
当UNet遇见ResNet会发生什么?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

这篇文章主要以几篇经典的分割论文为切入点,浅谈一下当Unet遇见ResNet会发生什么?
首先回顾一下UNet,UNet的结构如下图所示:
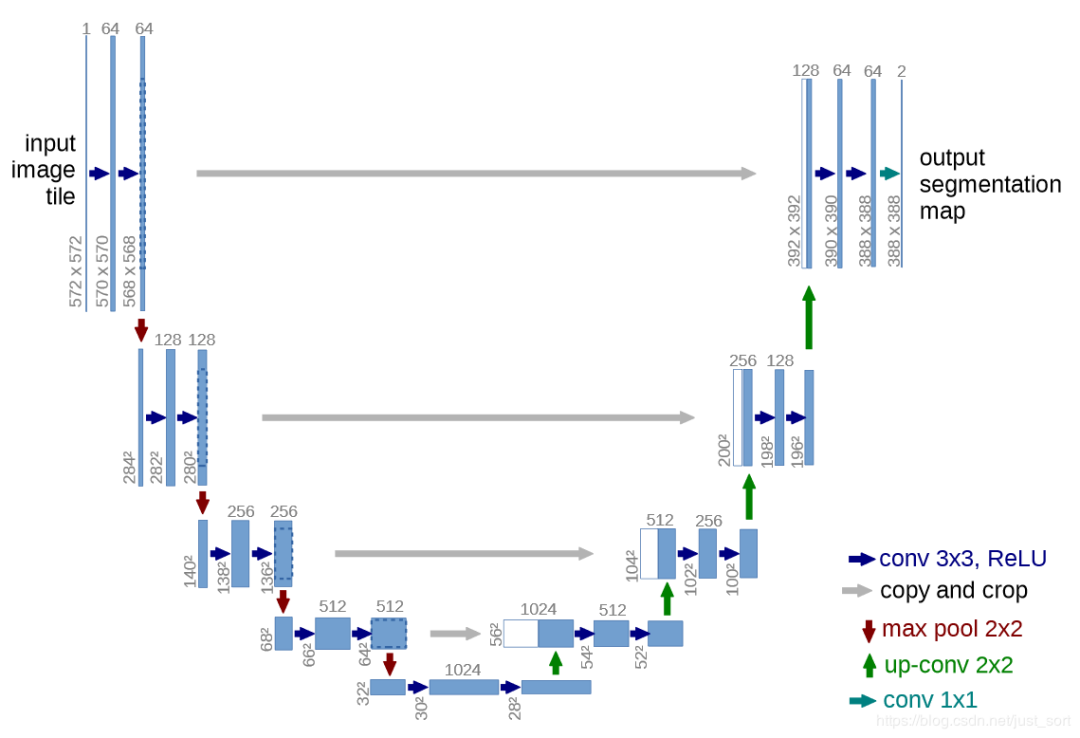
「从UNet的网络结构我们会发现两个最主要的特点,一个是它的U型结构,一个是它的跳层连接。」 其中UNet的编码器一共有4次下采样来获取高级语义信息,解码器自然对应了4次上采样来进行分辨率恢复,为了减少下采样过程带来的空间信息损失跳层连接被引入了,通过Concat的方式使得上采样恢复的特征图中包含更多low-level的语义信息,使得结果的精细程度更好。
使用转置卷积的UNet参数量是31M左右,如果对其channel进行缩小例如缩小两倍,参数量可以变为7.75M左右,缩小4倍变成2M左右,可以说是非常的轻量级了。UNet不仅仅在医学分割中被大量应用,也在工业界发挥了很大的作用
3. ResNet
再来简单回顾一下ResNet。
在ResNet之前普遍认为网络的深度越深,模型的表现就更好,因为CNN越深越能提取到更高级的语义信息。但论文的实验发现,通过和浅层网络一样的方式来构建深层网络,结果性能反而下降了,这是因为网络越深越难训练。实验如Figure1所示:
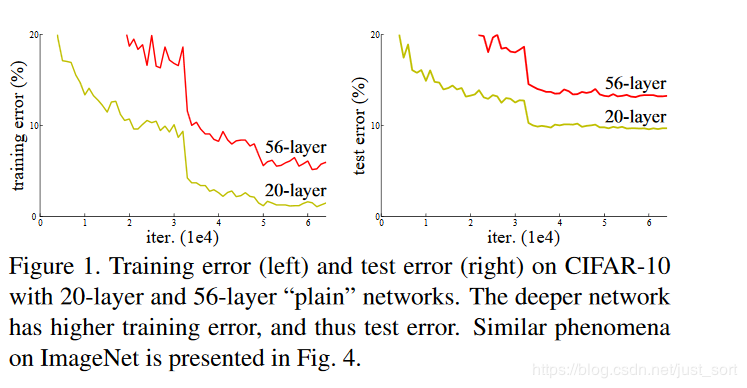
因此网络的深度不能随意的加深,前面介绍的GoogLeNet和VGG16/19均在加深深度这件事情上动用了大量的技巧。那么到底什么是残差呢?
