
分布式事务,原理简单,写起来全是坑!
分布式事务,我们已经给小伙伴介绍了整体内容:
今天我们就一起来看下另一种模式,XA 模式!
其实我觉得 seata 中的四种不同的分布式事务模式,学完 AT、TCC 以及 XA 就够了,Saga 不好玩,而且长事务本身就有很多问题,也不推荐使用。
Seata 中的 XA 模式实际上是基于 MySQL 的 XA 两阶段提交发展出来的,所以学习 XA 模式,需要小伙伴们先理解 MySQL 中的 XA 是怎么一回事,把 MySQL 中的 XA 搞清楚了,再来学习 Seata 中的 XA 模式就容易的多了。
1. 什么是 XA 规范
1.1 什么是两阶段提交
我们先来稍微回顾一下两阶段提交。
先来看下面一张图:
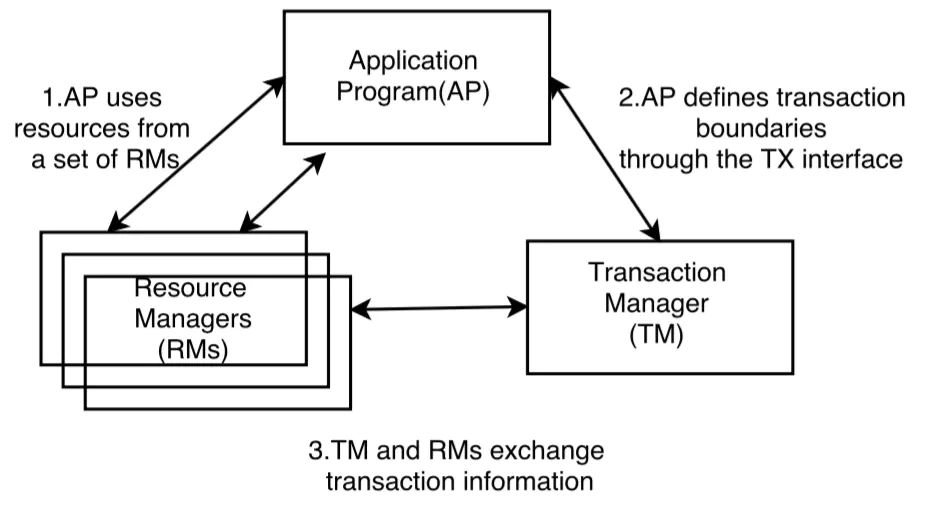
这张图里涉及到三个概念:
AP:这个不用多说,AP 就是应用程序本身。
RM:RM 是资源管理器,也就是事务的参与者,大部分情况下就是指数据库,一个分布式事务往往涉及到多个 RM。
TM:TM 就是事务管理器,创建分布式事务并协调分布式事务中的各个子事务的执行和状态,子事务就是指在 RM 上执行的具体操作。
那么什么是两阶段(Two-Phase Commit, 简称 2PC)提交?
两阶段提交说白了道理很简单,松哥举个简单例子来和大家说明两阶段提交:
比如下面一张图:
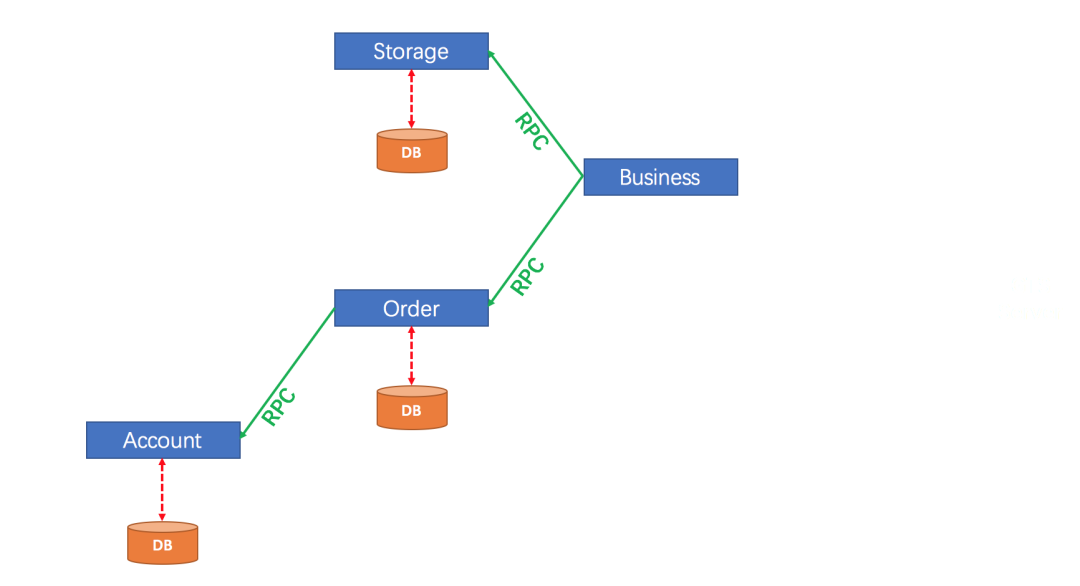
我们在 Business 中分别调用 Storage 与 Order、Account,这三个中的操作要同时成功或者同时失败,但是由于这三个分处于不同服务,因此我们只能先让这三个服务中的操作各自执行,三个服务中的事务各自执行就是两阶段中的第一阶段。
第一阶段执行完毕后,先不要急着提交,因为三个服务中有的可能执行失败了,此时需要三个服务各自把自己一阶段的执行结果报告给一个事务协调者(也就是前面文章中的 Seata Server),事务协调者收到消息后,如果三个服务的一阶段都执行成功了,此时就通知三个事务分别提交,如果三个服务中有服务执行失败了,此时就通知三个事务分别回滚。
这就是所谓的两阶段提交。
总结一下:两阶段提交中,事务分为参与者(例如上图的各个具体服务)与协调者(上文案例中的 Seata Server),参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是要提交操作还是中止操作,这里的参与者可以理解为 RM,协调者可以理解为 TM。
不过 Seata 中的各个分布式事务模式,基本都是在二阶段提交的基础上演化出来的,因此并不完全一样,这点需要小伙伴们注意。
1.2 什么是 XA 规范
