
卷死我了,14岁就。。。
大家好,我是 Jack。
互联网是最好的老师!
现在有很多优秀的创作者在网上分享自己的知识和经验。
现在自学编程,真的太幸福了。
Github、B 站、公众号有各种各样优秀的创作者,分享开源教程、视频、文章。
我也是在研究生期间,一路自学的算法。我也深刻体会到了,只要有毅力,自学一项新技能,完全没有问题!
最近,我又迷上了历史,感觉博古通今的人很厉害,想培养培养自己这方面的能力。
写代码之余,我打算闲暇时间,看看《古文观止》这类的书,学习下历史。
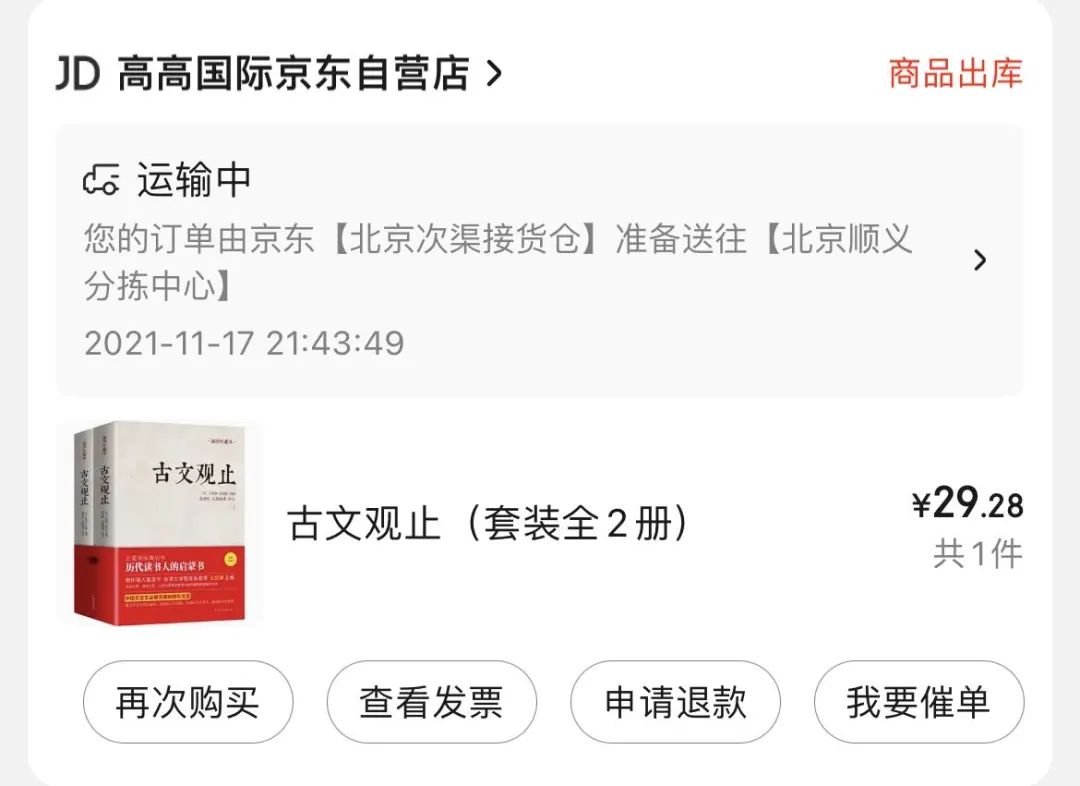
书在路上了,希望自己能坚持住,不要吃灰啊~
虽然,我称不上多优秀,但也做过很多开源教程和教学视频。
https://github.com/Jack-Cherish
不过说了这么多,今天要讲的主角并不是我自己。
而是一位 14 岁的 Kaggle Master,他的经历很好的诠释了,互联网是最好的老师,这个道理。
有些人可能会觉得数据科学和机器学习这两个术语令人生畏,认为它们需要专业技能才能成功。盯着无穷无尽的代码,可能会让人不知所措。
Kaggle 是许多人开始数据科学的地方,在这篇文章中,将分享 Andy 是如何成为最年轻的 Kaggle Master。
以下是他本人的自述,纯英文的文章,本文翻译成了中文。
作者:Andy Wang
https://towardsdatascience.com/my-journey-to-kaggle-master-at-the-age-of-14-e2c42b19c6f7
个人介绍
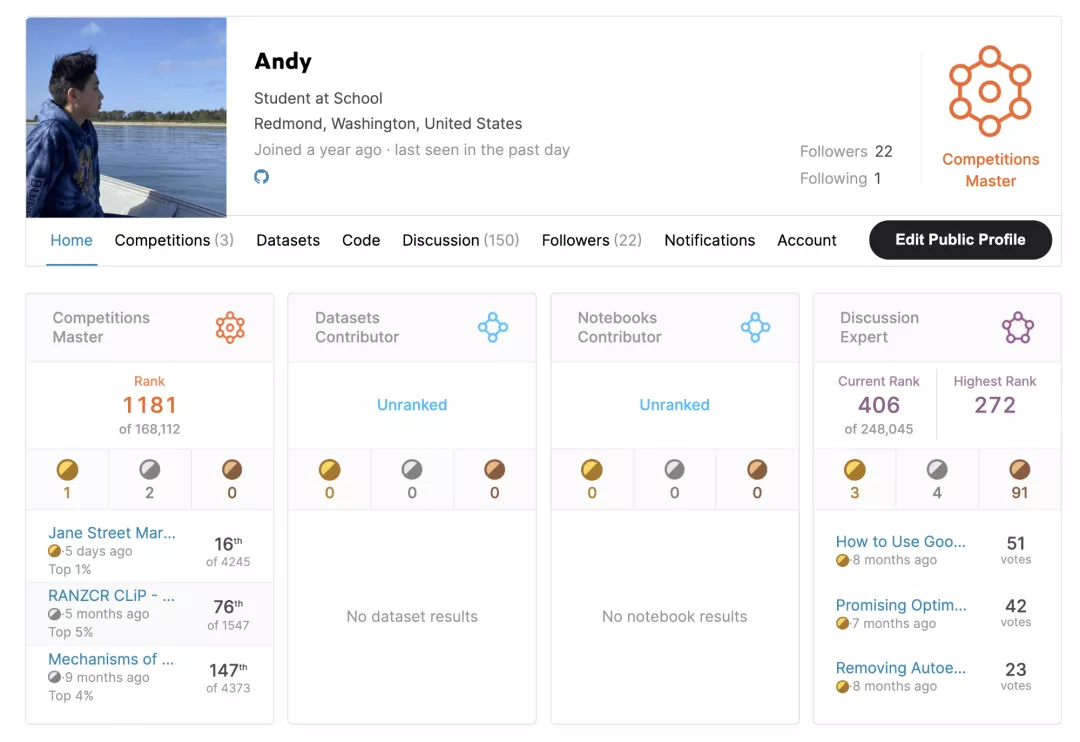
我是 Andy Wang,一名高中新生,对数学、人工智能和计算机科学有着浓厚的兴趣。我在Kaggle上学习和提高我的技能,获得了2枚银牌和1枚金牌。
几年前,我开始对数学产生兴趣,并开始学习比我在学校自学的更高级的主题。不久之后,我开始研究编程,因为我从小就对计算机科学着迷。
通过关键词搜索我找到了几门教授 Python和基本编码概念的课程。不久,我开始自己编程,使用回溯算法制作小项目,例如数独求解器。
我是如何进步和学习的
我对编程和机器学习概念的了解主要来自互联网。有疑问时,互联网是最好的老师。没有学校教授数据科学或神经网络,如果我想在 Kaggle 上取得成功,我就靠自己了。

