
离线识别率高达99%的Python人脸识别系统,开源~
来源:https://zhuanlan.zhihu.com/p/46931078
以往的人脸识别主要是包括人脸图像采集、人脸识别预处理、身份确认、身份查找等技术和系统。现在人脸识别已经慢慢延伸到了ADAS中的驾驶员检测、行人跟踪、甚至到了动态物体的跟踪。
由此可以看出,人脸识别系统已经由简单的图像处理发展到了视频实时处理。而且算法已经由以前的Adaboots、PCA等传统的统计学方法转变为CNN、RCNN等深度学习及其变形的方法。现在也有相当一部分人开始研究3维人脸识别识别,这种项目目前也受到了学术界、工业界和国家的支持。
首先看看现在的研究现状。如上的发展趋势可以知道,现在的主要研究方向是利用深度学习的方法解决视频人脸识别。
主要的研究人员:
如下:中科院计算所的山世光教授、中科院生物识别研究所的李子青教授、清华大学的苏光大教授、香港中文大学的汤晓鸥教授、Ross B. Girshick等等。
主要开源项目:
SeetaFace人脸识别引擎。该引擎由中科院计算所山世光研究员带领的人脸识别研究组研发。代码基于C++实现,且不依赖于任何第三方的库函数,开源协议为BSD-2,可供学术界和工业界免费使用。
主要软件API/SDK:
face++。Face++.com 是一个提供免费人脸检测、人脸识别、人脸属性分析等服务的云端服务平台。Face++是北京旷视科技有限公司旗下的全新人脸技术云平台,在黑马大赛中,Face++获得年度总冠军,已获得联想之星投资。
skybiometry.。主要包含了face detection、face recognition、face grouping。
主要的人脸识别图像库:
目前公开的比较好的人脸图像库有LFW(Labelled Faces in the Wild)和YFW(Youtube Faces in the Wild)。现在的实验数据集基本上是来源于LFW,而且目前的图像人脸识别的精度已经达到99%,基本上现有的图像数据库已经被刷爆。下面是现有人脸图像数据库的总结:

现在在中国做人脸识别的公司已经越来越多,应用也非常的广泛。其中市场占有率最高的是汉王科技。主要公司的研究方向和现状如下:
汉王科技:汉王科技主要是做人脸识别的身份验证,主要用在门禁系统、考勤系统等等。
科大讯飞:科大讯飞在香港中文大学汤晓鸥教授团队支持下,开发出了一个基于高斯过程的人脸识别技术–Gussian face, 该技术在LFW上的识别率为98.52%,目前该公司的DEEPID2在LFW上的识别率已经达到了99.4%。
川大智胜:目前该公司的研究亮点是三维人脸识别,并拓展到3维全脸照相机产业化等等。
商汤科技:主要是一家致力于引领人工智能核心“深度学习”技术突破,构建人工智能、大数据分析行业解决方案的公司,目前在人脸识别、文字识别、人体识别、车辆识别、物体识别、图像处理等方向有很强的竞争力。在人脸识别中有106个人脸关键点的识别。
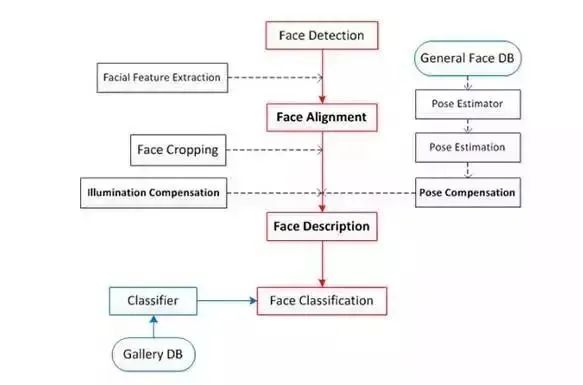
人脸识别的过程
人脸识别主要分为四大块:人脸定位(face detection)、 人脸校准(face alignment)、 人脸确认(face verification)、人脸鉴别(face identification)。
人脸定位(face detection):
对图像中的人脸进行检测,并将结果用矩形框框出来。在openCV中有直接能拿出来用的Harr分类器。
人脸校准(face alignment):
对检测到的人脸进行姿态的校正,使其人脸尽可能的”正”,通过校正可以提高人脸识别的精度。校正的方法有2D校正、3D校正的方法,3D校正的方法可以使侧脸得到较好的识别。在进行人脸校正的时候,会有检测特征点的位置这一步,这些特征点位置主要是诸如鼻子左侧,鼻孔下侧,瞳孔位置,上嘴唇下侧等等位置,知道了这些特征点的位置后,做一下位置驱动的变形,脸即可被校”正”了。如下图所示:

这里介绍一种MSRA在14年的技术:Joint Cascade Face Detection and Alignment(ECCV14)。这篇文章直接在30ms的时间里把detection和alignment都给做了。
人脸确认(face verification):
Face verification,人脸校验是基于pair matching的方式,所以它得到的答案是“是”或者“不是”。在具体操作的时候,给定一张测试图片,然后挨个进行pair matching,matching上了则说明测试图像与该张匹配上的人脸为同一个人的人脸。
一般在小型办公室人脸刷脸打卡系统中采用的(应该)是这种方法,具体操作方法大致是这样一个流程:离线逐个录入员工的人脸照片(一个员工录入的人脸一般不止一张),员工在刷脸打卡的时候相机捕获到图像后,通过前面所讲的先进行人脸检测,然后进行人脸校正,再进行人脸校验,一旦match结果为“是”,说明该名刷脸的人员是属于本办公室的,人脸校验到这一步就完成了。
在离线录入员工人脸的时候,我们可以将人脸与人名对应,这样一旦在人脸校验成功后,就可以知道这个人是谁了。上面所说的这样一种系统优点是开发费用低廉,适合小型办公场所,缺点是在捕获时不能有遮挡,而且还要求人脸姿态比较正(这种系统我们所有,不过没体验过)。下图给出了示意说明:

人脸识别(face identification/recognition):
Face identification或Face recognition,人脸识别正如下图所示的,它要回答的是“我是谁?”,相比于人脸校验采用的pair matching,它在识别阶段更多的是采用分类的手段。它实际上是对进行了前面两步即人脸检测、人脸校正后做的图像(人脸)分类。
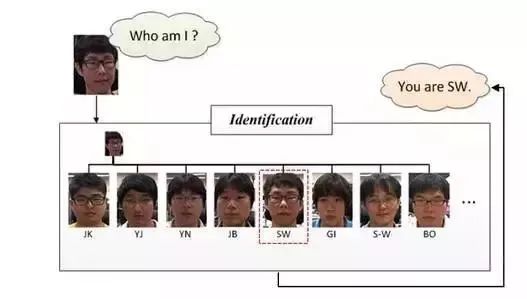
根据上面四个概念的介绍,我们可以了解到人脸识别主要包括三个大的、独立性强的模块:
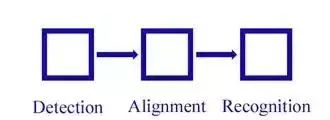
我们将上面的步骤进行详细的拆分,得到下面的过程图:
人脸识别分类
现在随着人脸识别技术的发展,人脸识别技术主要分为了三类:一是基于图像的识别方法、二是基于视频的识别方法、三是三维人脸识别方法。
基于图像的识别方法:
这个过程是一个静态的图像识别过程,主要利用图像处理。主要的算法有PCA、EP、kernel method、 Bayesian Framwork、SVM 、HMM、Adaboot等等算法。但在2014年,人脸识别利用Deep learning 技术取得了重大突破,为代表的有deepface的97.25%、face++的97.27%,但是deep face的训练集是400w集的,而同时香港中文大学汤晓鸥的Gussian face的训练集为2w。
基于视频的实时识别方法:
这个过程可以看出人脸识别的追踪过程,不仅仅要求在视频中找到人脸的位置和大小,还需要确定帧间不同人脸的对应关系。
DeepFace
参考论文(资料):
1. DeepFace论文。DeepFace:Closing the Gap to Human-level Performance in Face Verificaion
2. 卷积神经网络了解博客。http://blog.csdn.net/zouxy09/article/details/8781543
3. 卷积神经网络的推导博客。http://blog.csdn.net/zouxy09/article/details/9993371/
4. Note on convolution Neural Network.
5. Neural Network for Recognition of Handwritten Digits
6. DeepFace博文:http://blog.csdn.net/Hao_Zhang_Vision/article/details/52831399?locationNum=2&fps=1
DeepFace是FaceBook提出来的,后续有DeepID和FaceNet出现。而且在DeepID和FaceNet中都能体现DeepFace的身影,所以DeepFace可以谓之CNN在人脸识别的奠基之作,目前深度学习在人脸识别中也取得了非常好的效果。所以这里我们先从DeepFace开始学习。
在DeepFace的学习过程中,不仅将DeepFace所用的方法进行介绍,也会介绍当前该步骤的其它主要算法,对现有的图像人脸识别技术做一个简单、全面的叙述。
DeepFace的基本框架
1. 人脸识别的基本流程
face detection -> face alignment -> face verification -> face identification
2.人脸检测(face detection)
2.1 现有技术:
haar分类器:
人脸检测(detection)在opencv中早就有直接能拿来用的haar分类器,基于Viola-Jones算法。
Adaboost算法(级联分类器):
1.参考论文:Robust Real-Time face detection 。
2. 参考中文博客:http://blog.csdn.net/cyh_24/article/details/39755661
3. 博客:http://blog.sina.com.cn/s/blog_7769660f01019ep0.html
2.2 文章中所用方法
本文中采用了基于检测点的人脸检测方法(fiducial Point Detector)。
先选择6个基准点,2只眼睛中心、 1个鼻子点、3个嘴上的点。
通过LBP特征用SVR来学习得到基准点。
效果如下:

3. 人脸校准(face alignment)
2D alignment:
对Detection后的图片进行二维裁剪, scale, rotate and translate the image into six anchor locations。将人脸部分裁剪出来。
3D alignment:
找到一个3D 模型,用这个3D模型把二维人脸crop成3D人脸。67个基点,然后Delaunay三角化,在轮廓处添加三角形来避免不连续。
将三角化后的人脸转换成3D形状
三角化后的人脸变为有深度的3D三角网
将三角网做偏转,使人脸的正面朝前
最后放正的人脸
效果如下:
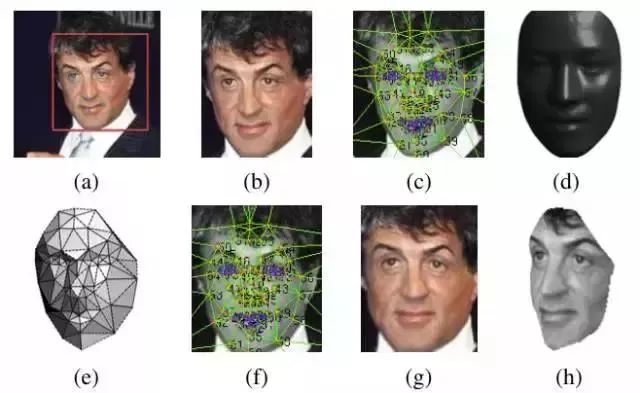
上面的2D alignment对应(b)图,3D alignment依次对应(c) ~ (h)。
4 人脸表示(face verification)
4.1 现有技术
LBP && joint Beyesian:
通过高维LBP跟Joint Bayesian这两个方法结合。
论文:Bayesian Face Revisited: A Joint Formulation
DeepID系列:
将七个联合贝叶斯模型使用SVM进行融合,精度达到99.15%
论文:Deep Learning Face Representation by Joint Identification-Verification
4.2 文章中的方法
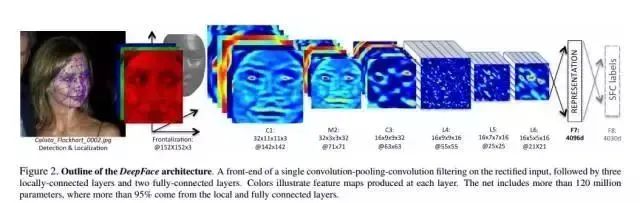
论文中通过一个多类人脸识别任务来训练深度神经网络(DNN)。网络结构如上图所示。
结构参数:
经过3D对齐以后,形成的图像都是152×152的图像,输入到上述网络结构中,该结构的参数如下:
Conv:32个11×11×3的卷积核
max-pooling: 3×3, stride=2
Conv: 16个9×9的卷积核
Local-Conv: 16个9×9的卷积核,Local的意思是卷积核的参数不共享
Local-Conv: 16个7×7的卷积核,参数不共享
Local-Conv: 16个5×5的卷积核,参数不共享
Fully-connected: 4096维
Softmax: 4030维
提取低水平特征:
过程如下所示:
预处理阶段:输入3通道的人脸,并进行3D校正,再归一化到152*152像素大小——152*152*3.
通过卷积层C1:C1包含32个11*11*3的滤波器(即卷积核),得到32张特征图——32*142*142*3。
通过max-polling层M2:M2的滑窗大小为3*3,滑动步长为2,3个通道上分别独立polling。
通过另一个卷积层C3:C3包含16个9*9*16的3维卷积核。
上述3层网络是为了提取到低水平的特征,如简单的边缘特征和纹理特征。Max-polling层使得卷积网络对局部的变换更加鲁棒。如果输入是校正后的人脸,就能使网络对小的标记误差更加鲁棒。
然而这样的polling层会使网络在面部的细节结构和微小纹理的精准位置上丢失一些信息。因此,文中只在第一个卷积层后面接了Max-polling层。这些前面的层称之为前端自适应的预处理层级。然而对于许多计算来讲,这是很必要的,这些层的参数其实很少。它们仅仅是把输入图像扩充成一个简单的局部特征集。
后续层:
L4,L5,L6都是局部连接层,就像卷积层使用滤波器一样,在特征图像的每一个位置都训练学习一组不同的滤波器。由于校正后不同区域的有不同的统计特性,卷积网络在空间上的稳定性的假设不能成立。比如说,相比于鼻子和嘴巴之间的区域,眼睛和眉毛之间的区域展现出非常不同的表观并且有很高的区分度。换句话说,通过利用输入的校正后的图像,定制了DNN的结构。
使用局部连接层并没有影响特征提取时的运算负担,但是影响了训练的参数数量。仅仅是由于有如此大的标记人脸库,我们可以承受三个大型的局部连接层。局部连接层的输出单元受到一个大型的输入图块的影响,可以据此调整局部连接层的使用(参数)(不共享权重)
比如说,L6层的输出受到一个74*74*3的输入图块的影响,在校正后的人脸中,这种大的图块之间很难有任何统计上的参数共享。
顶层:
最后,网络顶端的两层(F7,F8)是全连接的:每一个输出单元都连接到所有的输入。这两层可以捕捉到人脸图像中距离较远的区域的特征之间的关联性。比如,眼睛的位置和形状,与嘴巴的位置和形状之间的关联性(这部分也含有信息)可以由这两层得到。第一个全连接层F7的输出就是我们原始的人脸特征表达向量。
在特征表达方面,这个特征向量与传统的基于LBP的特征描述有很大区别。传统方法通常使用局部的特征描述(计算直方图)并用作分类器的输入。
最后一个全连接层F8的输出进入了一个K-way的softmax(K是类别个数),即可产生类别标号的概率分布。用Ok表示一个输入图像经过网络后的第k个输出,即可用下式表达输出类标号k的概率:
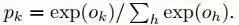
训练的目标是最大化正确输出类别(face 的id)的概率。通过最小化每个训练样本的叉熵损失实现这一点。用k表示给定输入的正确类别的标号,则叉熵损失是:
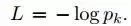
通过计算叉熵损失L对参数的梯度以及使用随机梯度递减的方法来最小化叉熵损失。
梯度是通过误差的标准反向传播来计算的。非常有趣的是,本网络产生的特征非常稀疏。超过75%的顶层特征元素是0。这主要是由于使用了ReLU激活函数导致的。这种软阈值非线性函数在所有的卷积层,局部连接层和全连接层(除了最后一层F8)都使用了,从而导致整体级联之后产生高度非线性和稀疏的特征。稀疏性也与使用使用dropout正则化有关,即在训练中将随机的特征元素设置为0。我们只在F7全连接层使用了dropout.由于训练集合很大,在训练过程中我们没有发现重大的过拟合。
给出图像I,则其特征表达G(I)通过前馈网络计算出来,每一个L层的前馈网络,可以看作是一系列函数:

归一化:
在最后一级,我们把特征的元素归一化成0到1,以此降低特征对光照变化的敏感度。特征向量中的每一个元素都被训练集中对应的最大值除。然后进行L2归一化。由于我们采用了ReLU激活函数,我们的系统对图像的尺度不变性减弱。
对于输出的4096-d向量:
先每一维进行归一化,即对于结果向量中的每一维,都要除以该维度在整个训练集上的最大值。
每个向量进行L2归一化。
2. 验证
2.1 卡方距离
该系统中,归一化后的DeepFace特征向量与传统的基于直方图的特征(如LBP)有一下相同之处:
所有值均为负
非常稀疏
特征元素的值都在区间 [0, 1]之间
卡方距离计算公式如下:
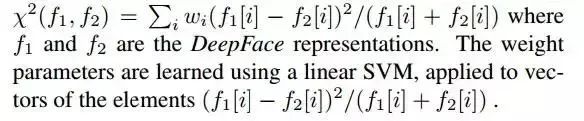
2.2 Siamese network
文章中也提到了端到端的度量学习方法,一旦学习(训练)完成,人脸识别网络(截止到F7)在输入的两张图片上重复使用,将得到的2个特征向量直接用来预测判断这两个输入图片是否属于同一个人。这分为以下步骤:
a. 计算两个特征之间的绝对差别;
b,一个全连接层,映射到一个单个的逻辑单元(输出相同/不同)。
3. 实验评估
3.1 数据集
Social Face Classification Dataset(SFC): 4.4M张人脸/4030人
LFW: 13323张人脸/5749人
restricted: 只有是/不是的标记
unrestricted:其他的训练对也可以拿到
unsupervised:不在LFW上训练
Youtube Face(YTF): 3425videos/1595人
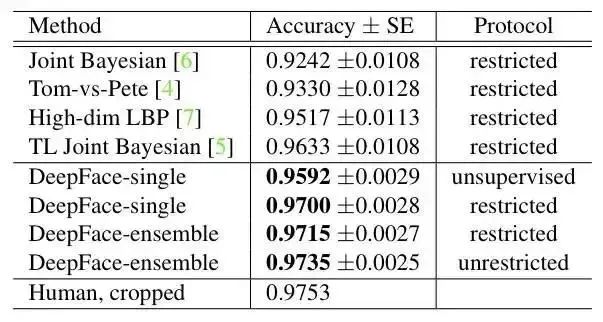
result on LFW:
result on YTF:
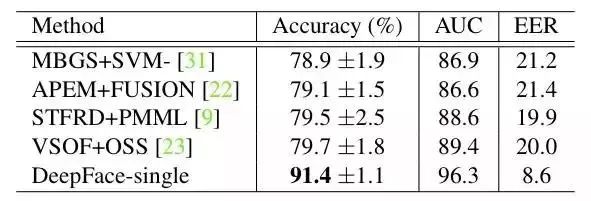
DeepFace与之后的方法的最大的不同点在于,DeepFace在训练神经网络前,使用了对齐方法。论文认为神经网络能够work的原因在于一旦人脸经过对齐后,人脸区域的特征就固定在某些像素上了,此时,可以用卷积神经网络来学习特征。
本文的模型使用了C++工具箱dlib基于深度学习的最新人脸识别方法,基于户外脸部数据测试库Labeled Faces in the Wild 的基准水平来说,达到了99.38%的准确率。
更多算法
http://www.gycc.com/trends/face%20recognition/overview/
dlib:http://dlib.net/数据测试库Labeled Faces in the Wild:http://vis-www.cs.umass.edu/lfw/
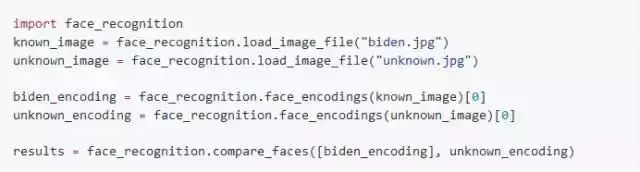
模型提供了一个简单的 face_recognition 命令行工具让用户通过命令就能直接使用图片文件夹进行人脸识别操作。
在图片中捕捉人脸特征
在一张图片中捕捉到所有的人脸

找到并处理图片中人脸的特征
找到每个人眼睛、鼻子、嘴巴和下巴的位置和轮廓。
import face_recognition
image = face_recognition.load_image_file("your_file.jpg")
face_locations = face_recognition.face_locations(image)

捕捉脸部特征有很重要的用途,当然也可以用来进行图片的数字美颜digital make-up(例如美图秀秀)
digital make-up:https://github.com/ageitgey/face_recognition/blob/master/examples/digital_makeup.py
识别图片中的人脸
识别谁出现在照片里
安装步骤
本方法支持Python3/python2,我们只在macOS和Linux中测试过,还不知是否适用于Windows。
使用pypi的pip3 安装此模块(或是Python 2的pip2)
重要提示:在编译dlib时可能会出问题,你可以通过安装来自源(而不是pip)的dlib来修复错误,请见安装手册How to install dlib from source
https://gist.github.com/ageitgey/629d75c1baac34dfa5ca2a1928a7aeaf
通过手动安装dlib,运行pip3 install face_recognition来完成安装。
使用方法命令行界面
当你安装face_recognition,你能得到一个简洁的叫做face_recognition的命令行程序,它能帮你识别一张照片或是一个照片文件夹中的所有人脸。
首先,你需要提供一个包含一张照片的文件夹,并且你已经知道照片中的人是谁,每个人都要有一张照片文件,且文件名需要以该人的姓名命名;
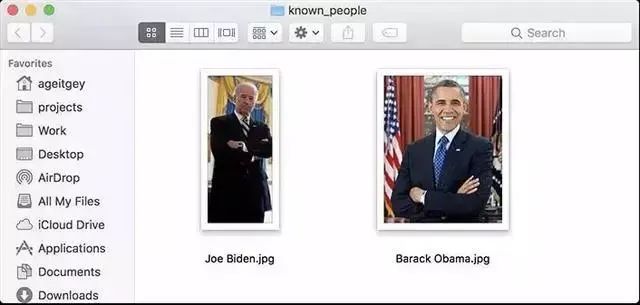
然后你需要准备另外一个文件夹,里面装有你想要识别人脸照片;
接下来你只用运行face_recognition命令,程序能够通过已知人脸的文件夹识别出未知人脸照片中的人是谁;

针对每个人脸都要一行输出,数据是文件名加上识别到的人名,以逗号分隔。
如果你只是想要知道每个照片中的人名而不要文件名,可以进行如下操作:

Python模块
你可以通过引入face_recognition就能完成人脸识别操作:
API 文档: https://face-recognition.readthedocs.io.
在图片中自动识别所有人脸
请参照此案例this example: https://github.com/ageitgey/face_recognition/blob/master/examples/find_faces_in_picture.py
识别图片中的人脸并告知姓名
请参照此案例this example: https://github.com/ageitgey/face_recognition/blob/master/examples/recognize_faces_in_pictures.py
Python代码案例
所有例子在此 here.
https://github.com/ageitgey/face_recognition/tree/master/examples
·找到照片中的人脸Find faces in a photograph
https://github.com/ageitgey/face_recognition/blob/master/examples/find_faces_in_picture.py· 识别照片中的面部特征Identify specific facial features in a photographhttps://github.com/ageitgey/face_recognition/blob/master/examples/find_facial_features_in_picture.py· 使用数字美颜Apply (horribly ugly) digital make-uphttps://github.com/ageitgey/face_recognition/blob/master/examples/digital_makeup.py·基于已知人名找到并识别出照片中的未知人脸Find and recognize unknown faces in a photograph based on photographs of known peoplehttps://github.com/ageitgey/face_recognition/blob/master/examples/recognize_faces_in_pictures.pypython人脸
好了,今天的分享就到这里~