
【Python】50个Pandas的奇淫技巧:一网打尽各种索引 iloc,loc,ix,iat,at…
数据处理,也是风控非常重要的一个环节,甚至说是模型成败的关键环节。因此,娴熟简洁的数据处理技巧,是提高建模效率和建模质量的必要能力。这里开个专题,总结下Pandas的使用方法,方便大家,也方便自己查阅。
这个专题叫做:【50个Pandas的奇淫技巧】,今天这个算是第一讲,后续慢慢更新。
一、Pandas索引概述
很多人在使用Pandas处理数据时,总会迷失在data[]、iloc()、loc()、ix()中,似乎记得,又似乎不记得,每到用时都需要百度,不知所以然的解决了问题,下次继续百度,记忆点基本上非常混乱。总结本文,希望能解决这个问题,通过一个简单的案例彻底搞明白这几种索引方法到底有什么区别。
日常使用中,推荐使用loc和iloc进行索引,loc是指location的意思,iloc中的 i 是指integer,这两个方法容易混淆,可以使用特殊方式来加强记忆。
iloc:基于位置,用行号、列号进行索引,i 可以看着 int,因此 iloc 只能用整数 来索引,例如data.iloc[0:2,:]
loc :基于标签,用行名、列名进行索引,数据的index经常为整数,因此 loc 的使用范围要远高于iloc,loc可以使用整数切片、名称(index,columns)索引、也可以切片和名称混合使用。例如:data.loc[0:5:,'row1':'row2']
我们简单构造一个数据集,在下面的案例中需要用到。
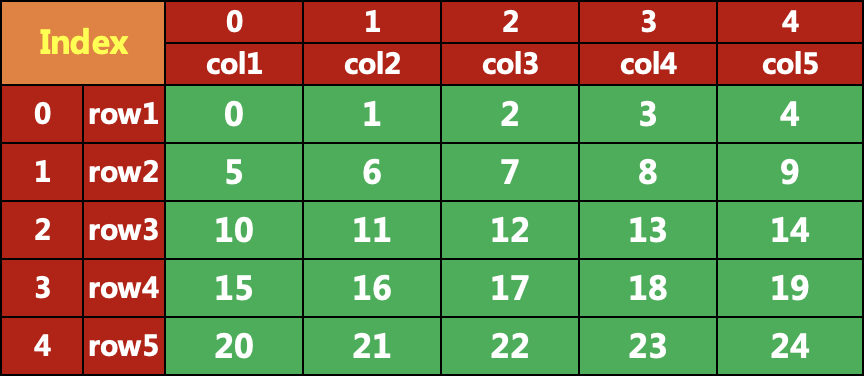
import pandas as pdimport numpy as npdata = pd.DataFrame(np.arange(25).reshape(5, 5),index = ['row1', 'row2','row3','row4','row5'],columns=['col1', 'col2','col3','col4','col5'])datacol1 col2 col3 col4 col5row1 0 1 2 3 4row2 5 6 7 8 9row3 10 11 12 13 14row4 15 16 17 18 19row5 20 21 22 23 24
创建的表格数据如下:
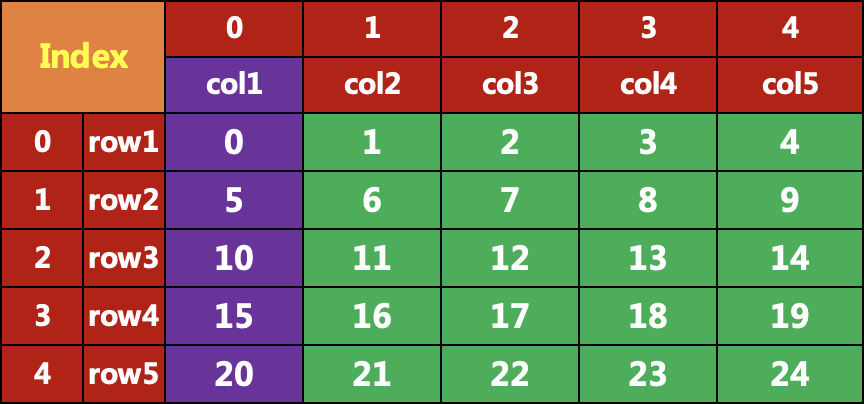
二、直接用列名索引
取一列:data['col1'] ,即取得第一列,得到的是一个Series对象。
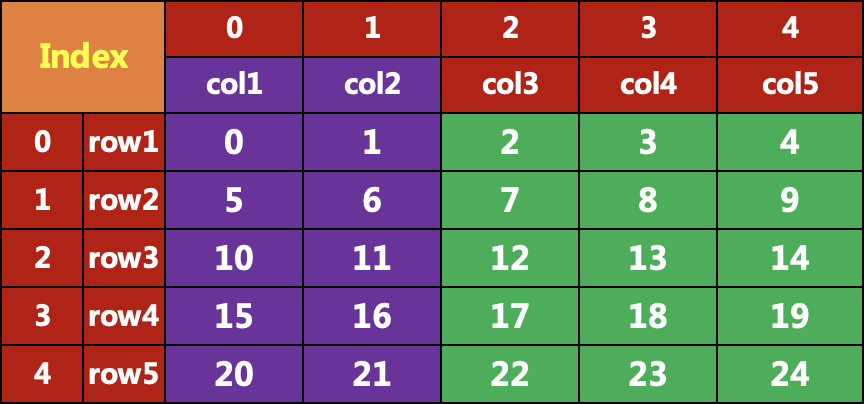
取多列:data[['col1','col2']] ,即取得第一列、第二列,得到的是一个DataFrame对象。
注 意:用data['row1'] 、data[0]、data[:,0]、data[0,:]、data[:,'col1':'col2'] 统统都会报错的,这类命令只能用来按列名取一列或多列。
data['col1']row1 0row2 5row3 10row4 15row5 20
data[['col1','col2']]col1 col2row1 0 1row2 5 6row3 10 11row4 15 16row5 20 21#下面的命令直接应用都会报错,但是用loc 和 iloc 就不会报错data['row1']data[0]data[:,0]data[0,:]data[:,'col1':'col2']#TypeError: '(slice(None, None, None), 0)' is an invalid ke
