
搞定系统设计 01:从 0 到百万用户的系统
如何从零开始设计一套可以服务百万用户的系统。
这是本书第一章的内容,浅显易懂,把常见的套路组合了一下,没有具体的技术细节,过一遍也没什么负担。
从单服务开始
俗话说:千里之行,始于足下。构建一个复杂系统也不例外,我们从单服务开始。
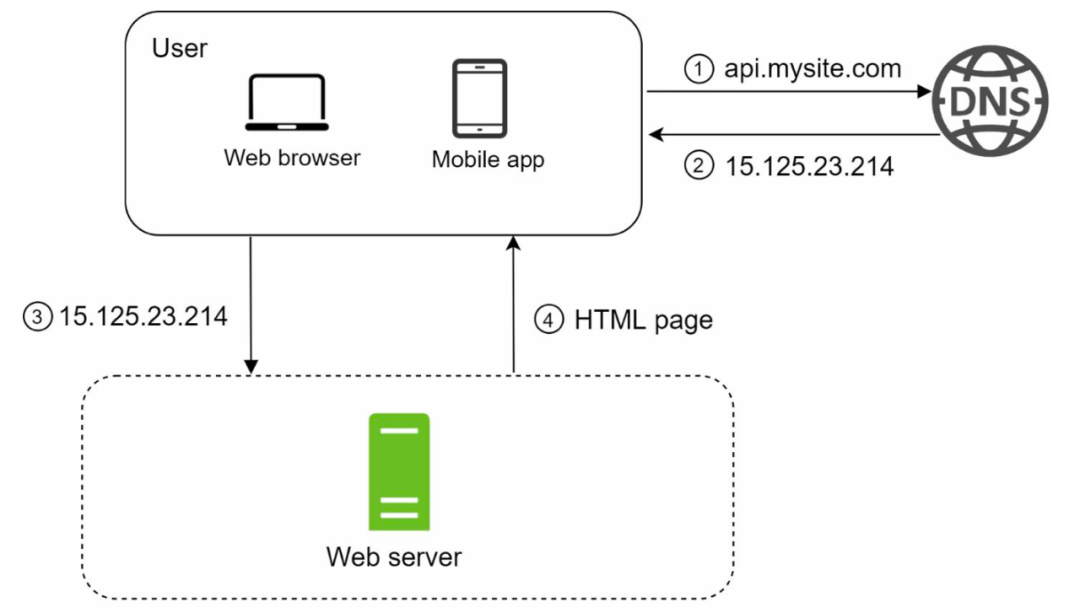
画出整体的大框图,流程很简单。客户端先请求 DNS 拿到服务端的 IP 地址;客户端拿着 IP 地址请求服务端的接口;服务端返回 HTML;客户端渲染出页面。
这种是最简单的系统。但有个问题是:数据无法持久化。只能把状态存在内存中,一旦进程重启,数据就都丢失了。
数据库
因此,一般的服务都会加一个数据库:
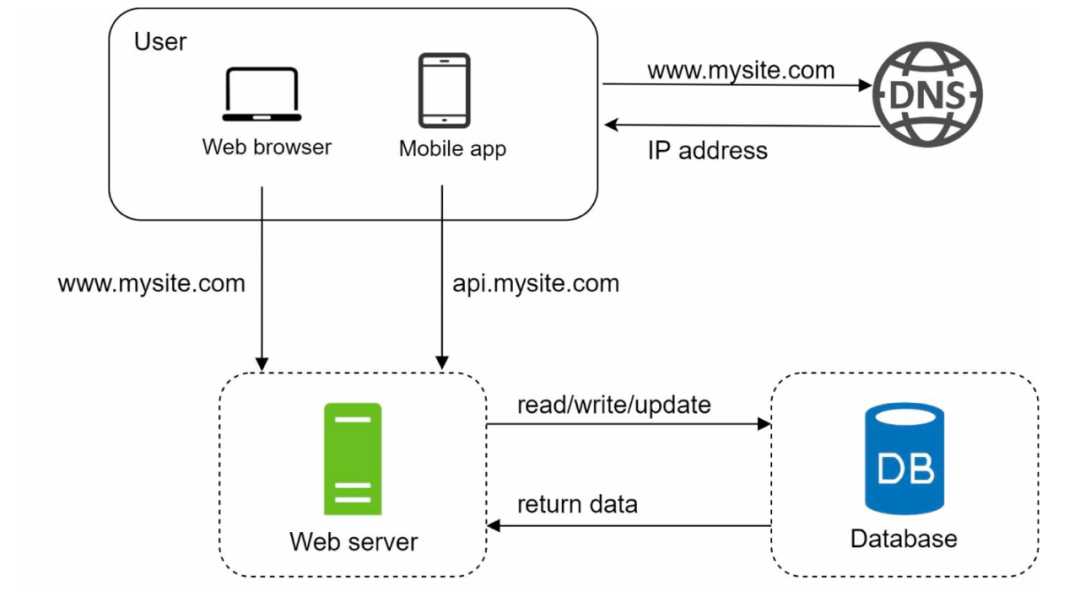