随着学习资源的增加,人们不知道从哪里开始或如何学习。因为“数据科学”和“机器学习”相关的领域太多,精通每个类别几乎是不可能的。对于像我这样的初学者,您需要找到自己感兴趣的东西,并充分挖掘它所能实现的潜力。
数学是一切的基础,线性代数和微积分是机器学习中使用的两个最重要的数学概念。几乎所有的机器学习算法都以某种方式与这两个领域相关。数据以向量和矩阵的形式表示和处理。因此需要了解矩阵的基本运算。
在了解了基础知识后,我开始着手编写代码。凭借面向对象编程(OOP) 和 Python 的基本知识,我找到了一些在线课程,这些课程教会了我机器学习中常用的所有库。
一点一滴的学习,一开始学到的知识,将来可以轻松积累成复杂的东西。
Andy 最开始参加了使用回归技术预测房价的初学者竞赛。我发现我学到的东西远远不够。我最缺的是经验。最好的学习方法是通过失败和尝试新事物。
然后参加了 Mechanism of Action 比赛,通过在论坛、Notebook完成快速学习,最后取得了前4%的成绩。然后 Andy 又参加了两场比赛,又获得了银牌和第一枚金牌。
我的 Kaggle 解题流程
从我参加的比赛中,我遵循了一个通用的流程,它不仅可以组织工作,还可以有效地产生有意义的结果。
仔细阅读数据描述和概述。如果可能,可以尝试探索领域知识。 在阅读任何论文、讨论或Notebook之前,尝试自己创建一个基线。这有助于在将您的思想锁定在其他人所说的内容之前产生全新的想法。 建立可行的交叉验证策略并提交到排行榜。确保您的CV策略也适用于 LB,这一点很重要。 阅读,阅读和学习!充分探索与该主题相关的论文,在论坛和笔记本中寻找灵感。 开始在模型方面或功能方面调整基线。一次只调整一件事,所以你知道是什么导致模型改进/表现更差。 尽可能多地探索新方法,不要在行不通的事情上纠缠太久。 如果其他一切都让你失望,模型集成是最稳定的改进方式。 选择具有良好 CV 分数的提交。
我学习到的知识
特征选择删除不重要的特征,有助于减少数据中的噪声。在 Mechanism of Action 竞赛期间,论坛和讨论帖中的方法对我们设计的模型没有帮助。在这种情况下,不要害怕深入研究并阅读论文。由于我处理的案例多标签分类并不常见,因此我找不到任何简单的教程。我找到了一篇论文,旨在比较使用问题转换的多标签特征选择。
阅读研究论文似乎令人生畏,但能够浏览它们并从长页技术术语中掌握关键词是一项至关重要的技能。对于像我这样的初学者来说,试图理解你遇到的每一篇论文的每一个细节是不可能的。只有当我找到我需要和将使用的论文时,我才会尝试理解论文中的每一个单词和引用。
