
我惊了!!!ThreadLocal 源码存在内存泄露的 Bug!!!

点击上方老周聊架构关注我
一、前言
写这篇文章的目的是因为现在网上很多关于 ThreadLocal 的文章,很大一部分都不太准确。
比如说:
ThreadLocal 内部有个 map,键为线程对象;
ThreadLocal 的数据结构是个数组;
还有说 ThreadLocal 存在内存泄露,但里面的 get、set 以及 remove 方法能防止 ThreadLocal 内存泄露问题。
都是不准确的哈,太误导人了。这里老周先来点开胃小菜,先说一下第一个问题。
1.1 ThreadLocal 的内部 ThreadLocalMap,键为 ThreadLocal。
那些说键为 Thread 对象的,它们不看源码的吗?


事实真的是这样吗?源码也要看仔细点吧,继续跟 createMap 方法,你会发现:

t.threadLocals 其实是 Thread 内部的 ThreadLocalMap,这里正在给 Thread 的 ThreadLocalMap 赋值呢,而且 ThreadLocalMap 的 key 是 this,也就是当前 ThreadLocal,而不是 Thread。
好了第一个错误我们搞清楚了,我们继续来搞清楚第二个错误。
1.2 ThreadLocal 的数据结构是个环形数组
说 ThreadLocal 的数据结构是个数组也是没有仔细看源码的,好多文章画的图说 ThreadLocal 的数据结构是数组,太误导人了。
这里老周给出正确的 ThreadLocal 的数据结构
1.2.1 ThreadLocal 的数据结构

ThreadLocalMap 维护了 Entry 环形数组,数组中元素 Entry 的逻辑上的 key 为某个 ThreadLocal 对象(实际上是指向该 ThreadLocal 对象的弱引用),value 为代码中该线程往该 ThreadLoacl 变量实际塞入的值。
1.2.2 ThreadLocal 类结构

1.2.3 Thread、ThreadLocal、ThreadLocalMap 的关系

1.3 ThreadLocal 里的 get、set 以及 remove 方法能保证不内存泄露吗?
这个问题是我们本文重点分析的问题,这里老周先说下结论。
get,set 两个方法都不能完全防止内存泄漏,还是每次用完 ThreadLocal 都勤奋的 remove 一下靠谱。
在详细分析这个问题之前,我们下面会来看下所需的前置知识。
二、内存泄露
2.1 什么是内存泄露?
首先你得知道什么叫内存泄露吧,不然后面分析会很吃力。
内存泄漏(Memory Leak)是指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
站在 Java 的角度来说,就是 JVM 创建的对象永远都无法访问到,但是 GC 又不能回收对象所占用的内存。少量的内存泄漏并不会出现什么严重问题,无非是浪费了一些内存资源罢了,但是随着时间的积累,内存泄漏的越来越多就会导致内存溢出,程序崩溃。
2.2 Java 四中引用类型
在 JDK1.2 之前,“引用”的概念过于狭隘,如果 Reference 类型的数据存储的是另外一块内存的起始地址,就称该 Reference 数据是某块地址、对象的引用,对象只有两种状态:被引用、未被引用。
这样的描述未免过于僵硬,对于这一类对象则无法描述:内存足够时暂不回收,内存吃紧时进行回收。例如:缓存数据。
在 JDK1.2 之后,Java 对引用的概念做了一些扩充,将引用分为四种,由强到弱依次为:
强引用
在 Java 中最常见的就是强引用,把一个对象赋给一个引用变量,这个引用变量就是一个强引用。当一个对象被强引用变量引用时,它处于可达状态,它是不可能被垃圾回收机制回收的,即使该对象以后永远都不会被用到 JVM 也不会回收。因此强引用是造成 Java 内存泄漏的主要原因之一。
软引用
软引用需要用 SoftReference 类来实现,对于只有软引用的对象来说,当系统内存足够时它不会被回收,当系统内存空间不足时它会被回收。软引用通常用在对内存敏感的程序中。
弱引用
弱引用需要用 WeakReference 类来实现,它比软引用的生存期更短,对于只有弱引用的对象来说,只要垃圾回收机制一运行,不管 JVM 的内存空间是否足够,总会回收该对象占用的内存。
虚引用
虚引用需要 PhantomReference 类来实现,它不能单独使用,必须和引用队列联合使用。虚引用的主要作用是跟踪对象被垃圾回收的状态。
三、为什么 ThreadLocalMap 采用开放地址法来解决哈希冲突
JDK 中大多数的类都是采用了链地址法来解决 hash 冲突,为什么 ThreadLocalMap 采用开放地址法来解决哈希冲突呢?首先我们来看看这两种不同的方式:
3.1 链地址法
这种方法的基本思想是将所有哈希地址为 i 的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第 i 个单元中,因而查找、插入和删除主要在同义词链中进行。例如对于关键字集合{28, 93, 90, 3, 21, 11, 19, 31, 18},我们假如数组的长度为 8,那我们用 8 为除数,进行除留余数法:

3.2 开放地址法
这种方法的基本思想是一旦发生了冲突,就去寻找下一个空的散列地址(这非常重要,源码都是根据这个特性,必须理解这里才能往下走),只要散列表足够大,空的散列地址总能找到,并将记录存入。
我们还是以上面的关键字集合 {28, 93, 90, 3, 21, 11, 19, 31, 18} 来演示,我们用散列函数 f(key) = key mod 16。当计算前 S 个数 {28, 93, 90, 3, 21, 11} 时,都是没有冲突的散列地址,直接存入(蓝色下标代表已存入了数据,空白的下标可以存放数据):

当计算到集合中的 19 的时候,发现 f(19) = 3,此时就与 3 所在的位置冲突。
于是我们应用上面的公式f(19) = (f(19)+1) mod 10 = 4。于是将 19 存入下标为 4 的位置。这其实就是房子被人买了于是买下一间的做法,以此类推。

3.3 链地址法和开放地址法的优缺点
3.3.1 链地址法
优点:
处理冲突简单,且无堆积现象,平均查找长度短;
链表中的结点是动态申请的,适合构造表不能确定长度的情况;
相对而言,拉链法的指针域可以忽略不计,因此较开放地址法更加节省空间;
插入结点应该在链首,删除结点比较方便,只需调整指针而不需要对其他冲突元素作调整。
缺点:
指针占用较大空间时,会造成空间浪费。
3.3.2 开放地址法
优点:
当节点规模较少,或者装载因子较少的时候,使用开发寻址较为节省空间,如果将链式表的指针用于扩大散列表的规模时,可使得装载因子变小从而减少了开放寻址中的冲突,从而提高平均查找效率。
缺点:
容易产生堆积问题;
不适于大规模的数据存储;
结点规模很大时会浪费很多空间;
散列函数的设计对冲突会有很大的影响;
插入时可能会出现多次冲突的现象,删除的元素是多个冲突元素中的一个,需要对后面的元素作处理,实现较复杂。
3.4 ThreadLocalMap 采用开放地址法原因
ThreadLocal 中看到一个属性 HASH_INCREMENT = 0x61c88647 ,0x61c88647 是一个神奇的数字,让哈希码能均匀的分布在 2 的 N 次方的数组里, 即 Entry[] table,关于这个神奇的数字网上有很多解析,这里就不多说了。
ThreadLocal 往往存放的数据量不会特别大(而且key 是弱引用又会被垃圾回收,及时让数据量更小),这个时候开放地址法简单的结构会显得更省空间,同时数组的查询效率也是非常高,加上第一点的保障,冲突概率也低。
四、ThreadLocal 内存泄露
上面我们已经说了内存泄露的概念,这里我还是再说下 ThreadLocal 的内存泄露是怎么回事。
根据 ThreadLocal 的源码,可以画出一些对象之间的引用关系图,实线表示强引用,虚线表示弱引用:
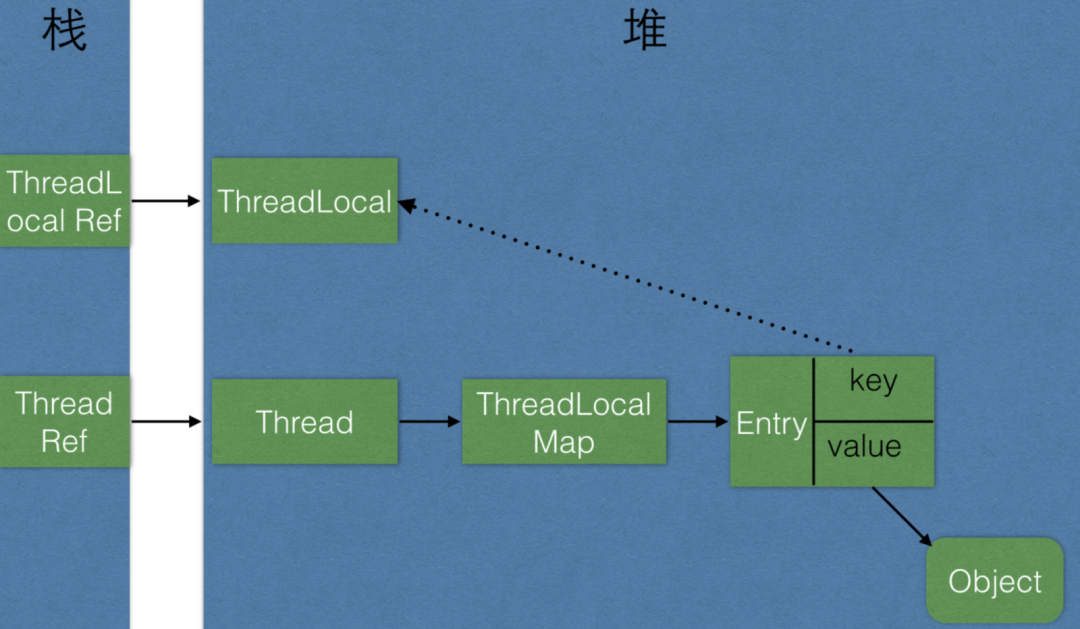
Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value
永远无法回收,造成内存泄露。
那 Java 源码团队就没有啥解决方案吗?当然有,前面已经说过,由于 key 是弱引用,因此 ThreadLocal 可以通过 key.get()==null 来判断 key 是否已经被回收,如果 key 被回收,就说明当前 Entry 是一个废弃的过期节点,ThreadLocal 会自发的将其清理掉。
ThreadLocal 会在以下过程中清理过期节点:
调用 set() 方法时,采样清理、全量清理,扩容时还会继续检查。
调用 get() 方法,没有直接命中,向后环形查找。
调用 remove() 时,除了清理当前 Entry,还会向后继续清理。
那么正好回到我们前言的第三个问题:
还有说 ThreadLocal 存在内存泄露,但里面的 get、set 以及 remove 方法能防止 ThreadLocal 内存泄露问题。
那么老周的问题是:get、set 以及 remove 方法真的能防止 ThreadLocal 内存泄露吗?
这里你自己可以翻看源码思考下再来看我接下写的,这样有思考收获才更大。
这里分界线假装你思考完了哈,那我们就来讲本文的最重要的一部分了。
事先约定:

4.1 remove 方法能否防止内存泄露?
一开始都是有效的 entry,并且每个 entry 的 key 通过散列算法后算出的位置都是自己所在的位置(都在自己的位置上的话之后的线性清扫中不会造成搬移,因为 ThreadLocalMap 的散列表用的是开放地址法,所以 entry 可能因为 hash 冲突而不在自己位置上)
要达成下面的效果,就要一直没有失效的 entry 出现,并且一直实现插入,也就是一直执行 set 方法。
假设 entry 循环数组有 16 个槽位


如果执行一次 remove,把图中的某个 entry 无效化。

然后我们来看下 ThreadLocal#remove 方法的实现:
因为每个 entry 都在自己的位置上,所以下图的 if (e.get() == key) 会在第一个循环就成立,也就是 remove 会执行 e.clear() 来把弱引用置空,无效化,并且执行一次线性清扫后返回。

我们跟着 expungeStaleEntry 方法进去看:



向后遍历整个数组,直到遇到空槽为止,并且第一种情况
(k == null) 为真的情况下,会把无效 entry 置空,防止内存泄漏。其实就是向后扫描,遇到无效的就顺带干掉,直到遇到空槽为止。
接着再看第二种情况 (k != null)的分支的(h != i)场景:
也就是说遇到的 entry 是有效的,但是不是在自己原本的位置上,而是被 hash 冲突到其它位置上了,则把它们搬去离原本位置最近的后边空槽上。这样在 get 的时候,会最快找到这个 entry,减少开放地址法遍历数组的时间。

小结:
执行 remove 方法后,会执行
e.clear()来把弱引用置空,无效化。并且执行一次线性清扫后返回。
线性清扫把要清扫的位置给置空了,然后继续往后遍历,直到遇到空槽位为止,如果遇到无效entry, 就把无效 entry 的槽位置空,防止内存泄漏。
第二种情况可能遇到的 entry 是有效的,但是不是在自己原本的位置上,而是被 hash 冲突到其它位置上了,则把它们搬去离原本位置最近的后边空槽上。这样在 get 的时候,会最快找到这个 entry,减少开放地址法遍历数组的时间。
结论:
remove 方法能防止内存泄露
4.2 set 方法能否防止内存泄露?
看完 remove 方法后,我们再来看下 set 方法能否防止内存泄漏。
因为每个 entry 都在自己的位置上,并且没有遇到无效的 entry,最终的效果只是把 remove 的位置置为空槽。所以上面 remove 方法得到的效果图:
同理,假设再经历 4 次 remove,可以得出下面的效果图:

如果此时,这时候正好有两个 entry 的 key,也即是 ThreadLocal 的所有强应用被置空,于是这两个 entry 无效。

如果之后只执行 set 方法,是否会内存泄漏呢?是否任意调用 set 之后就保证内存不会泄漏了呢?
带着这两个问题我们来看下 ThreadLocal#set 方法

4.2.1 代码块①
遇到 key 和我们当前调用 set 的 ThreadLocal 相等的 entry,则只用直接把 entry 的 value 设置一下就好了,和 HashMap 的 put(key, A); put(key, B); 中 A 被替换成 B 同理。
4.2.2 代码块②
遇到无效 entry,是我们重点关注的地方。
4.2.3 代码块③
遇到空槽,直接插入,并且尝试指数清扫,如果指数清扫不成功并且当前 entry 的使用槽数到达阈值则重散列。
我们重点来关注代码块②
这里方便演示,我假设下标 9 为有效 entry,也正好是 set 方法的位置。

我们接着上面的 代码块② 分析,要调用到 replaceStaleEntry 方法。
下标 9 为有效 entry 的话,我们在 remove 方法中说过,set 不是在自己原本的位置上,而是被 hash 冲突到其它位置上了,则把它们搬去离原本位置最近的后边空槽上。即下标 12 为 hash 冲突的有效 entry,我们标为绿色下标 12。


第一个 for 循环中,开始向前找,找到最靠前的无效 entry,直到遇到空槽为止,当然可能会绕循环数组一圈绕回来,但是因为使用的槽数如果到达阈值,就会 rehash,不可能所有槽都用完,所以会遇到空槽的。
如下图:

因为没有找到,所以 slotToExpunge = staleSlot,也就是上图红色下标 10 位置的 entry。
接着往下看:

我们重点关注
k == key 的情况,也就是 i 遍历到图中绿色下标12槽位的情况。这种情况下会执行一次线性清扫,然后执行对数清扫,最后返回。
如下图:

从 slotToExpunge 位置开始,先进行一轮线性清扫:
和之前一样,一上来先把待清扫槽位置空(红色下标 12 无效 entry 的位置),之后遇到红色下标 12 后面那个空位(也就是黑色下标 14 的空位),所以停下来。
线性清扫返回空位的下标做为参数传给对数清扫。

对数清扫:清扫次数 = log2(N) ,N 是循环数组大小,本例中是 16,所以要清扫 4 次,每次清扫是通过调用线性清扫实现的。
这里你可能会问了,为啥这里是对数清扫了?而且清扫次数为啥是 log2(N)啊?
别着急,源码是个好东西,源码写的很清楚了。

老周你不要骗我,这里明明是循环数组的长度啊。

哈哈,没错,确实是循环数组的长度,作者想表达的是循环数组的长度是扫描控制的参数,具体的清扫参数是 log2(N)。等等,那清扫参数 log2(N)怎么来的呢?不着急,源码往下看,看到 while 循环了吧,
while ( (n >>>= 1) != 0),没错就是这个得到清扫参数。我们例子的循环数组长度为 16,代入到里面去,无符号向右移动一位,直到等于 0 跳出循环。16->8->4->2->1,共循环 4 次,并且只有遇到无效entry时才执行线性清扫。注:老周这里为了严谨,还是要再提一嘴。这里的 n 是循环数组的长度,只是 replaceStaleEntry 方法调用时,但当从插入调用时,这个参数 n 是元素的数量。

显然,4 次扫描中都没有无效 entry。

这里 removed 返回 false,接着 cleanSomeSlots 返回,一直返回到 replaceStaleEntry,并且继续返回,最后从 set 方法返回。

结果显而易见,红色下标 5 位置的无效 entry 未被清除,导致内存泄露。

结论:
set 方法的清扫程度不够深,set 方法并不能防止内存泄漏。
4.3 get 方法能否防止内存泄露?

直接跟进 getEntry 方法:

get 方法相对来说简单点,在原本属于当前 key 的位置上找不到当前 key 的 entry 的话,就会根据开放地址法线性遍历找到 key 对应的 entry。
k == null 的话,执行线性清扫 expungeStaleEntry 方法,顺便把路上无效的 entry 清除掉。
还是看我们上面的例子:



根据前面说的遇到的 entry 是有效的,但是不是在自己原本的位置上,而是被 hash 冲突到其它位置上了,则把它们搬去离原本位置最近的后边空槽上。这样在 get 的时候,会最快找到这个 entry,减少开放地址法遍历数组的时间。所以蓝色下标 12 的位置会搬移到 黑色下标 10 号位置。
搬移后的图:


因为是直接取线性清扫开始的位置,所以 k = key 是 true,所以返回绿色 10 号位置的 entry,查找成功。

结果显而易见,红色下标 5 位置的无效 entry 未被清除,导致内存泄露。
结论:
get 方法的清扫程度不够深,get 方法并不能防止内存泄漏。
五、总结
本文主要以市面上关于 ThreadLocal 都不太准确的文章进行了一番论证并给出正确的结论。特别重点介绍了 ThreadLocal 中 ThreadLocalMap 的大致实现原理以及 ThreadLocal 内存泄露的问题。
ThreadLocalMap 的 Entry 的 key 是弱引用,如果外部没有强引用指向 key,key 就会被回收,而 value 由于 Entry 强引用指向了它,导致无法被回收,但是 value 又无法被访问,因此发生内存泄漏。
关于内存泄漏,我们重点从源码层面分析了 get、set、remove 方法,并图文并茂的演示了 get、set 方法不能防止内存泄漏,而 remove 方法能防止内存泄漏的结论。
所以,开发者应该尽量在使用完毕后及时调用 remove 删除节点,这里老周建议用 Spring 的 AOP 思想对 remove 方法进行切面,省的使用完毕后忘记调用 remove 方法清除。
欢迎大家关注我的公众号【老周聊架构】,Java后端主流技术栈的原理、源码分析、架构以及各种互联网高并发、高性能、高可用的解决方案。
喜欢的话,点赞、再看、分享三连。

点个在看你最好看