具体是选择关系型数据库还是非关系型数据库,这里有一些需要考虑的点:
关系型数据库最出名的当属 MySQL,Oracle,PgSQL,互联网公司用得最多的还是 MySQL。它将数据存储在一张表的一行,可以在不同的表之间执行 join 操作。
非关系型数据库也叫 NoSQL,它有四种类型:k-v,图数据库,列存,文档型。
更多的时候当然还是选择老牌的关系型数据库,但有些场景还是更适合 NoSQL,尤其是在互联网蓬勃发展的今天。
下面这几个场景更适合使用 NoSQL:
服务需要超低延迟。 服务的数据是非结构化的。 只需要序列化反序列化数据(Json/XML/YAML) 需要存储大量数据。
负载均衡
现在很少有网站直接用 IP 地址+端口的地址访问,前面至少得挂个 Nginx。
后端服务也不能是单个 server,至少得挂个 2 台。当单个服务意外挂了,另一个服务得马上顶上,防止单点故障。
服务之间则是通过私有 IP 通信。
客户端通过 DNS 拿到的 IP 不再是服务器的 IP,而是前面的负载均衡器的 IP。请求到来之后,由负载均衡器将请求打到不同的 server 上。这一切对用户是透明的。
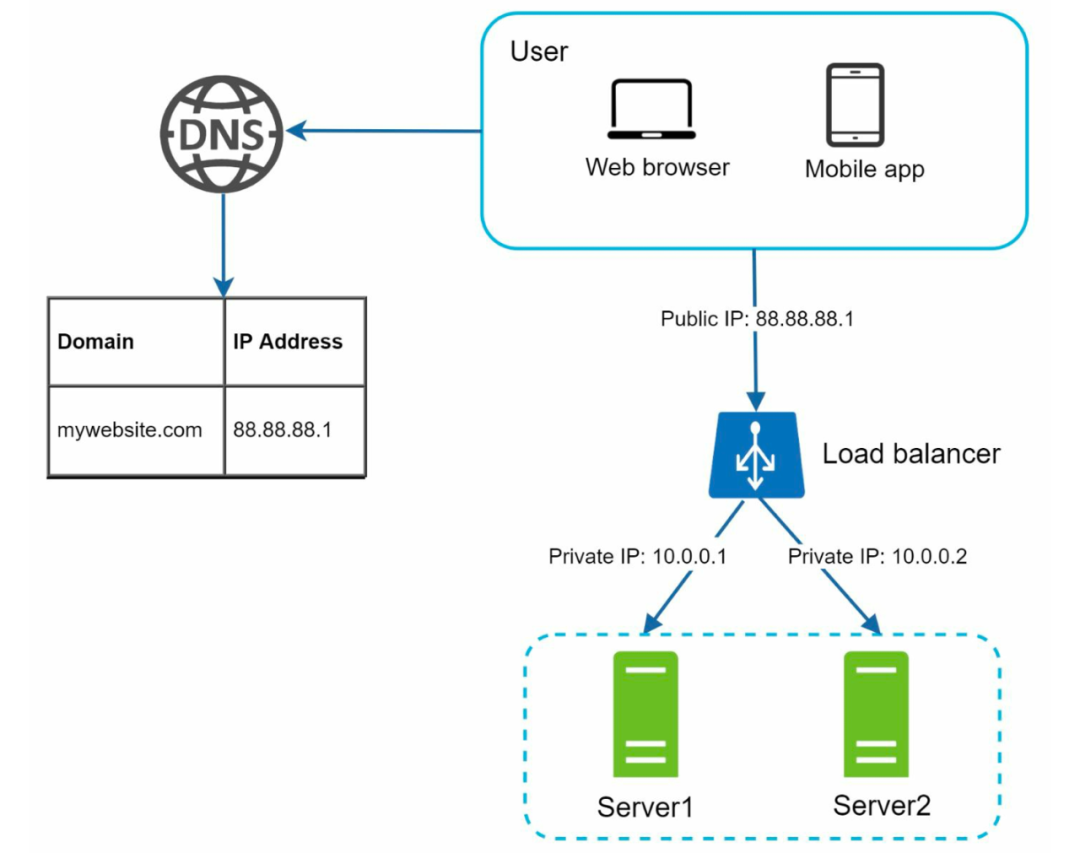
加上了负载均衡器后,服务层的可用性解决了。但是数据库层呢,我们还只有一个数据库服务器,一旦它挂了,服务同样是不可用的。
解决办法就是让数据库有更多的副本。
数据库副本
互联网绝大多数的场景是多读写少,可以采用经典的主从式架构模式,一般都会设置成一主多从。
所有的写操作,包括插入、删除、更新操作由主执行;而所有的读操作都由从执行。
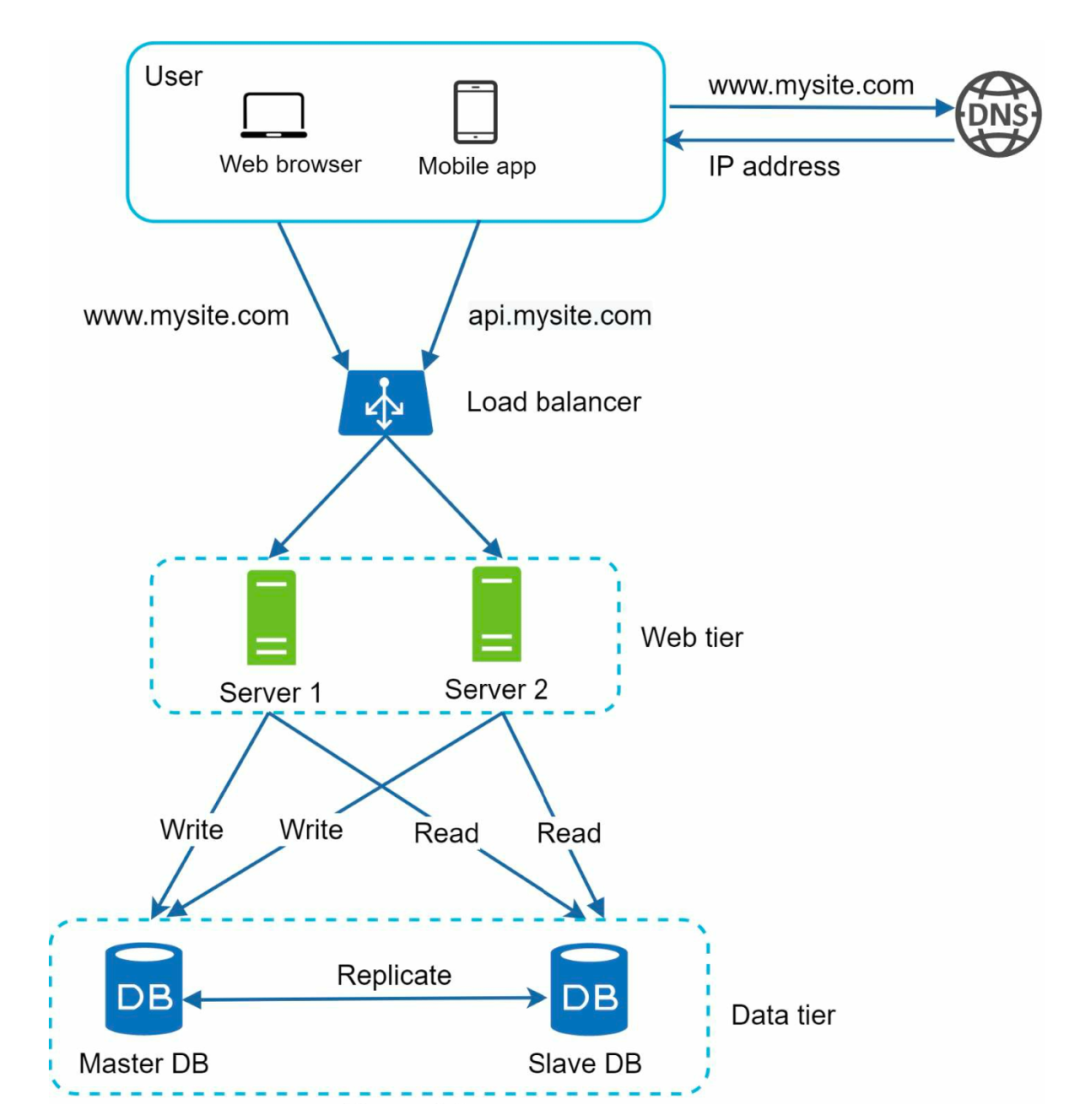
采用主从架构的好处很多:
性能更强。读操作被分散到多个从,每个从的压力会更小,性能也更高。 可靠性更高。数据被分散保存,一个从挂了,数据不会丢,可以通过其他从恢复。 可用性更强。一个从挂了,有其他从顶上。
缓存
增加一个缓存层也是常规的做法。
缓存在内存中存储计算好的结果,等下次请求到来时,直接使用内存中的数据,系统响应时间会更短。
关于缓存,有这么几点需要考虑:
何时使用缓存。读多写少的场景更适合用缓存,例如城市 id 和名称的对应关系,基本是不会变的,放在缓存中再合适不过。 过期策略。过期后,数据将被移出缓存。过期时间既不能太长也不能太短:太长数据会不“新鲜”,太短则需要频繁更新数据。 一致性。数据发生变更时,数据库里的更改和缓存的更改并不在一个事务中,存在不一致的风险。 处理单点失效。由多个 server 组成集群,在多个数据中心部署缓存都是可选的方法。 逐出策略。一旦 cache 满了,再添加新的缓存项时就需要逐出缓存中已有的缓存项。逐出策略如 LRU、LFU、FIFO 分别在不同的场景下使用。
CDN
CDN 全称是 Content Delivery Network,内容分发网络。它是基于地理位置的服务,用来缓存静态内容,如图片、视频、CSS、JavaScript 文件等等。
下面这张图展示了 CDN 的工作流程,非常清晰:
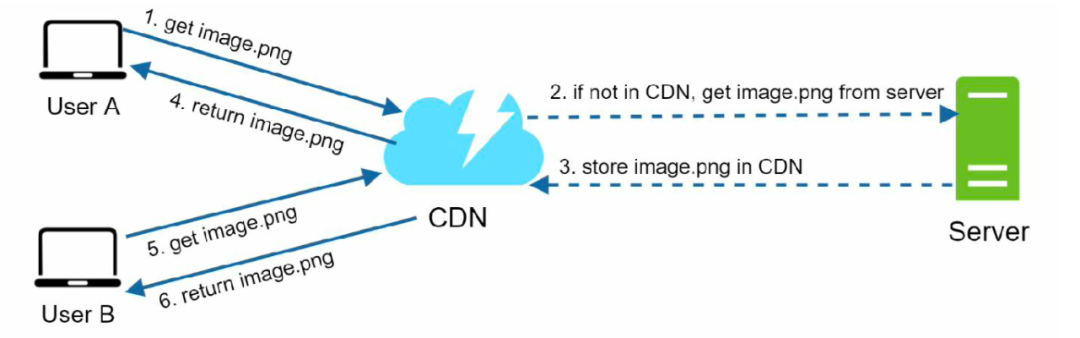
使用 CDN 需要考虑的点有:
费用。CDN 一般由第三方提供,根据数据流入、流出量收取费用。因此对于不常访问的数据应及时从 CDN 中移出。 设置过期时间。太长导致数据不“新鲜”,太短又需要频繁回源读取数据。 CDN 失效时如何处理。