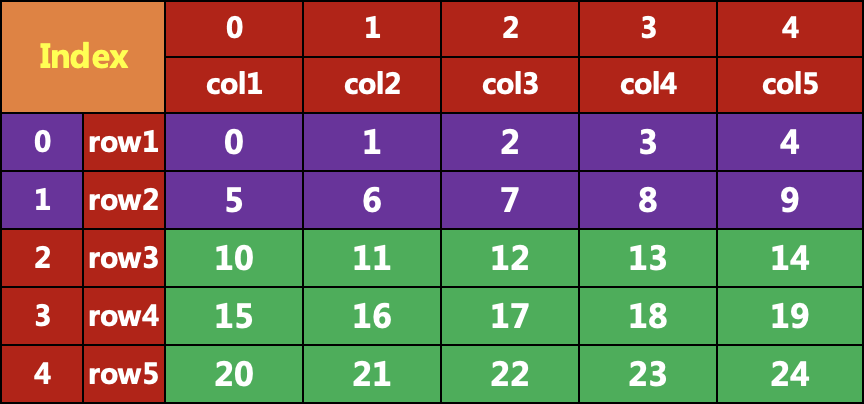
三、直接用行号索引
data[0:2] 代表取得第0行和第1行,不包含最后一个。
注 意:只取一行的话,要用data[0:1],不能用data[0],data[0:2,]也会报错
:2]col1 col2 col3 col4 col5row1 0 1 2 3 4row2 5 6 7 8 9
四、iloc按行号、列号索引
官方:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.iloc.html
1、行索引
1)取一行 :data.iloc[0] 、data.iloc[0,:]
2)取多行 :data.iloc[[0,2]] 、data.iloc[[0,2],:]
3)取连续多行 :data.iloc[0:2] 、data.iloc[0:2,:]
2、列索引
4)取一列 :data.iloc[:,0]
5)取多列 :data.iloc[:,[0,2]]、data.iloc[:,[0,2]]
6)取连续多列 :data.iloc[:,0:2]
注 意:
取行的时候可以不提列,也可以用 ",:" 来指全列
取列的时候必须用":,"来指定全行。
可以使用一个数字来代表一个,可以使用一个列表[a,b]代表多个,也可以使用a:b代表连续多个。
data.iloc[0]col1 0col2 1col3 2col4 3col5 4
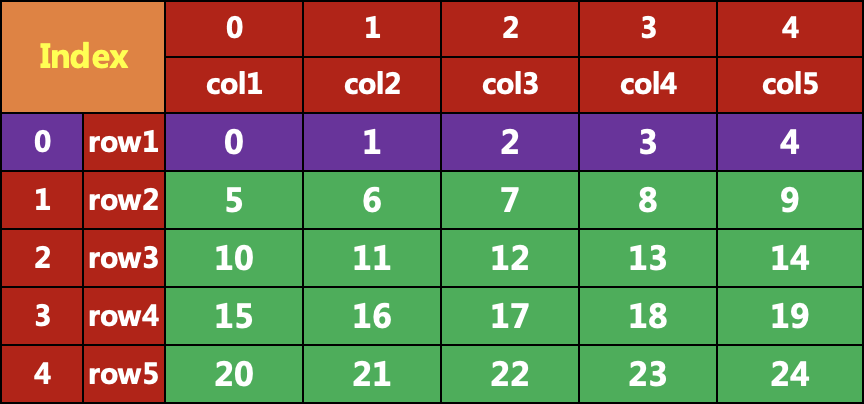
:,2:4]col3 col4row1 2 3row2 7 8row3 12 13row4 17 18row5 22 23