将模型调整为具有非线性拓扑结构或为表格数据构建类似 ResNet 的结构化网络不仅在 MoA 竞赛中获得了一些惊人的结果,而且在接下来的 Jane Street Market Prediction 中也获得了一些惊人的结果,我们在其中排名第16。 探索不同类型的自动编码器,例如去噪、变分和稀疏编码器,可以为您的数据带来令人惊讶的变化,而不仅仅是简单的特征工程和选择可以实现的。 模型融合。组合不同模型的结果可以为您的解决方案增加多样性,从而使其更加稳健和稳定。无论什么建模技巧奏效,合奏总是我在比赛中的“最后手段”。 始终关注新论文并探索论坛中提到的内容之外的内容。调整激活函数(尝试swish而不是 ReLU)和优化器(尝试AdaBelief而不是 Adam 等)之类的小东西可能只会从模型中挤出一些性能。 跳出框框思考!使用一维CNN对表格数据进行特征提取。或者使用DeepInsight,将表格数据转换为图像,利用 CNN 的优势。
不要沉迷于现在的工作,继续前进并花更多时间探索可以带来改进的新事物。
参加 Kaggle 比赛并获得奖牌并非易事,但通过正确的学习方法和工具,这个过程可以变得更容易。
检查讨论帖子和阅读公共笔记本非常有帮助。每天都有新想法出现,我通过论坛中提到的论文和笔记本中使用的库了解了一些最新且引人入胜的模型和工具。其中之一是TabNet,这是一种通过使用顺序注意将特征选择合并到模型中来对表格数据进行建模的新方法。这个模型让我在 MoA 比赛中获得银牌。 最后,拥有稳定而强大的管道对于在最终的私人排行榜中取得出色表现最为关键。浪费时间过度拟合以在公共排行榜中获得额外的 0.0001 是没有意义的。始终相信您当地的交叉验证分数,因为训练数据量大于公共排行榜的数据量。
只是按复制粘贴对学习或赢得比赛没有帮助。我在 Kaggle 中最重要的座右铭是永远不要复制别人的工作,我可以从他们的想法中得到启发,甚至使用他们的建模方法,但我从不提交其他人的工作作为我的解决方案。
在接触新事物时,我养成了查找所有我不理解的东西的习惯,直到我可以自信地向其他人解释这个主题。
总结
兴趣是最好的老师,只要感兴趣,其实不必考虑太过功利的东西。
我也不知道,我一个程序员,突然想看历史是怎么回事,也不知道看了能对我有啥帮助,但既然来了兴趣,索性就学一学。
互联网有很多优质的学习资源,好好把握,都能学有所成。
我是 Jack,我们下期见~