当 CDN 出问题时,客户端应该有能力直接从源服务器读取数据。 踢出文件。通过 CDN 厂商提供的 API 手动踢出或者通过在 URL 中增加版本号的方式实现。
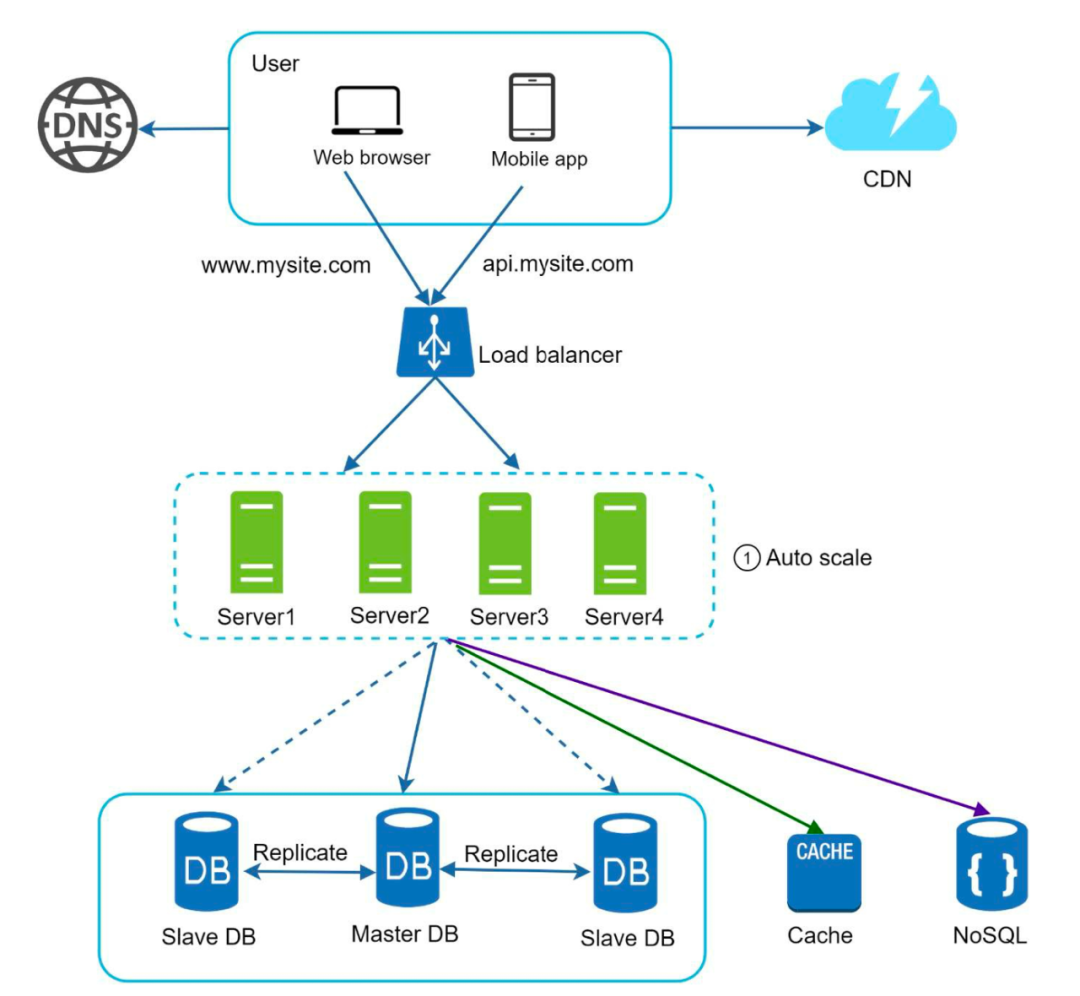
当我们增加了 CDN 之后,系统架构图如下:

无状态层
Web 层的水平扩展依赖无状态的设计:将状态(例如用户的 session)保存在外存,一般用 NoSQL。
当 Web 层无状态化后,流量上升就加机器,流量下降就减机器,扩展更容易。
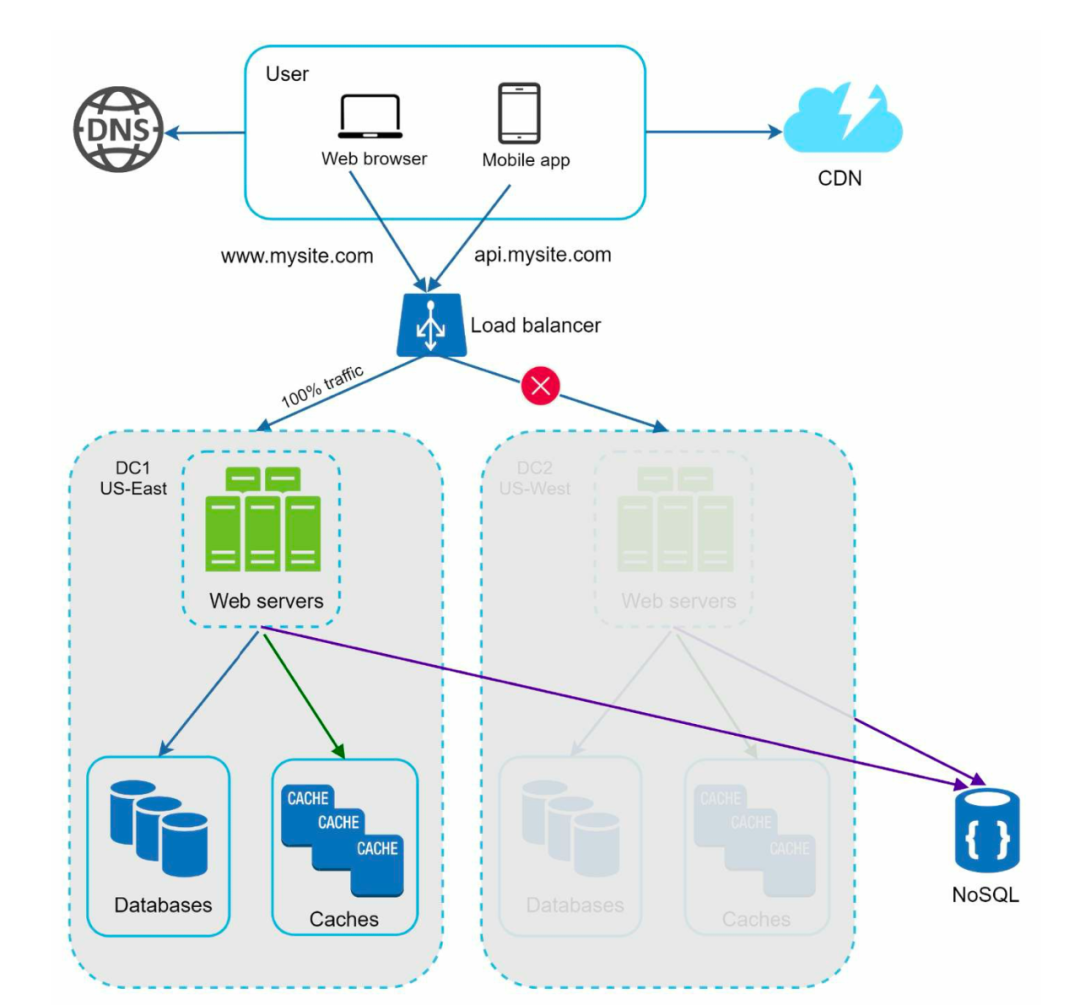
数据中心
业务做起来后,用户会越来越多。为了更好的用户体验,需要建立多个数据中心。根据用户的地理位置决定由哪个数据中心提供服务。
当某个数据中心宕机了,流量自动或手动切到其他数据中心。
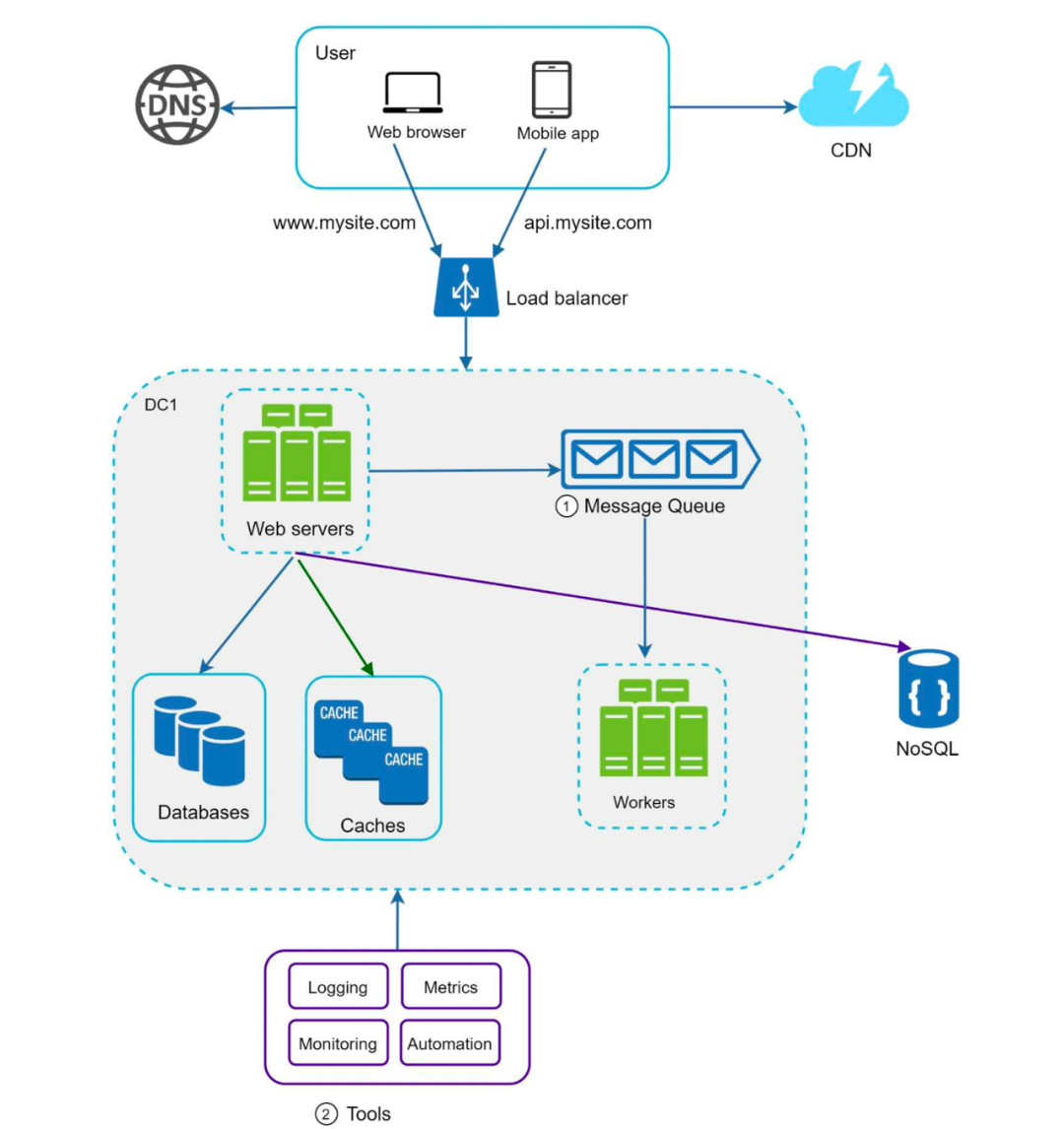
消息队列
消息队列让生产者和消费者解耦,对于构建可伸缩的服务架构是非常有用的。
生产者向消息队列发送消息,它不需要关心消费者是否在可用。消费者消费消息,它也不需要关心生产者是否可用。
日志、打点、自动化
对错误日志量的监控常常能快速发现和定位问题。
对业务信息、机器状态、进程状态进行打点和监控也是必不可少的。
当整个系统越来越大,我们还需要通过自动化工具来提升开发效率,CICD 就得搬到台前。
数据库伸缩
服务在线上正常运转,数据会越来越多。单机总有一天不能装下所有的数据,对数据库的扩展需求提上日程。
同样有两种扩展方式。
最简单的就是垂直扩展。换更大容量、更多核心,更大内存的机器,只要足够有钱,这都不是事。开始阶段,加机器的效率甚至更高。
更难的是水平扩展。说白了就是分 shard,将全量数据拆分到不同的机器上去。
分 shard 最关键的就是 key 的选取,它要能保证数据的平均分布。
数据分片并不容易,需要考虑下面这几点:
resharding。当某个 shard 也不能完全存放数据时,就需要重新再分 shard。reshard 最常用的方法是一致性哈希。 名人问题。也称为热点 key 问题,需要特殊解决。 join。一旦分片,数据库被分散到不同的机器上,不再能执行 join 操作,通常的解法是将字段冗余到同一个表上。
最后是一张考虑了以上所有的点之后的架构图:
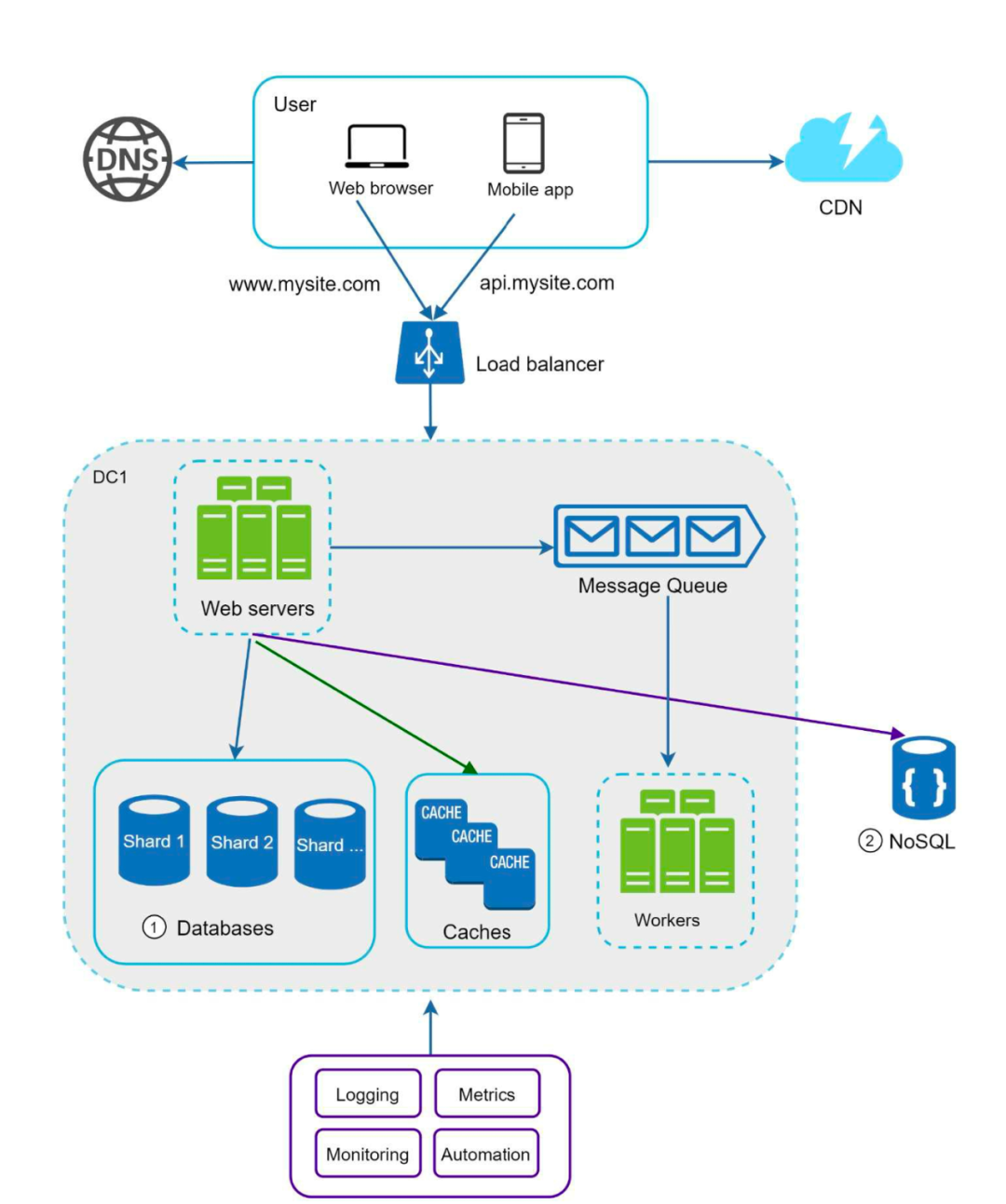
点评
第一章感觉说了很多,又感觉什么都没说。整体看内容还是比较浅显的,不少都是点到即止。
不管怎么说,我们都已经上路了。