首先,浅层网络都是希望学习到一个恒等映射函数,其中指的是用这个特征/函数来代表原始的的信息,但随着网络的加深这个恒等映射变得越来越难以拟合。即是用BN这种技巧存在,在深度足够大的时候网络也会难以学习这个恒等映射关系。因此ResNet提出将网络设计为,然后就可以转换为学习一个残差函数,只要残差为,就构成了一个恒等映射,并且相对于拟合恒等映射关系,拟合残差更容易。残差结构具体如Figure2所示,identity mapping表示的就是恒等映射,即是将浅层网络的特征复制来和残差构成新的特征。其中恒等映射后面也被叫作跳跃连接(skip connrection)或者短路连接(shortcut connection),这一说法一直保持到今天。同时我们可以看到一种极端的情况是残差映射为,残差模块就只剩下,相当于什么也不做,这至少不会带来精度损失,这个结构还是比较精巧的。

为什么残差结构是有效的呢?这是因为引入残差之后的特征映射对输出的变化更加敏感,也即是说梯度更加,更容易训练。从图2可以推导一下残差结构的梯度计算公式,假设从浅层到深层的学习特征,其中就是带权重的卷积之后的结果,我们可以反向求出损失函数对的提取,其中代表损失函数在最高层的梯度,小括号中的表示残差连接可以无损的传播梯度,而另外一项残差的梯度则需要经过带有可学习参数的卷积层。另外残差梯度不会巧合到全部为,而且就算它非常小也还有这一项存在,因此梯度会稳定的回传,不用担心梯度消失。同时因为残差一般会比较小,残差学习需要学习的内容少,学习难度也变小,学习就更容易。
4. 当UNet初见ResNet
我们知道UNet做下采样的BackNone是普通的CBR模块(Conv+BN+ReLU)堆叠的,一个自然的想法就是如果将学习更强的ResNet当作UNet的BackBone效果是否会更好呢?
CVPR 2017的LinkNet给出了答案。LinkNet的网络结构如下所示:
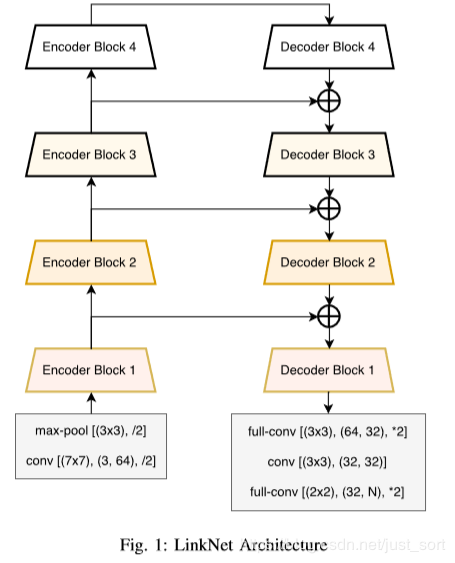 其中,
其中,conv 代表卷积,full-conv 代表全卷积,/2代表下采样的步长是2,*2代表上采样的因子是2。在卷积层之后添加 BN,后加 ReLU。左半部分表示编码,右半部分表示解码。编码块基于ResNet18。编解码模块如下所示。
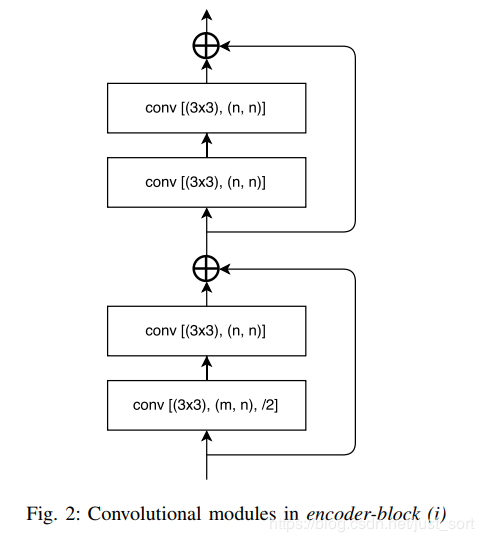
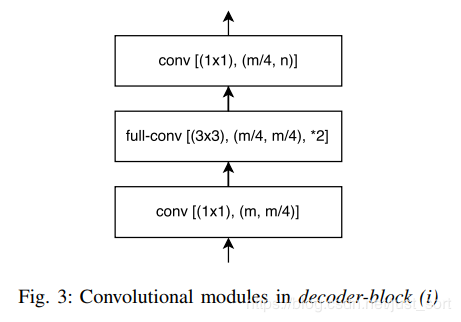
这项工作的主要贡献是在原始的UNet中引入了残差连接,并直接将编码器与解码器连接来提高准确率,一定程度上减少了处理时间。通过这种方式,保留编码部分中不同层丢失的信息,同时,在进行重新学习丢失的信息时并未增加额外的参数与操作。在Cittycapes和CamVID数据集上的实验结果证明残差连接的引入(LinkNet without bypass)使得mIOU获得了提升。
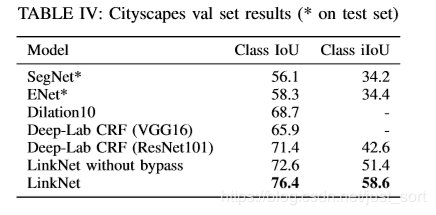
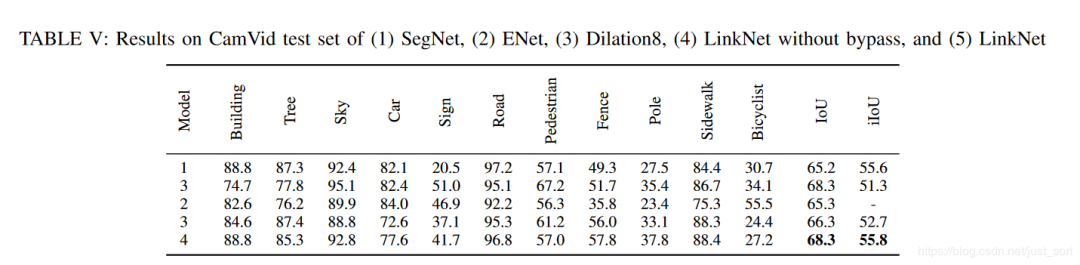
这篇论文的主要提升技巧在于它的bypass技巧,但我们也可以看到ResNet也进一步对网络的效果带来了改善,所以至少说明ResNet是可以当成BackBone应用在UNet的,这样结果至少不会差。
5. 当UNet再见ResNet
CVPR 2018北邮在DeepGlobe Road Extraction Challenge全球卫星图像道路提取)比赛中勇夺冠军,他们提出了一个新网络名为D-LinkNet,论文链接以及代码/PPT见附录。
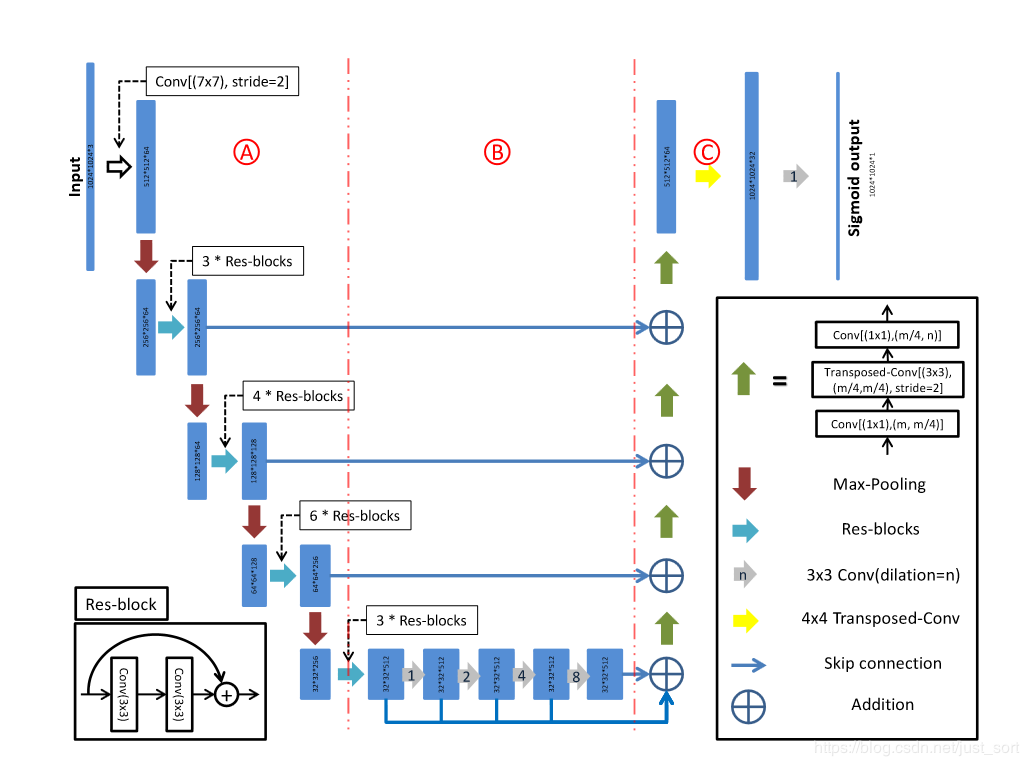
D-LinkNet使用LinkNet作为基本骨架,使用在ImageNet数据集上与训练好的ResNet作为网络的encoder,并在中心部分添加带有shortcut的dilated-convolution层,使得整个网络识别能力更强、接收域更大、融合多尺度信息。网络中心部分展开示意图如下:

这篇论文和ResNet的关系实际上和LinkNet表达出的意思一致,也即是将其应用在BackBone部分增强特征表达能力。
这篇文章其实是比上两篇文章早的,但我想放到最后这个位置来谈一下,这篇文章是DLMIA 2016的文章,名为:「The Importance of Skip Connections in Biomedical Image Segmentation」 。这一网络结构如下图所示,对图的解释来自akkaze-郑安坤的文章(https://zhuanlan.zhihu.com/p/100440276):

(a) 整个网络结构
使用下采样(蓝色):这是一条收缩路径。
上采样(黄色):这是一条不断扩大的路径。
这是一个类似于U-Net的FCN架构。
并且从收缩路径到扩展路径之间存在很长的跳过连接。
(b)瓶颈区
使用,因此称为瓶颈。它已在ResNet中使用。
在每次转化前都使用,这是激活前ResNet的想法。
(c)基本块
两个卷积,它也用在ResNet中。
(d)简单块
个卷积
(b)-(d)
所有块均包含短跳转连接。
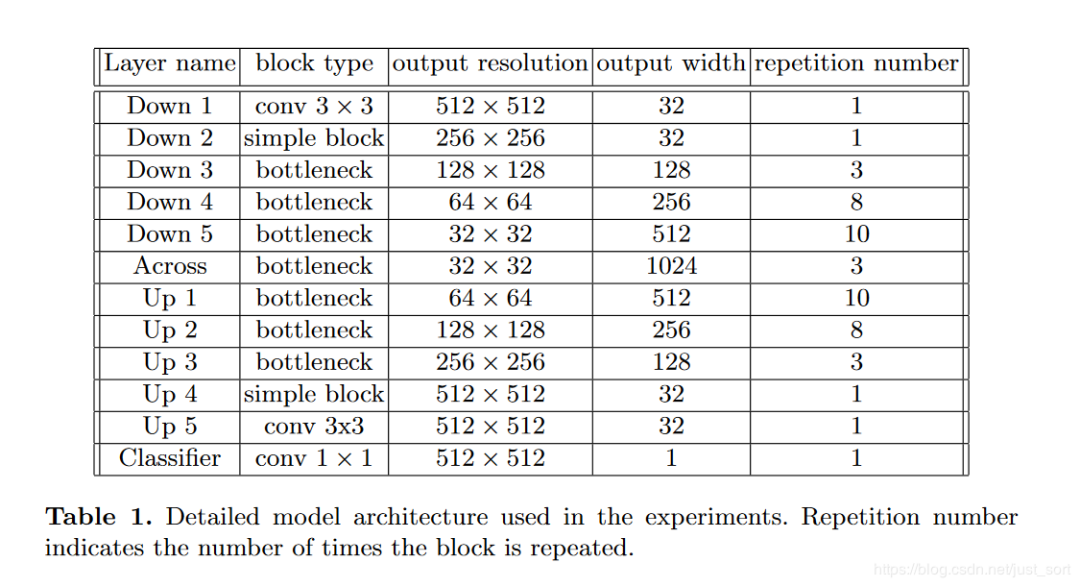
下面的Table1表示整个网络的维度变化:
接下来是这节要分析的重点了,也就是长短跳过网络中两种不同类型的跳跃连接究竟对UNet的结果参生了什么影响?
这里训练集以张电子显微镜(EM)图像为数据集,尺寸为。张图像用于训练,其余张图像用于验证。而测试集是另外张图像。
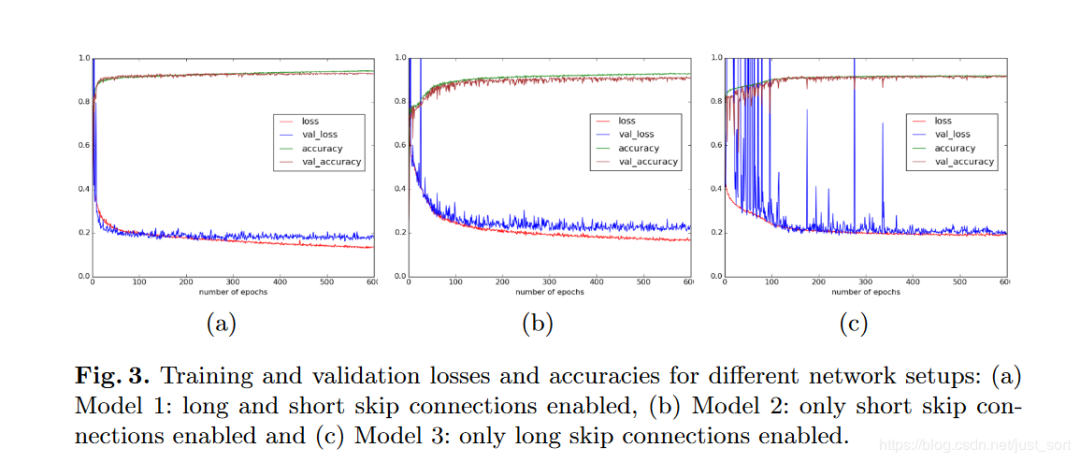
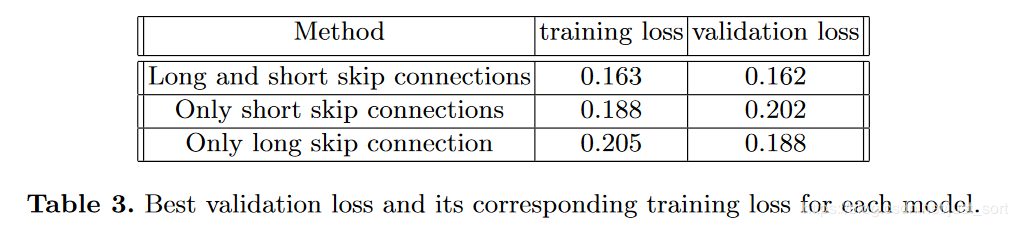
下面的Figure3为我们展示了长短跳过连接,以及只有长跳过连接,只有短跳过连接对准确率和损失带来的影响:
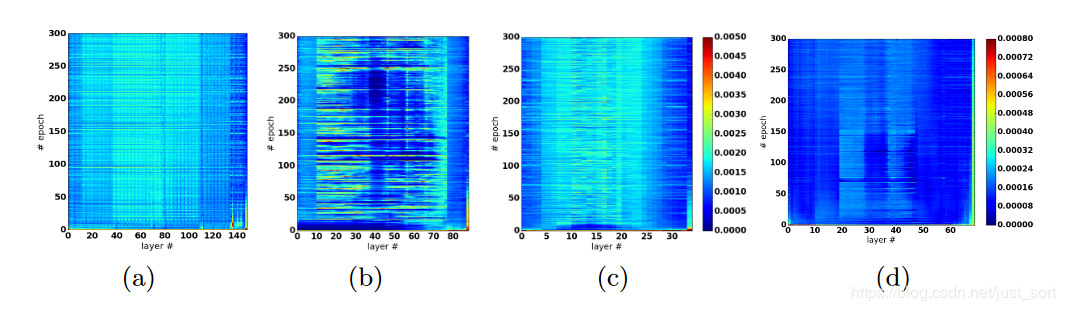
下面来看一可视化权重分析:
(a)长跳和短跳连接
当长跳转和短跳转连接都存在时,参数更新看起来分布良好。
(b)仅长跳连接具有9个重复的简单块
删除短跳过连接后,网络的较深部分几乎没有更新。
当保留长跳连接时,至少可以更新模型的浅层部分。
(c)仅长跳连接具有3个重复的简单块
当模型足够浅时,所有层都可以很好地更新。
(d)仅长跳连接具有7个重复的简单块,没有BN。
论文给出的结论如下:
没有批量归一化的网络向网络中心部分参数更新会不断减少。
根据权值分析的结论,由于梯度消失的问题(只有短跳连接可以缓解),无法更有效地更新靠近模型中心的层。
所以这一节介绍的是将ResNet和UNet结合之后对跳跃连接的位置做文章,通过这种长跳短跳连接可以使得网络获得更好的性能。
7. 总结
这篇文章只是对我个人阅读ResNet相关的类UNet分割结构的一点小总结,希望能起到一点作用科普和给你带来一点点启发。
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~