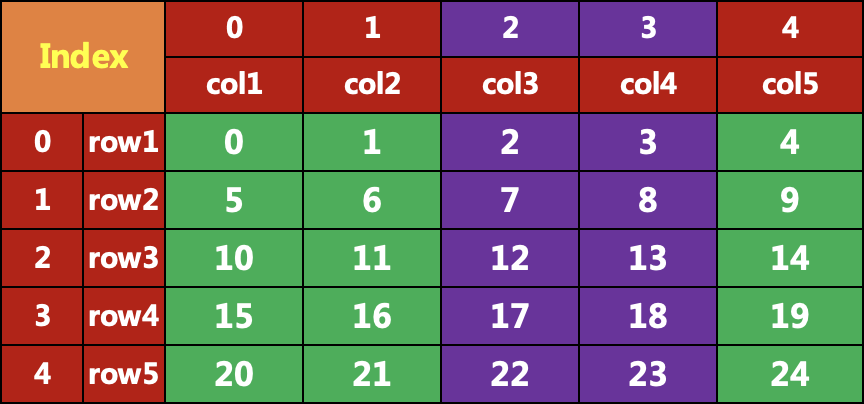
:,[2,4]]col3 col5row1 2 4row2 7 9row3 12 14row4 17 19row5 22 24
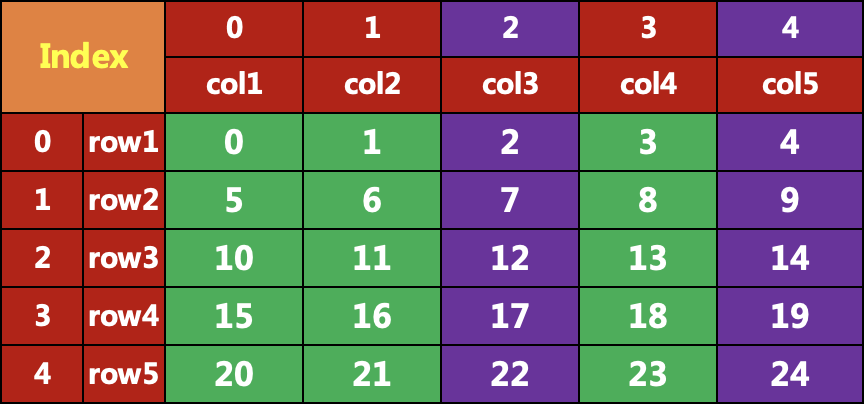
五、loc按行名、列名索引
官方网址:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.loc.html
1、行索引
取一行:data.loc['row1'] 、data.loc['row1',:]
取多行:data.loc[['row1','row2']] 、data.loc[['row1','row2'],:]
取连续多行:data.loc['row1':'row2'] 、data.loc['row1':'row2',:]
2、列索引
取一列:data.loc[:,'col1']
取多列:data.loc[:,['row1','row2']]
取连续多列:data.loc[:,'row1':'row2']
注 意:
取行的时候可以不提列,也可以用",:"来指全列。
取列的时候必须用":,"来指定全行。
可以使用一个数字来代表一个,可以使用一个list ['a','b']代表多个,也可以使用'a':'b'代表连续多个。
:,'col1':'col3']col1 col2 col3row1 0 1 2row2 5 6 7row3 10 11 12row4 15 16 17row5 20 21 22
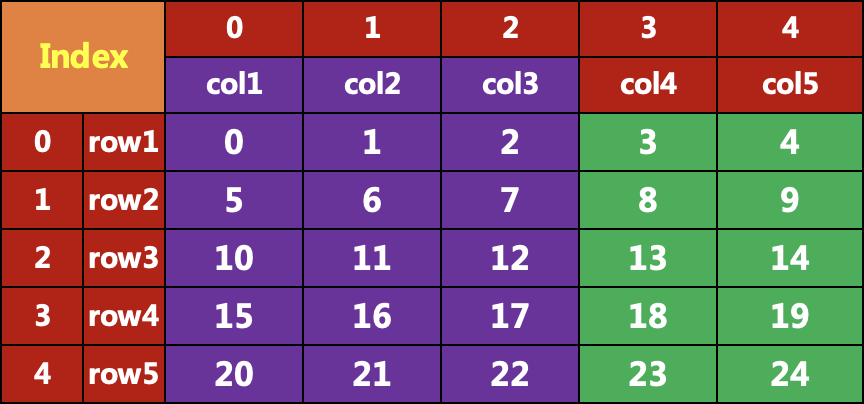
:,['col1','col3']]col1 col3row1 0 2row2 5 7row3 10 12row4 15 17row5 20 22
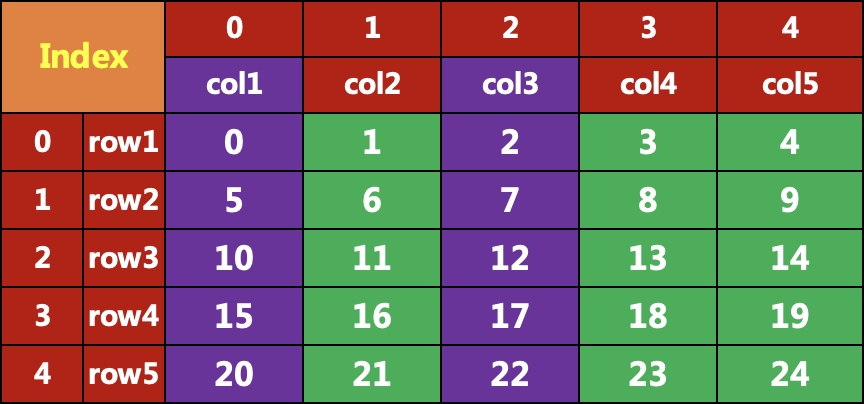
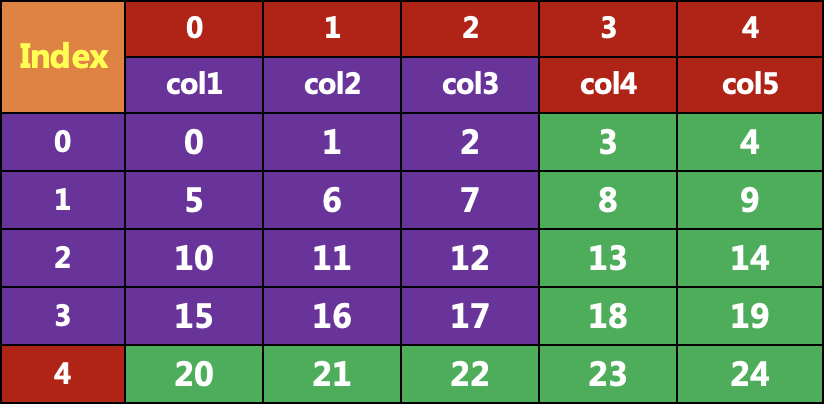
#当索引为整数时,可以用整数进行索引data = pd.DataFrame(np.arange(25).reshape(5, 5),columns=['col1', 'col2','col3','col4', 'col5'])col1 col2 col3 col4 col50 0 1 2 3 41 5 6 7 8 92 10 11 12 13 143 15 16 17 18 194 20 21 22 23 24:3,'col1':'col3']col1 col2 col30 0 1 21 5 6 72 10 11 123 15 16 17
六、使用iat和at
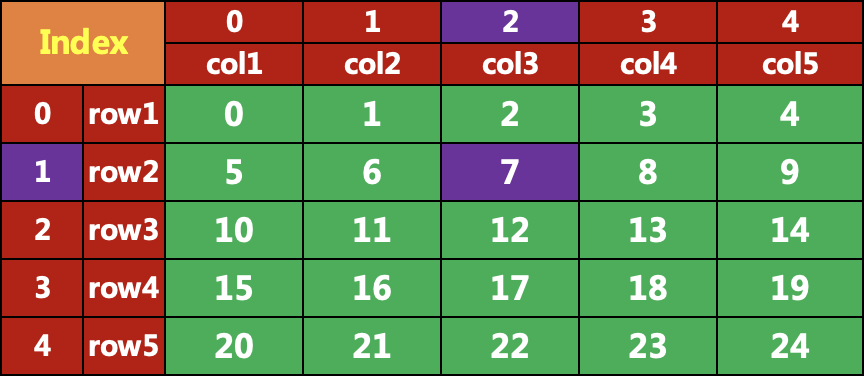
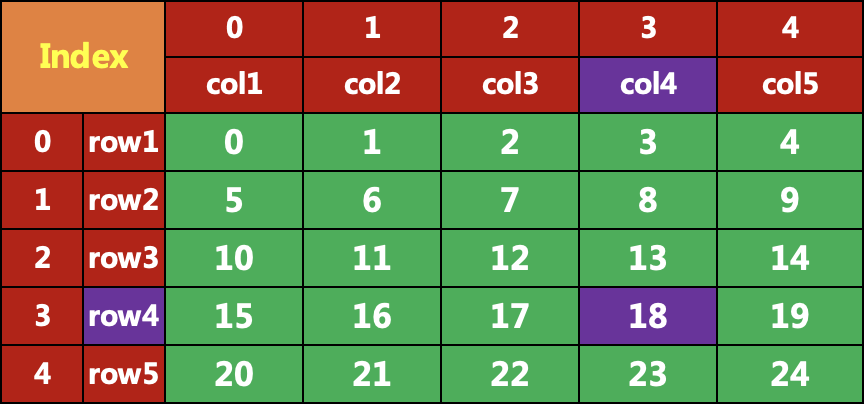
iat 和 at 只能取单个元素,iat 使用行、列索引,at 使用行、列名,但是其功能被 iloc 和 loc 包含,因此不推荐。
data.iat[1,2]7
data.at['row4','col4']18
七、最后总结(重点!!!!)
正常情况下,推荐使用 iloc 和 loc。最核心的点记住,取行可以不提列,取列必须提行,可以用一个数字,一个list,或者一个区间来取行列。ix新版的已经弃用了,所以可以不用太关注。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码: