
推荐几个精致的字符串处理库
处理字符串可能是一项繁琐的工作,因为有许多不同的用例。
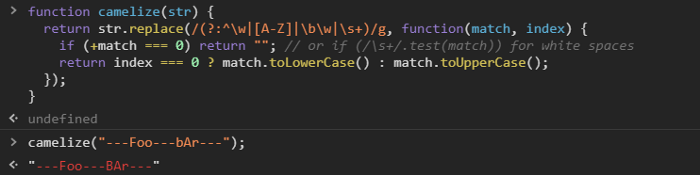
例如,一个简单的任务,如将字符串转换为骆驼字母,可能需要几行代码来实现最终目标,比如我们举个例子:
function camelize(str) {
return str.replace(/(?:^\w|[A-Z]|\b\w|\s+)/g, function(match, index) {
if (+match === 0) return ""; // or if (/\s+/.test(match)) for white spaces
return index === 0 ? match.toLowerCase() : match.toUpperCase();
});
}
上面的代码片段是StackOverflow中投票最多的答案。但这也不能解决字符串为---Foo---bAr---的情况。
这就是字符串操作库的用武之地。
字符串操作库使实现复杂的字符串操作变得很容易,而且还考虑到一个给定问题的所有可能的使用情况。
这对你来说很有帮助,因为你只需要调用一个方法就能得到一个有效的解决方案。
让我们来看看几个JavaScript的字符串操作库:
String.js Voca Stringz Underscore String Anchorme
一、String.js
该库是一个轻量级的(大小小于 5 kb的)JavaScript库,为浏览器或Node.js提供额外的String方法。
安装
npm i string
值得注意的方法
between(left, right)
在左右两个字符串之间提取一个字符串。当试图获得HTML中两个标签之间的元素时,可以使用这个方法。
var S = require('string');
S('<a>This is a link</a>').between('<a>', '</a>').s
// 'This is a link'
camelize()
移除任何下划线或破折号,并将字符串转换为骆驼的大小写。
这个函数可以用来解决本文开头提到的问题。
var S = require('string');
S('---Foo---bAr---').camelize().s;
//'fooBar'
humanize()
将输入的内容转化为对人友好的形式。
这个功能从头开始实现,肯定需要相当多的代码行。
var S = require('string');
S(' capitalize dash-CamelCase_underscore trim ').humanize().s
//'Capitalize dash camel case underscore trim'
stripPunctuation()
剥离给定字符串中所有的标点符号。
如果你从头开始实现这个功能,很有可能会漏掉一个标点符号。
var S = require('string');
S('My, st[ring] *full* of %punct)').stripPunctuation().s;
//My string full of punct
更多的方法,参考下面的链接:
https://github.com/jprichardson/string.js
二、Voca
Voca是一个JavaScript字符串操作库。Voca库中提供了改变大小写、修剪、填充、审美化、截断、转义和其他有用的字符串操作方法。
为了减少应用程序的构建,模块化设计允许你加载完整的库或特定功能。该库已经过完整的测试,有完善的文档,并提供长期支持。
安装
npm i voca
值得注意的方法
Camel Case(String data)
将数据转换为骆驼的大小写。
var v = require('voca');
v.camelCase('foo Bar');
// => 'fooBar'
v.camelCase('FooBar');
// => 'fooBar'
v.camelCase('---Foo---bAr---');
// => 'fooBar'
Latinise(String data)
通过删除变音符对数据进行拉丁化处理。
var v = require('voca');
v.latinise('cafe\u0301'); // or 'café'
// => 'cafe'
v.latinise('août décembre');
// => 'aout decembre'
v.latinise('как прекрасен этот мир');
// => 'kak prekrasen etot mir'
isAlphaDigit(String data)
检查数据是否只包含字母和数字字符。(字母数字)
var v = require('voca');
v.isAlphaDigit('year2020');
// => true
v.isAlphaDigit('1448');
// => true
v.isAlphaDigit('40-20');
// => false
CountWords(String data)
计算数据中的字数:
var v = require('voca');
v.countWords('gravity can cross dimensions');
// => 4
v.countWords('GravityCanCrossDimensions');
// => 4
v.countWords('Gravity - can cross dimensions!');
// => 4
更多的方法,参考下面的链接:
https://vocajs.com/#
三、Anchorme.js
这是一个微小的、快速的Javascript库,有助于检测文本中的链接URLs or Emails,并将其转换为可点击的HTML锚链接。
它有以下几个优点:
它是高度敏感的,误报率最低。 它根据完整的IANA列表验证URL和Emails。 验证端口号(如果存在)。 验证IP八位数(如果存在)。 对非拉丁字母的URLs起作用。
安装
npm i voca
使用方法
import anchorme from "anchorme";
//or
//var anchorme = require("anchorme").default;
const input = "some text with a link.com";
const resultA = anchorme(input);
//some text with a <a href="http://link.com">link.com</a>
你可以传入额外的扩展来进一步定制该功能。
四、Underscore String
Underscore是JavaScript的字符串操作扩展,它为你提供了几个有用的功能:capitalize、clean、count、escapeHTML、unescapeHTML、insert、startsWith、 endsWith、titleize、truncate、trim等等。
安装
npm install underscore.string
值得注意的方法
numberFormat(number)
将数字格式化为具有小数和顺序分隔的字符串。
var _ = require("underscore.string");
_.numberFormat(1000, 3)
=> "1,000.000"
_.numberFormat(123456789.123, 5, '.', ',');
=> "123,456,789.12300"
chop(string, step)
通过删除变音符对数据进行拉丁化处理。
var v = require('voca');
v.latinise('cafe\u0301'); // or 'café'
// => 'cafe'
v.latinise('août décembre');
// => 'aout decembre'
v.latinise('как прекрасен этот мир');
// => 'kak prekrasen etot mir'
isAlphaDigit(String data)
将给定的字符串切成碎片
var _ = require("underscore.string");
_.chop('whitespace', 3);
=> ['whi','tes','pac','e']
更多的方法,参考下面的链接:
http://gabceb.github.io/underscore.string.site/#chop
五、Stringz
这个库的主要亮点是它能识别unicode。如果你运行下面这段代码,输出将是2。
"🤔".length
// -> 2
至于为什么长度是2,可以在这里阅读更多关于JavaScript unicode代码问题的信息。
https://mathiasbynens.be/notes/javascript-unicode
安装
npm install stringz
值得注意的方法
limit(string, limit, padString, padPosition)
将字符串限制在一个给定的宽度。
const stringz = require('stringz');
// Truncate:
stringz.limit('Life’s like a box of chocolates.', 20);
// "Life's like a box of"
// Pad:
stringz.limit('Everybody loves emojis!', 26, '💩');
// "Everybody loves emojis!💩💩💩"
stringz.limit('What are you looking at?', 30, '+', 'left');
// "++++++What are you looking at?"
// Unicode Aware:
stringz.limit('🤔🤔🤔', 2);
// "🤔🤔"
stringz.limit('👍🏽👍🏽', 4, '👍🏽');
// "👍🏽👍🏽👍🏽👍🏽"
toArray(string)
将字符串转换为数组。
const stringz = require('stringz');
stringz.toArray('abc');
// ['a','b','c']
//Unicode aware
stringz.toArray('👍🏽🍆🌮');
// ['👍🏽', '🍆', '🌮']
更多的方法,参考下面的链接:
https://github.com/sallar/stringz
往期推荐