
最美的不是下雨天
前面写了一篇下厨房的爬虫和一篇网易云的爬虫,今天来写一写QQ音乐的爬虫,我会尽量写的详细一点。
python爬虫最基础的用法,request.get方法。
是的,你没有看错,这几行代码,已经是一个最基础的爬虫了。前面import 到入requests库,这是一个封装了urllib的库。url就是你要爬的网址。核心是使用requests.get()方法,你只要把网址传入进去就行。最后打印了status_code,就是响应码,可以看到是成功还是其他问题。返回200就是get成功了。小伙伴可以跟着试一试。import requestsurl = 'http://www.baidu.com'res = requests.get(url)print(res.status_code)
如果你想知道爬了之后返回的内容,可以使用
print(res.content)穿马甲。
我们需要将自己伪装成浏览器,然后去要数据,这样稍微打扮一下,就可以骗过不是很严厉的浏览器服务器。好的,我们重写一下上面的代码。
这次加入了一个headers参数,这个参数描述的是浏览器内核。我们这会儿穿上了谷歌浏览器的马甲,假装我们是谷歌浏览器在向服务器请求数据。另外一个很有效的方法就是适当加一些延时。爬虫程序的效率和人工操作比起来已经快很多了,爬完一个网页之后我们可以等个零点几秒,这样是不是更像人为操作?(正常人一个网页浏览完点击下一页还是要点时间的,我们这里加延时本质目的不是模拟人的行为,而是访问数据不要太快,不要给服务器太大压力,这样它才愿意把数据给你)import requestsurl = 'http://www.baidu.com'headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36",}res = requests.get(url=url,headers=headers)print(res.content)
接下来我们再进阶一下,怎么知道我们要爬取的网站内容呢?估计很多人会把浏览器地址栏的地址复制粘贴下来。那我们可以做个测试,以爬取qq音乐周董的歌为例。网站我给贴这里了,小伙伴可以试一试。
url = 'https://y.qq.com/portal/search.html#page=10&searchid=1&remoteplace=txt.yqq.top&t=song&w=%E5%91%A8%E6%9D%B0%E4%BC%A6'试过的小伙伴就可以看到,打印出来的内容连个周董的名字都没有,就别说歌了。这时候我们就需要在浏览器开发者模式下,找一些蛛丝马迹了。以谷歌浏览器为例,按下F12,进入开发者模式。选中network选项卡import requestsurl = 'https://y.qq.com/portal/search.html#page=10&searchid=1&remoteplace=txt.yqq.top&t=song&w=%E5%91%A8%E6%9D%B0%E4%BC%A6'headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36",}res = requests.get(url=url,headers=headers)print(res.content.decode('utf-8'))
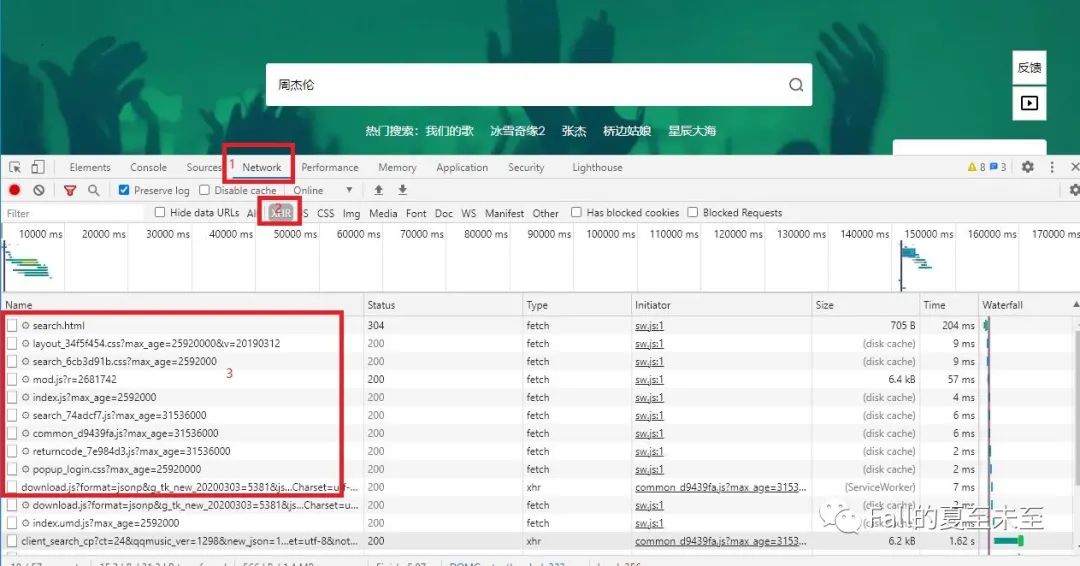
数字2的地方我们选择XHR,可以点开其他类型的看看,都代表是什么意思。打开开发者模式之后,刷新一下网页,可以看到左下角Name下面一大堆数据在刷新。没有经验的朋友可以一个个点开看一下,也可以通过名字来猜测一部分是干嘛的。
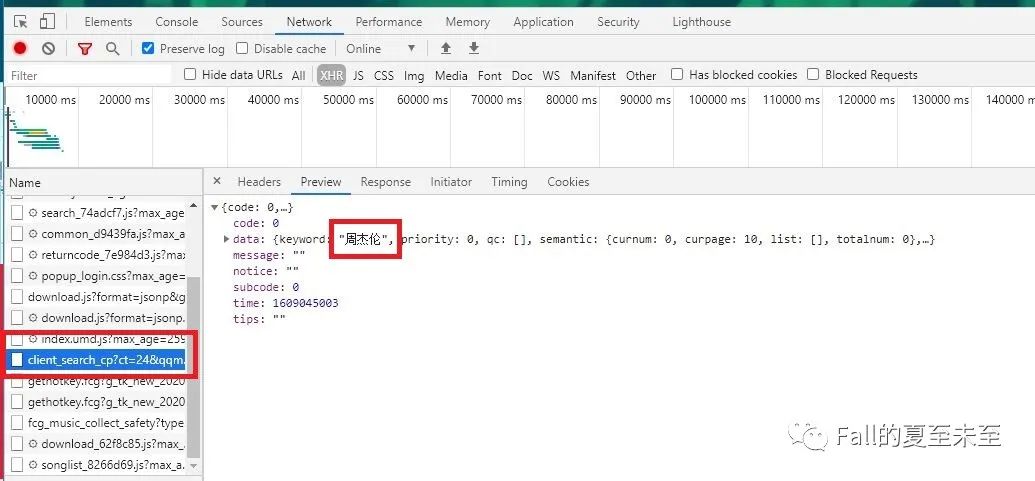
这里已经看到了周杰伦的名字。(上面选项卡点preview),数据是以json格式返回的,data箭头展开,一层层看下去,可以看到有很多歌名。看来这个网页是我们要请求的了。选项卡切换到第一个Headers。
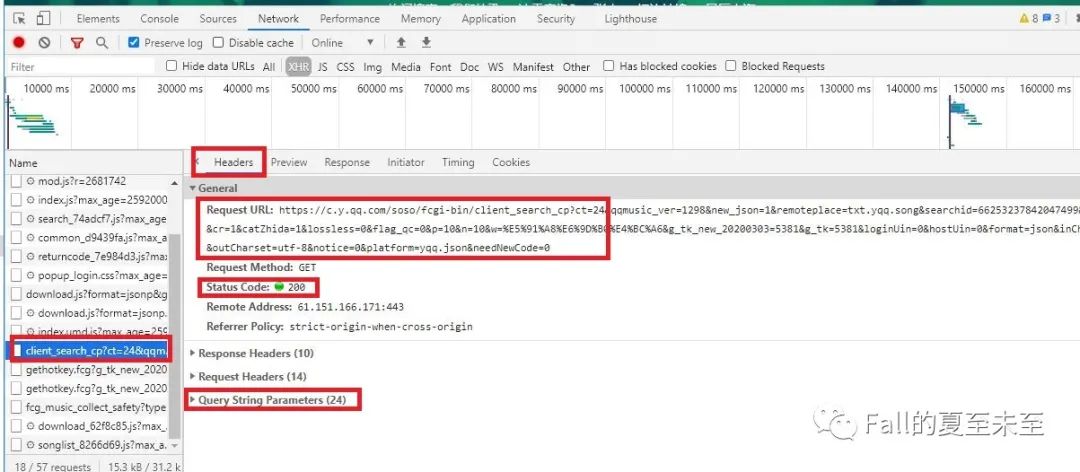
可以看到有一个Request_URL,这个是我们真正需要爬的网址。小伙伴可以试一下,爬一下这个网址看看结果。不出意外,应该可以得到我们刚才在浏览器开发者模式下看到的内容。
再次进阶一下?stop,步子可以慢一点,我们对这一步做一个小小的优化,让代码看起来美观优雅简洁大方。看上面的图可以看到有个query sting parameters的选项。点开可以看到,里面的内容就是request URL里面的地址?后面的内容。于是我们将代码改写成如下格式。
将这些参数以字典的形式打包,使用requests.get方法的时候,带上这些参数去请求数据。同时完善headers信息,添加了'origin','referer'这两个参数。到这里我们已经可以把周杰伦的歌曲搜索结果第一页的内容爬下来了。1页当然不够,可以使用for循环把后面几页也爬下来,我们以前3页为例。import requestsheaders = {'origin': 'https://y.qq.com','referer': 'https://y.qq.com/',"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36",}para = {'ct': '24','qqmusic_ver': '1298','new_json': '1','remoteplace': 'txt.yqq.song','searchid': '66253237842047499','t': '0','aggr': '1','cr': '1','catZhida': '1','lossless': '0','flag_qc': '0','p': '10','n': '10','w': '周杰伦','g_tk_new_20200303': '5381','g_tk': '5381','loginUin': '0','hostUin': '0','format': 'json','inCharset': 'utf8','outCharset': 'utf-8','notice': '0','platform': 'yqq.json','needNewCode': '0',}url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'res = requests.get(url=url,headers=headers,params=para)print(res.content.decode('utf-8'))
from time import sleepfor i in range(1,4):para['p'] = str(i)res = requests.get(url=url,headers=headers,params=para)print(res.content.decode('utf-8'))sleep(1)
到这里完成了第一步。接下来是对爬取下来的内容进行解析。json数据和字典的结构很相似,可以通过字典的'key'来找到想要的数据。以获取歌曲ID和歌名为例。
id_list = []name_list = []json_music = res.json()# 可以先将文件保存下来,再观察数据结构# with open('search.json','wb') as f:# f.write(res.text.encode())list_music = json_music['data']['song']['list']for music in list_music:id_list.append(music['id'])name_list.append(music['name'])
到这一步已经可以顺利的把我们想要的歌曲名和歌曲id(歌曲id是qq音乐使用区分开不同的歌)。
接下来我们再进阶一下,爬取歌曲的歌词。点开第一页搜索到的第一个歌曲晴天。链接如下:
url = 'https://y.qq.com/n/yqq/song/0039MnYb0qxYhV.html'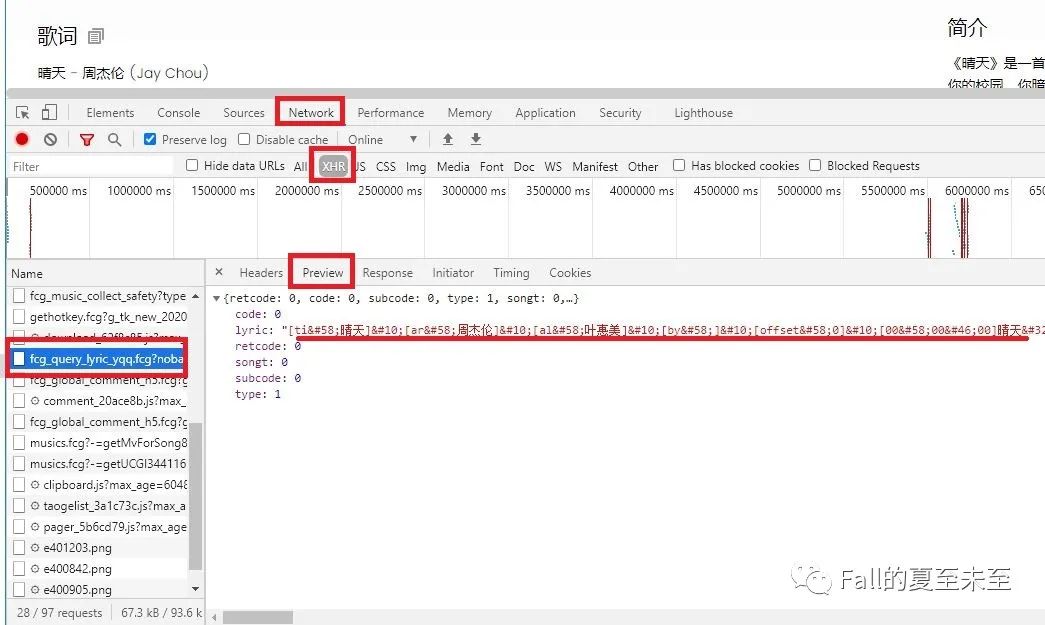
接下来我们需要把前几页的歌曲的歌词都爬下来,同时还需要处理歌词信息,因为返回的结果带了一些我们不想要的字符。这里和刚才一样,使用带参数的get来请求数据。代码如下,其中id list和name list是刚才我们爬取出来的结果保存在list里面,现在我们遍历这个list,把要爬的歌曲爬下来,id是个参数,不同的id对应不同的网站,返回来的歌词结果保存在txt文本里,命名为歌曲名。
def get_song_text():url_link = 'https://c.y.qq.com/lyric/fcgi-bin/fcg_query_lyric_yqq.fcg'para1 = {'nobase64': '1','musicid': '','-': 'jsonp1','g_tk_new_20200303': '5381','g_tk': '5381','loginUin': '0','hostUin': '0','format': 'json','inCharset': 'utf8','outCharset': ' utf-8','notice': '0','platform': 'yqq.json','needNewCode': '0',}count = 0for id in id_list:para1['musicid'] = str(id)music_text = requests.get(url=url_link, headers=headers,params=para1)with open(r'song_text/{}.text'.format(name_list[count]),'wb') as f:f.write(music_text.text.encode())count = count + 1sleep(0.1)
注:下载歌词的时候没有使用多进程或者协程的方式,所以运行速度会偏慢。考虑到理解容易度问题,多进程爬取不在本篇介绍。放一下我的运行结果,爬取前10页100首歌曲的歌词(实际歌词结果是94个,因为有重复的歌曲),用时3分50秒,此处应有歌曲,'能不能给我一首歌的时间'。(家里网速较慢,小伙伴尝试的时候可以看看你们要多久,切换成手机热点之后,50秒爬取结束)。
到这里只剩最后一步,就是对歌词进行解析整理。这里使用正则表达式re。处理方法如下:将每一行的结束替换成换行,中间的停顿换成空格,多余的啰哩吧嗦的全都替换去掉,最后再把周董的英文名左右两边的括号放出来,还有歌曲和演唱者之间的-也放出来。运行了几个文件,效果还是可以的,基本上正确解析出来
with open(file,'r',encoding='utf-8') as f:text = f.read()text = re.sub(r"
", "\n", text)text = re.sub(r"(\[.*]\n)|(\[.*])|(\"})|({.*:\")", "", text)text = re.sub(r" ", " ",text)text = text.replace("(", "(")text = text.replace(")", ")")text = text.replace("-", "-")# print(text)with open(file, 'wb') as f:f.write(text.encode('utf-8'))
现在基本上实现了我们的目标,接下来就是把代码整合一下,再加上一些打印信息。这里我添加了一个进度条,可以看到歌曲歌词下载进度。效果如下:
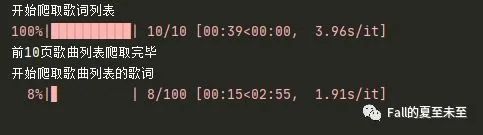
最终成功把QQ音乐周董前10页的歌的歌词下载下来,用时一首歌的时间。(加小半天写代码加小半天写公众号)

相关文章: