云端数智新引擎,腾讯云原生数据湖计算重磅发布

引言
你是否遇到过,一个简单的业务统计需求却让数据工程师们抓耳挠腮?
你是否遇到过,业务峰值周期明显,要么资源大量闲置, 要么线上疯狂告警?
你是否遇到过,大数据集群运维复杂,需要投入大量技术工程师?
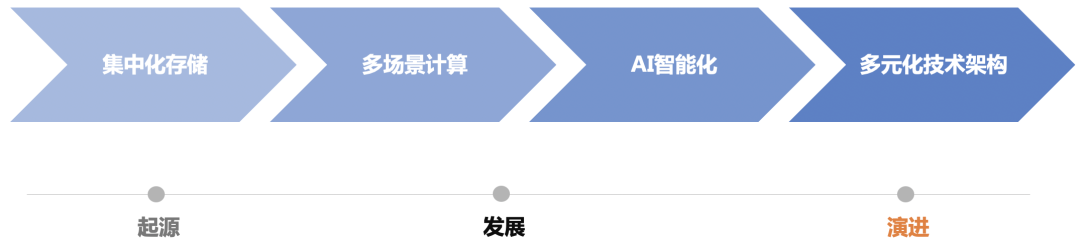
一、数据湖的前世今生
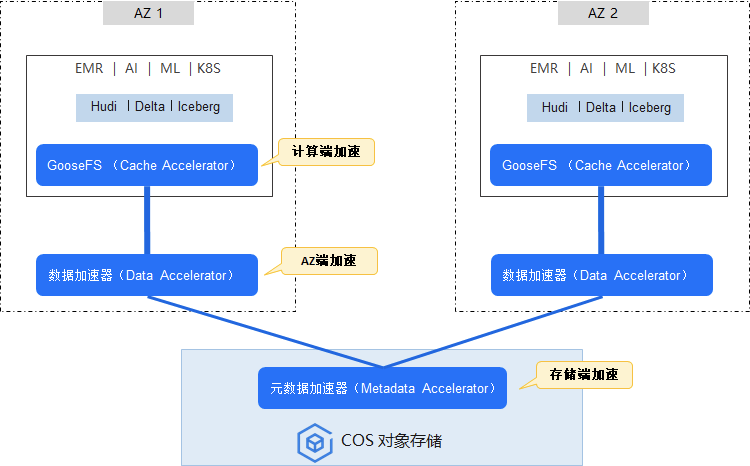
二、腾讯云原生数据湖架构


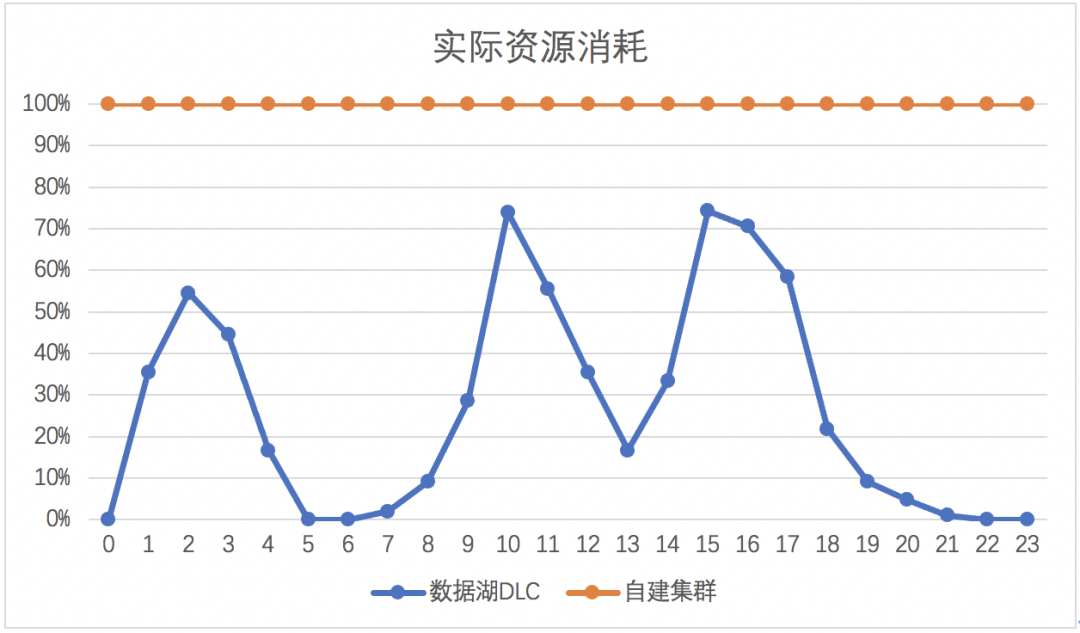
三、云原生数据湖计算
如何基于云服务兼容特性屏蔽底层架构,降低计算成本? 如何加速和优化存储侧的性能瓶颈?


四、腾讯云原生数据湖技术未来展望

评论
 下载APP
下载APP引言
你是否遇到过,一个简单的业务统计需求却让数据工程师们抓耳挠腮?
你是否遇到过,业务峰值周期明显,要么资源大量闲置, 要么线上疯狂告警?
你是否遇到过,大数据集群运维复杂,需要投入大量技术工程师?
一、数据湖的前世今生
二、腾讯云原生数据湖架构
三、云原生数据湖计算
如何加速和优化存储侧的性能瓶颈?
四、腾讯云原生数据湖技术未来展望