
微服务追踪系统
上文我们学习了一下分布式调用链追踪系统的原理和实践,有些读者对其中的实现原理提出了一些疑问,所以有了这篇专门写给小白看的微服务追踪系统,相信大家看完对其原理会有更透彻的理解,这里感谢公号「码农翻身」刘欣老师的指导!
前言
在微服务架构中,一次请求往往涉及到多个模块,多个中间件,多台机器的相互协作才能完成。这一系列调用请求中,有些是串行的,有些是并行的,那么如何确定这个请求背后调用了哪些服务,哪些模块,哪些节点及调用的先后顺序?如何定位每个模块的性能问题?本文将为你揭晓答案。
微服务架构
这是一个稍微复杂的例子
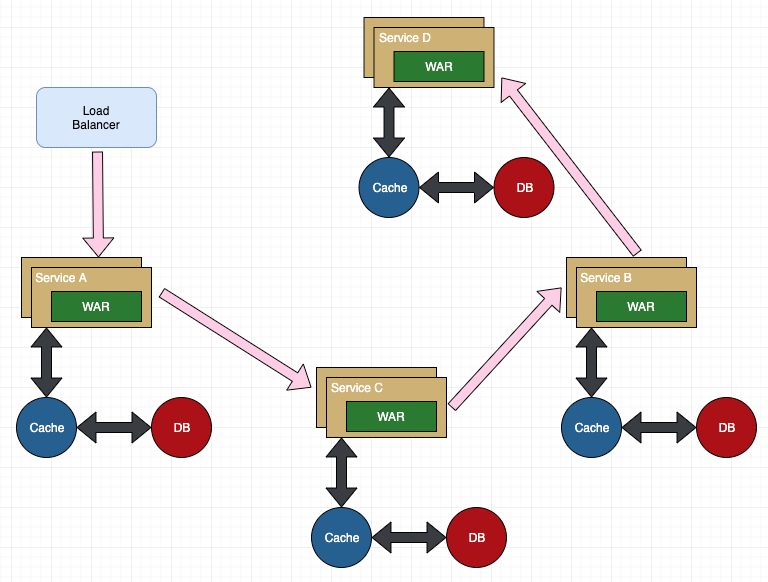
如果有用户反馈某个页面很慢,我们知道这个页面的请求调用链是 A -----> C -----> B -----> D,此时如何定位可能是哪个模块引起的问题呢?
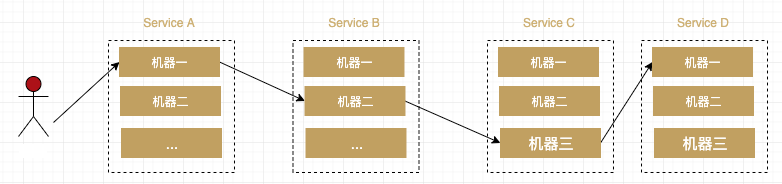
更进一步,如果每个服务 Service A,B,C,D 都部署在好几台机器上。怎么知道某个请求调用了服务的具体哪台机器呢?
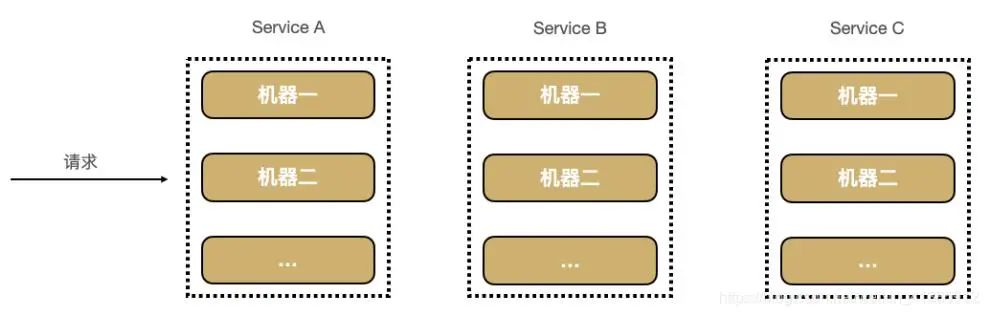
可以明显看到,由于无法准确定位每个请求经过的确切路径,在微服务这种架构下有以下几个痛点:
1. 排查问题难度大,周期长
2. 特定场景难复现
3.系统性能瓶颈分析较难
有没有一种办法可以准确地产生完整的调用链,并且用可视化的方式呈现出来呢?
这就需要一个分布式调用链追踪系统。
分布式调用链追踪系统:设计
想想看,如果要我们自己实现一个这样的分布式追踪系统,该怎么去设计?
首先,我们必须得区分每个调用链(起个时髦的名称叫 Trace),得给它分配一个全局唯一的 ID (称为 TraceID),并且在调用链上的每次调用都带上这个 ID,这样每个子调用都被关联起来了。
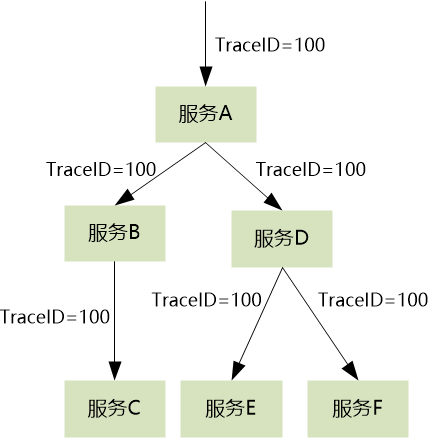
其次,我们得记录所有调用的先后次序和父子关系。
假设有以上这样的调用链,如果我们只记录了这四个调用:
A---->B
B---->C
A---->D
D---->E
D---->F
虽然我们知道它属于一个调用(TraceID 相同),还是无法画出完整的调用拓扑图。
所以必须得记录父子关系:
A---->B 是 B---->C 的父调用
A---->D 是 D---->E 的父调用
A---->D 还是 D---->F 的父调用
如何记录呢?需要给每个调用分配一个ID (称为 SpanID),并且把这个 ID 传递给子调用, 子调用根据 Parent Span ID 生成自己的 SpanID:
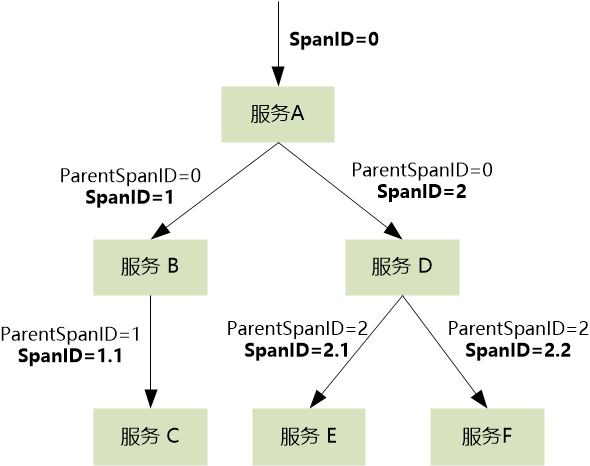
用表格展示是这样:
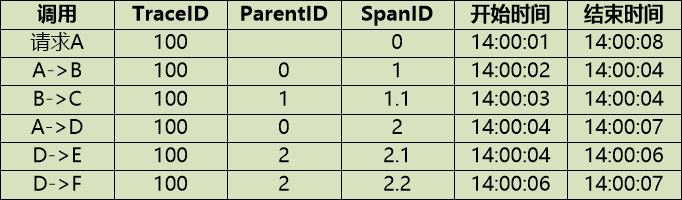
这样根据 id 间的关系就很容易据此画出调用链了(即可视化视图)
魔法师Agent
前面说得挺容易,但是在分布式的环境下,如何才能正确地生成 TraceID, ParentSpanID, SpanID 呢?
微服务是来实现业务的,肯定不能来干这个监控和跟踪的活儿,那样对微服务的侵入性就太强了。
所以必须得有一个独立的组件,在不干扰微服务的情况下,监控微服务之间的调用,把这些 ID 生成, 这个独立的组件就是 Agent。
Agent 要想施展魔法,需要安装在每个服务所在的机器上:
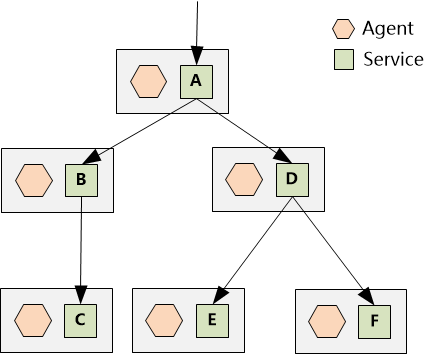
这个魔法师遵循的规则也非常简单,以上图中服务 A 上的 Agent 为例:
1. 当 Agent 监控到有人在调用服务 A,但是没有 ParentSpanID, 它就知道,这是一次全新的调用,应该创建新的 TraceID。
2. 当Agent监控到 A 调用了 B 时, 它就可以生成 SpanID = 1,并且把这个 ID 当作 ParentSpanID 传递给 B。这样当 B 调用 C 的时候, B 的 Agent 就能生成此次调用的 SpanID 为 1.1
3. 当 Agent 监控到 A 调用 D 的时候,可以生成 SpanID = 2, 并且把这个 ID 当作 ParentSpanID 传递给 D
D 在调用 E 和 F 的时候,就能分别生成 SpanID 2.1 和 2.2
你也许注意到了一个问题:微服务都是跨进程调用的,怎么可能把 TraceID , ParentSpanID 在服务之间传来传去呢?
这就需要 Agent 来施展“魔法”了,Agent 需要理解微服务之间的传输协议,然后把 TraceID,ParentSpanID 悄悄地“藏”到某个地方,传递给下一个服务。
例如 HTTP 协议中定义了 Header 与 Body,Header 一般放请求的长度,请求 IP等非业务的信息。业务数据一般放在 Body 中。于是 Agent 就可以把 TraceID,ParentSpanID 悄悄地“藏到” Header 中,这样既不会对 Body 中的业务数据造成影响,又可以把跟踪所需的数据传递给下一个服务了。
你的脑海中可能已经想到 Agent 的实现原理了,这个 Agent 可以这么来实现:
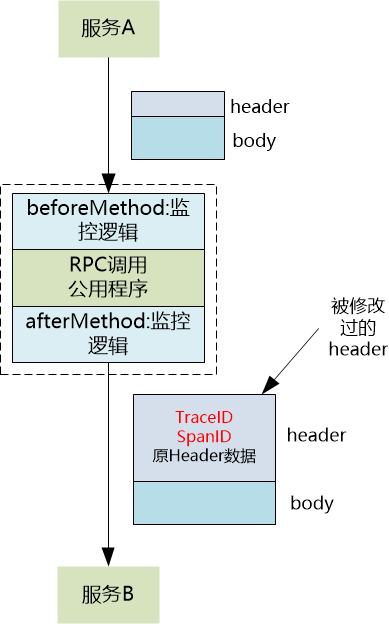
指定微服务中的“RPC 调用的公用程序”(例如 Dubbo 中的 MonitorFilter.invoke方法), 然后在运行时,通过动态修改字节码的方式来增强它:
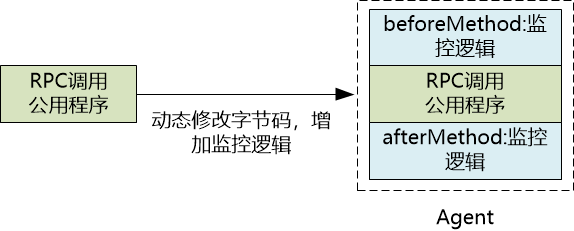
当服务 A 调用服务 B 时, Agent 就可以做点儿手脚,修改 header 了:
数据收集
Agent 虽然监控、生成了足够多的数据,但是单个 Agent 无法获得全局视图,我们需要一个全局的收集器来把 Agent 的数据收集上来,这样才能生成全局的调用链。
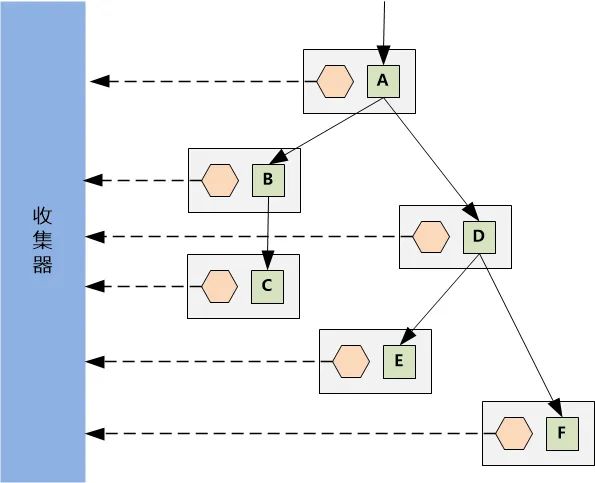
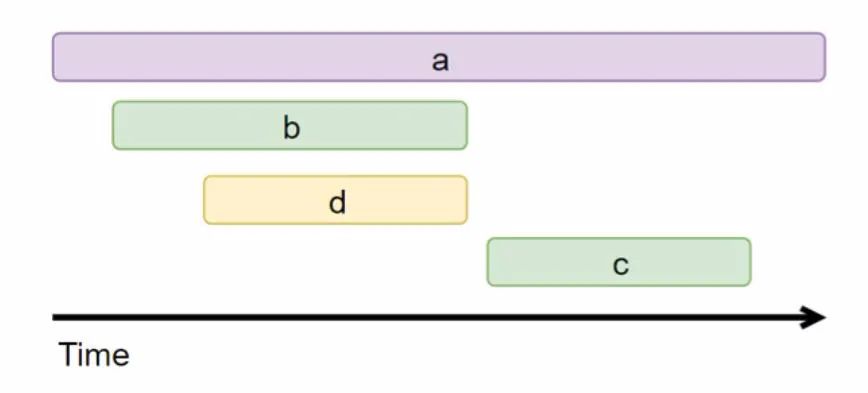
数据收集器获得了全局的数据以后,就可以画出漂亮的调用链的图了,例如这个:
小结
经过一番探索,一个分布式调用链系统的核心组件和实现原理浮出水面,当然,其中还有很多细节需要处理,例如采样的频率,全局唯一 ID 的生成算法,UI界面等等。市面上有不少开源的分布式跟踪系统,如 SkyWalking、Zipkin、Pinpoint 等等,感兴趣的可以继续深入研究。