
猪八戒网 CI/CD 最佳实践之路
Nodejs:负责前端
Java:负责后端
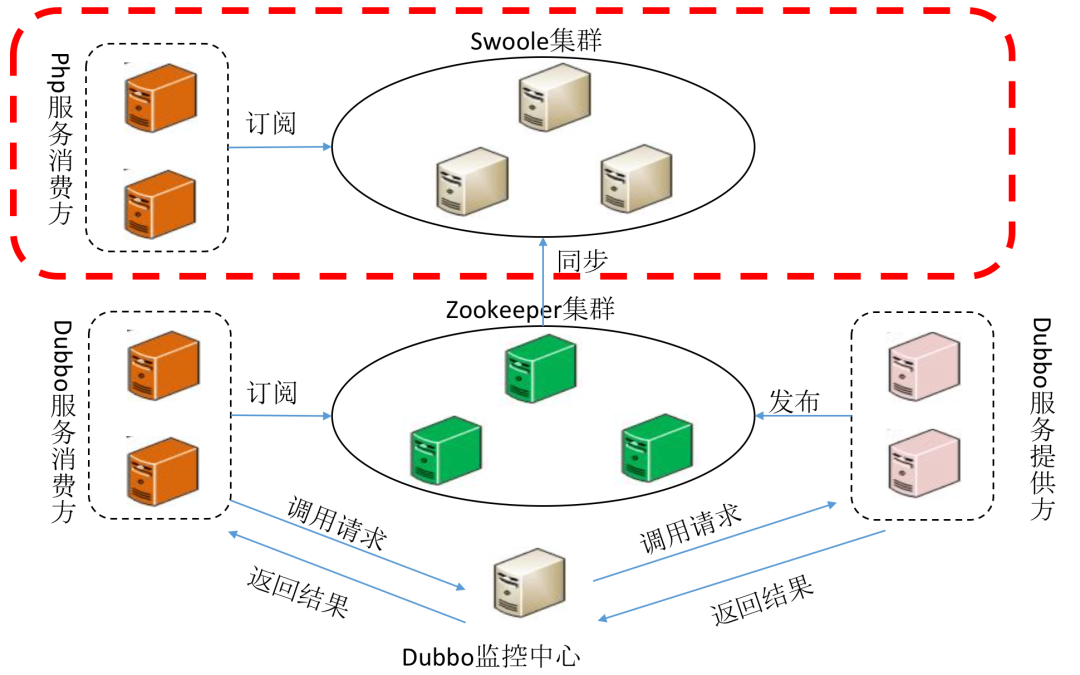
PHP:负责老项目维护
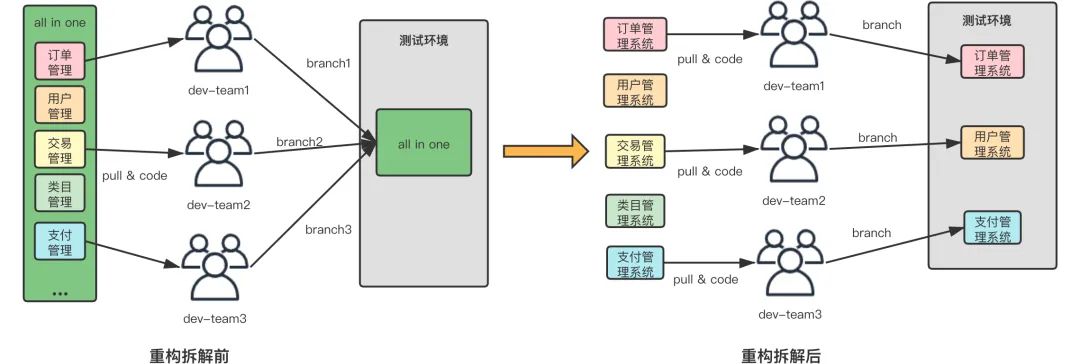
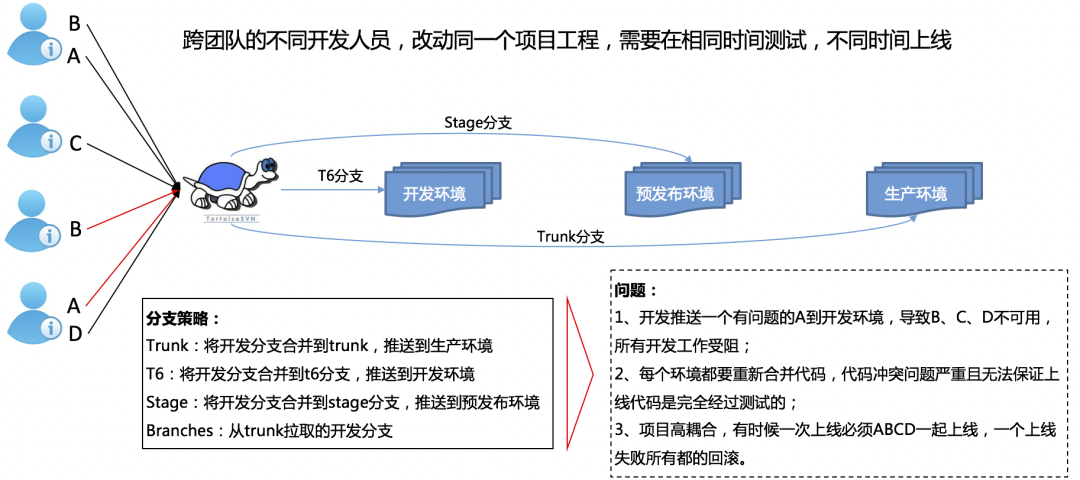
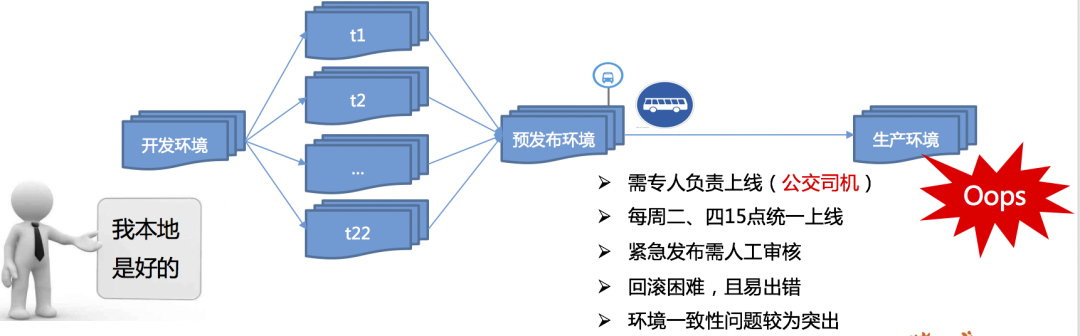
公交车模式(本图由DevOps团队提供)
项目耦合度太高,容易导致合并冲突,环境冲突等。
集成过程中未对代码进行审查,错误代码发布到测试环境后,会影响依赖方的测试。
发布受限制,必须在专门时间由专人发布。
发布异常时,回滚工作异常艰难。


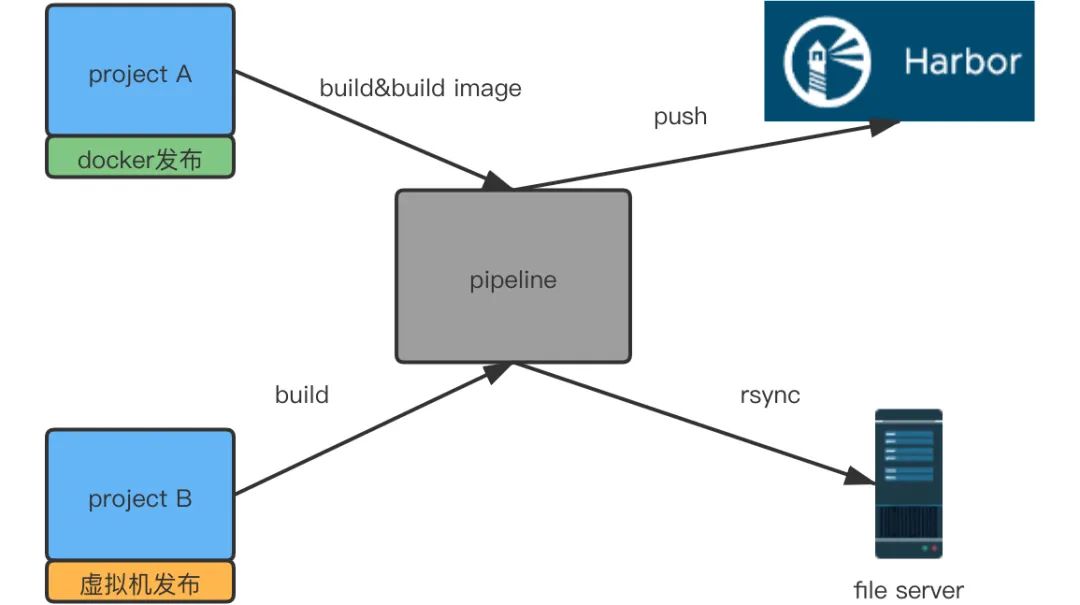
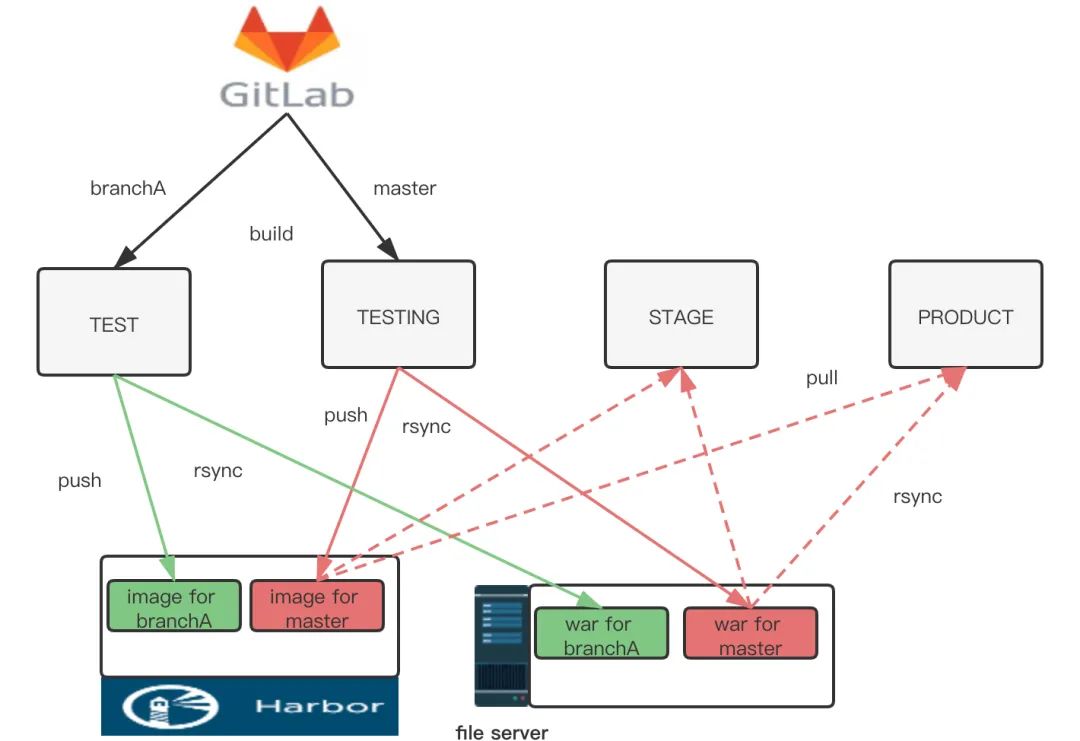
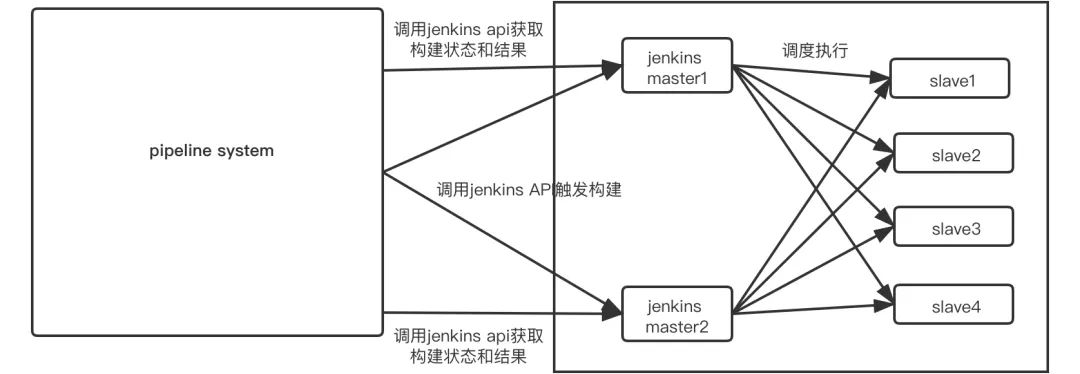
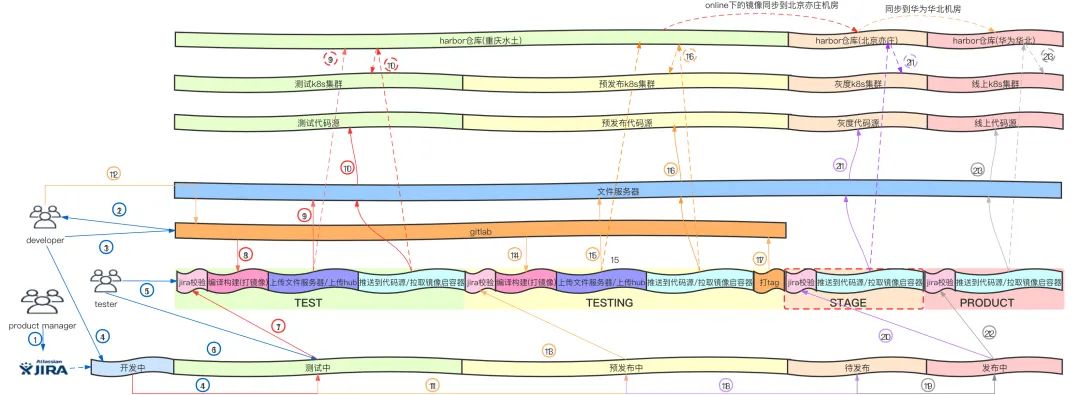
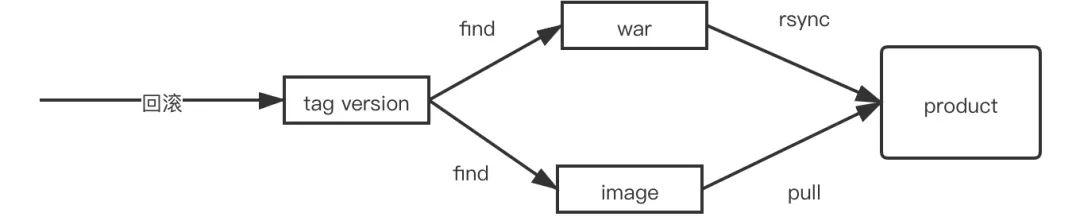
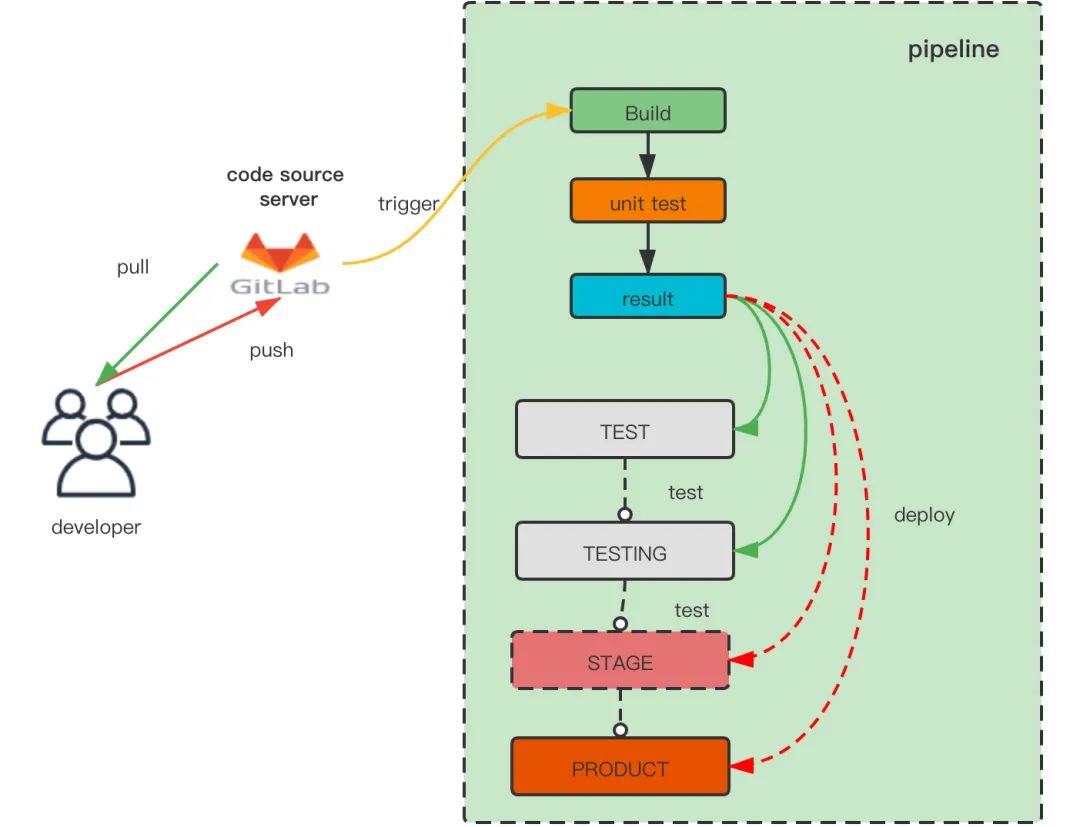
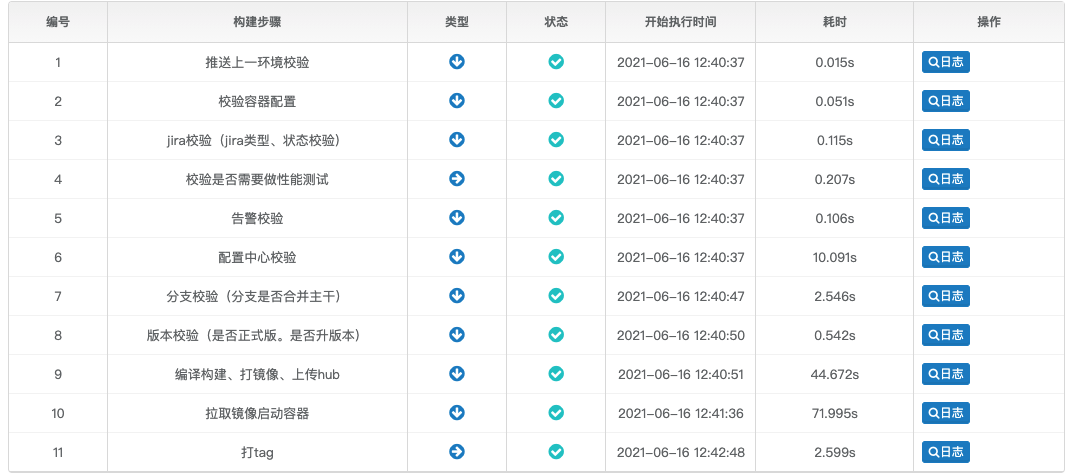
通过用Jira需求上线流程和流水线做整合,以及多种推送前的校验,保证了上线过程的每一步都是可靠的
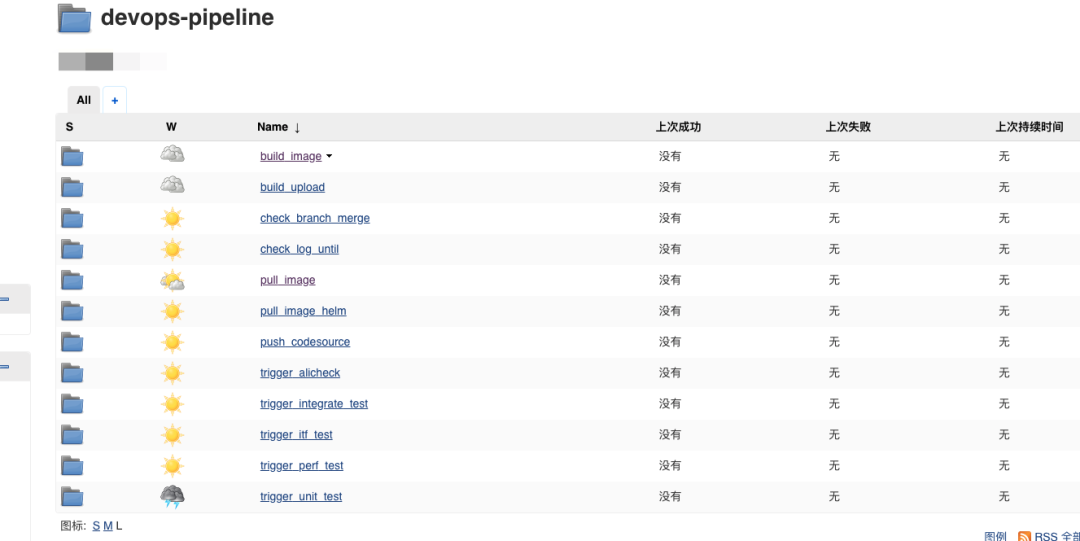
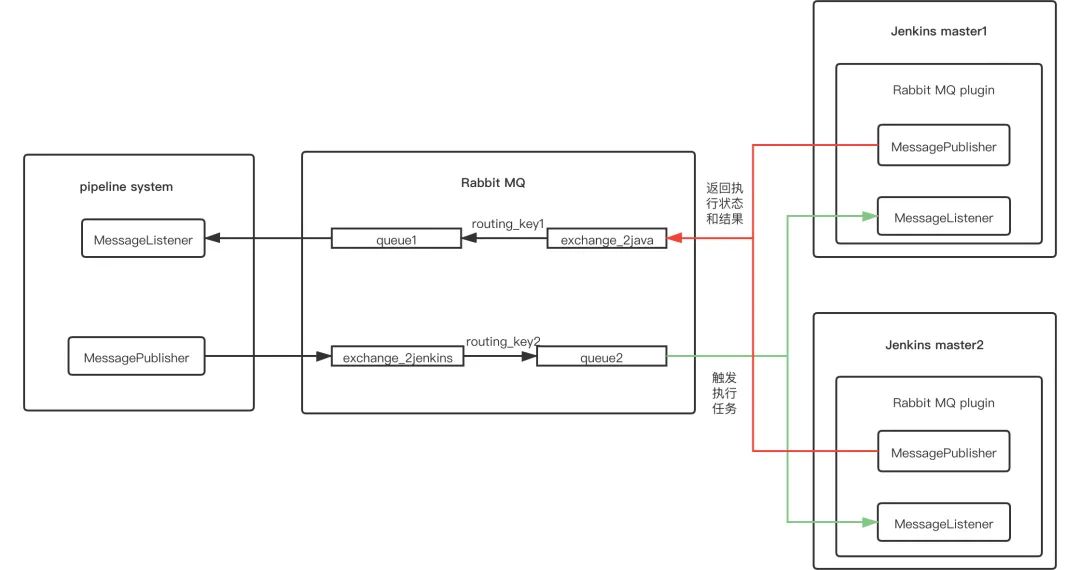
每一个环境的集成和发布都是自动化的
因为过程变得可靠且自动化,使得将发布过程开放给研发团队成为了可能,达到了随时自主上线的目的。
不够灵活,如在推送测试环境时,整个过程执行的步骤是固定的的,即第一步做什么,第二步做什么都是固定的,不能新增也不能删减,如某些团队需要进行单元测试,有的不需要,但流水线都会去执行单元测试,通常情况下单元测试过程是一个花费时间比较长的过程,这对于需要频繁更改和部署的业务是不友好的。
推送成功率不高,因为整个过程是串联的,某一个环节出现错误,将会导致本次推送失败,而某些环节本不应该影响构建结果的,最后导致了构建失败。
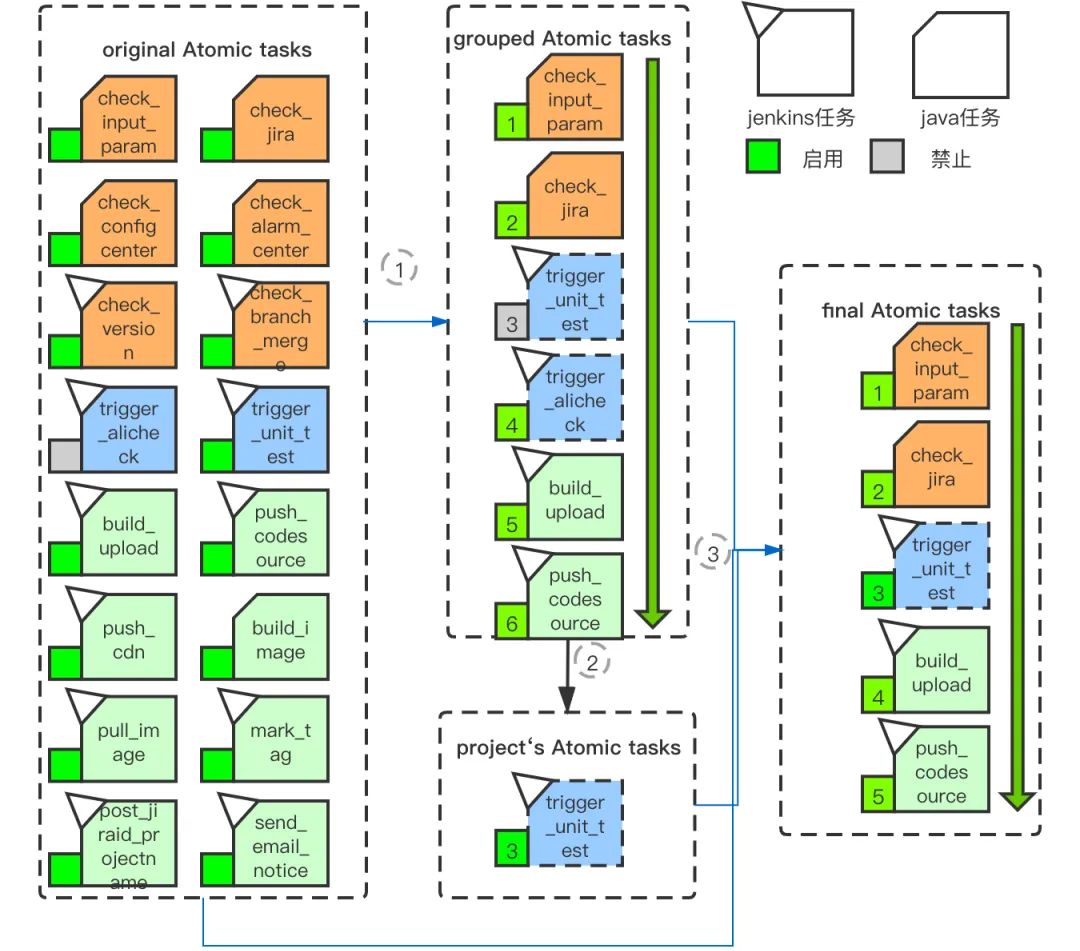





CI/CD应该是以提高研发效率为目标的实践,一切脱离这个目标只是为了迎合什么口号而做什么的是都是耍牛氓。而实现这个目标是一个比较漫长的过程,一开始会比较容易,后面就会越来越难,这需要不断思考和学习的过程。
CI/CD应该是紧贴业务的,因为业务的不同,要求的技术架构也会有所不同,随之而来,要求的交付方式也会有所不同。
CI/CD应该是以人为本的,我们应该尽可能地将一切繁琐的过程交给程序去执行,而人只需要“坐享其成”或者做少量的决策即可。
- END -
推荐阅读 Kubernetes 企业容器云平台运维实战 Jenkins Pipeline 流水线部署 Kubernetes 应用 快、狠、准!系统有效的排查运维类故障 OpenStack 与 Kubernetes 的共存 Nginx 常用配置清单 最强整理!常用正则表达式速查手册 运维的工作边界,这次真的搞明白了! 七年老运维实战中的 Shell 开发经验总结 面试数十家Linux运维工程师,总结了这些面试题(含答案) 快速入门 Ansible 自动化运维工具 | 16张图 12年资深运维老司机的成长感悟
点亮,服务器三年不宕机


评论