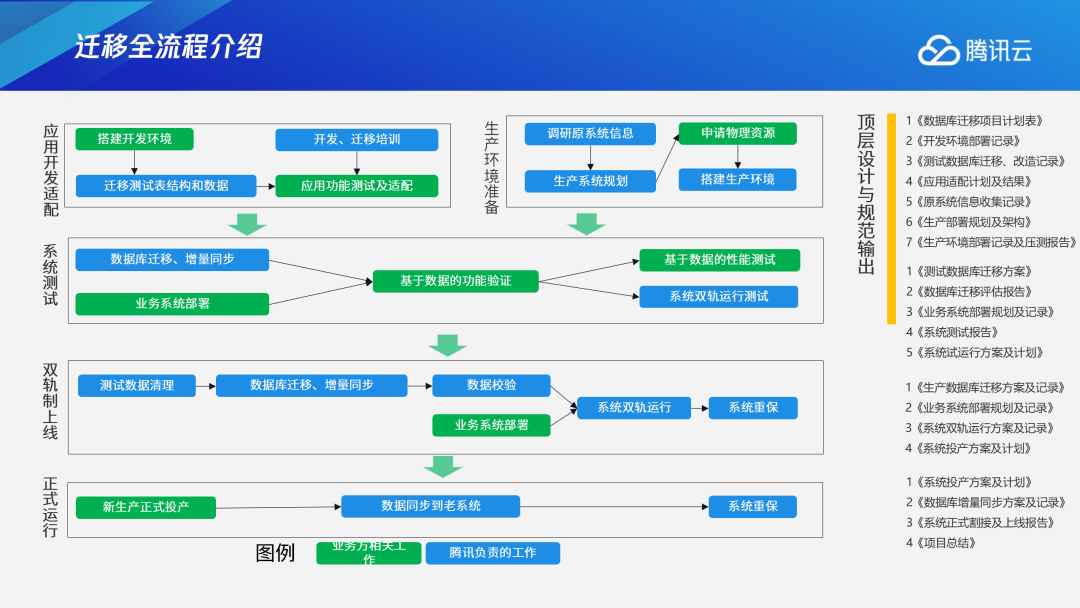
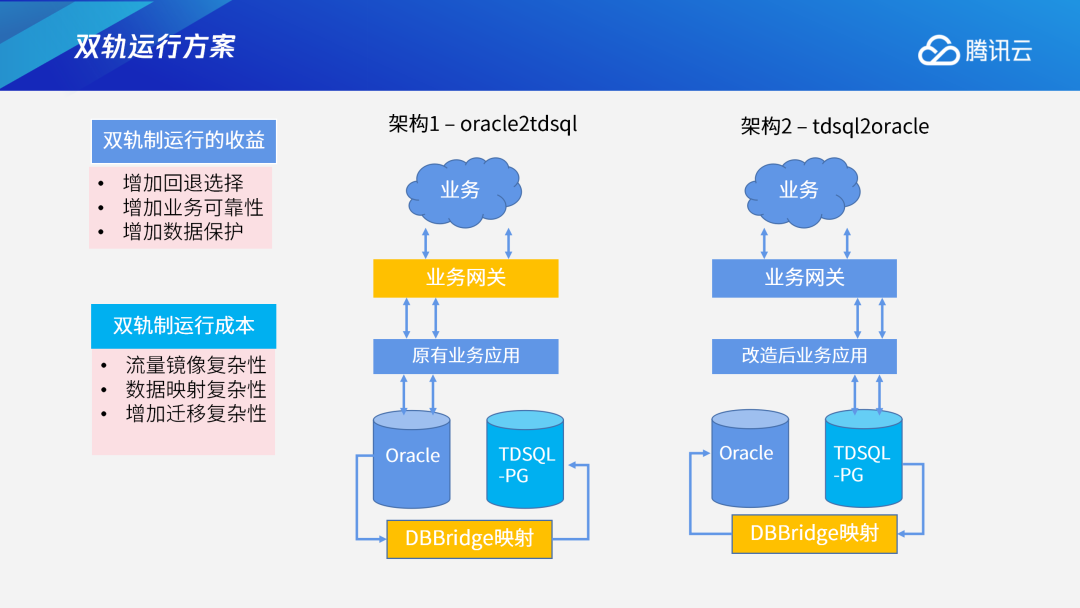
下图是一份对象兼容报告,分为三种颜色:蓝色代表完全兼容,不用做任何改造就可以将Oracle中对象在TDSQL PG版中进行使用;绿色代表内部转换,针对Oracle的使用语法或类型,工具会自动转换成TDSQL PG版中适配的语法和类型,从而进行迁移;红色代表不能转换,完全不兼容,需要用户人工接入。整个迁移流程可分为四个环节。首先是应用开发适配和生产环境准备。在进行应用开发适配过程中,可以并行地进行生产环境的系统规划,调验原先的系统布局。其次是系统测试环节,将原先在Oracle中的存量、增量数据全部迁移过来进行测试验证,包含功能验证和性能验证。验证完后到双轨制上线环节,相当于老系统和新系统同时并行运行。正式上线投产后,再根据用户需求判断是否需要将TDSQL PG版中的数据同步到老系统中。这个过程需要和用户共同完成,图中绿色部分是需要用户配合的部分,蓝色部分则是我们负责的部分。下图是我们的双轨运行方案,图中有两个架构,分别是Oracle To TDSQL PG版和TDSQL PG To Oracle。业务上线前期,我们采用双轨运行,支持从Oracle到TDSQL PG版以及从TDSQL PG版到Oracle的数据同步。通过业务开关,用户可以根据需求,选择将部分业务放在原有系统或将另一部分业务放在新系统,也可以选择全部放在新系统或老系统。当双轨运行持续稳定后才会进行正式上线。双轨制运行相当于过渡环节,如果有问题,用户可以降低回退到以前的系统上,给数据增加了双层保护。当然,双轨制运行的过程相应地也会更加复杂。TDSQL PG版起源于技术成熟、功能强大的PostgreSQL,在此基础上腾讯云数据库构造和发行了功能更丰富、稳定性更好、兼容性更广、安全性更高、性能更强、扩展性极好的分布式数据库TDSQL PG版产品。腾讯公司对TDSQL PG版具有完全自主知识产权,实现安全可控, 具备在中高端市场规模化替代国外数据库的能力,在数据库基础软件层面有力支撑了国家安全可控战略发展。当前TDSQL PG版已经在金融、保险、通信、税务、公安、消防、政务等多个行业的核心交易系统上线运行,为众多行业客户提供优质服务。