XA 规范 是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准。
XA 规范描述了全局的事务管理器与局部的资源管理器之间的接口。XA规范的目的是允许多个资源(如数据库,应用服务器,消息队列等)在同一事务中访问,这样可以使 ACID 属性跨越应用程序而保持有效。
XA 规范使用两阶段提交来保证所有资源同时提交或回滚任何特定的事务。
XA 规范在上世纪 90 年代初就被提出。目前,几乎所有主流的数据库都对 XA 规范提供了支持。
XA 事务的基础是两阶段提交协议。需要有一个事务协调者来保证所有的事务参与者都完成了准备工作(第一阶段)。如果协调者收到所有参与者都准备好的消息,就会通知所有的事务都可以提交了(第二阶段)。MySQL 在这个 XA 事务中扮演的是参与者的角色,而不是协调者(事务管理器)。
MySQL 的 XA 事务分为内部 XA 和外部 XA。外部 XA 可以参与到外部的分布式事务中,需要应用层介入作为协调者;内部 XA 事务用于同一实例下跨多引擎事务,由 Binlog 作为协调者,比如在一个存储引擎提交时,需要将提交信息写入二进制日志,这就是一个分布式内部 XA 事务,只不过二进制日志的参与者是 MySQL 本身。MySQL 在 XA 事务中扮演的是一个参与者的角色,而不是协调者。
2. MySQL 中的 XA
接下来松哥通过一个简单的例子先给大家看下 MySQL 中的 XA 是怎么玩的。
2.1 两阶段事务提交
比如说转账操作,我用 MySQL 中的 XA 事务来和大家演示一下从一个账户中转出 10 块钱:
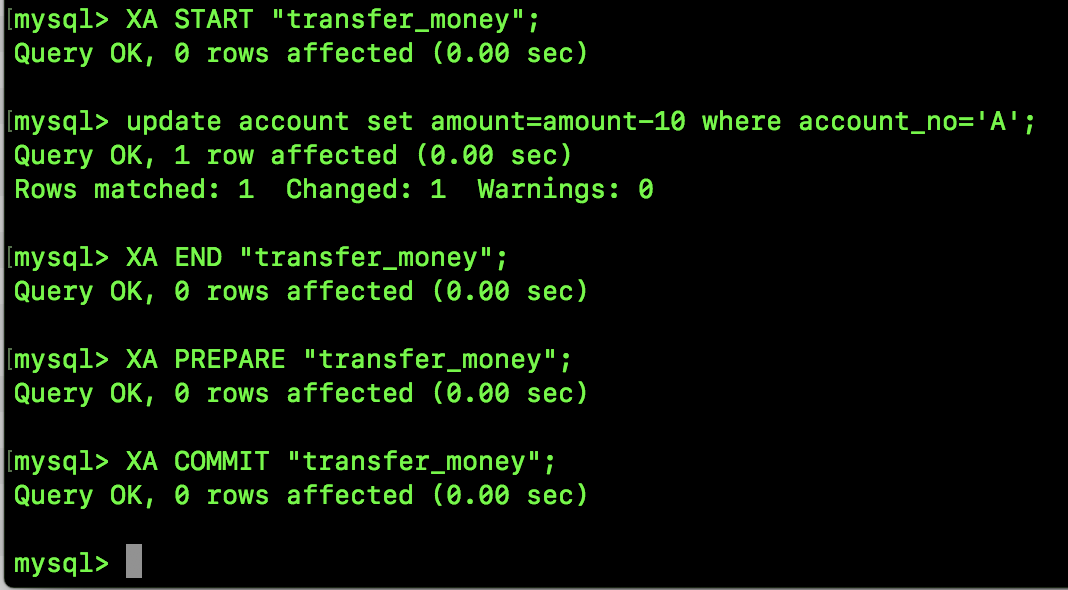
上面这段事务提交是一个两阶段事务提交的案例。
具体执行步骤如下:
XA START "transfer_money":这个表示开启一个 XA 事务,后面的字符串是事务的 xid,这是一个唯一字符串,开启之后,事务的状态变为ACTIVE。
update account set amount=amount-10 where account_no='A'; 这个表示执行具体的 SQL。
XA END "transfer_money":这个表示结束一个 XA 事务,此时事务的状态转为IDLE。
XA PREPARE "transfer_money":这个将事务置为 PREPARE 状态。
XA COMMIT "transfer_money":这个用来提交事务,提交之后,事务的状态就是 COMMITED。
最后一步,可以通过 XA COMMIT 来提交,也可以通过 XA ROLLBACK 来回滚,回滚后事务的状态就是 ROLLBACK。
另外第四步可以省略,即一个 IDLE 状态的 XA 事务可以直接提交或者回滚。
我们来看下面一张流程图:
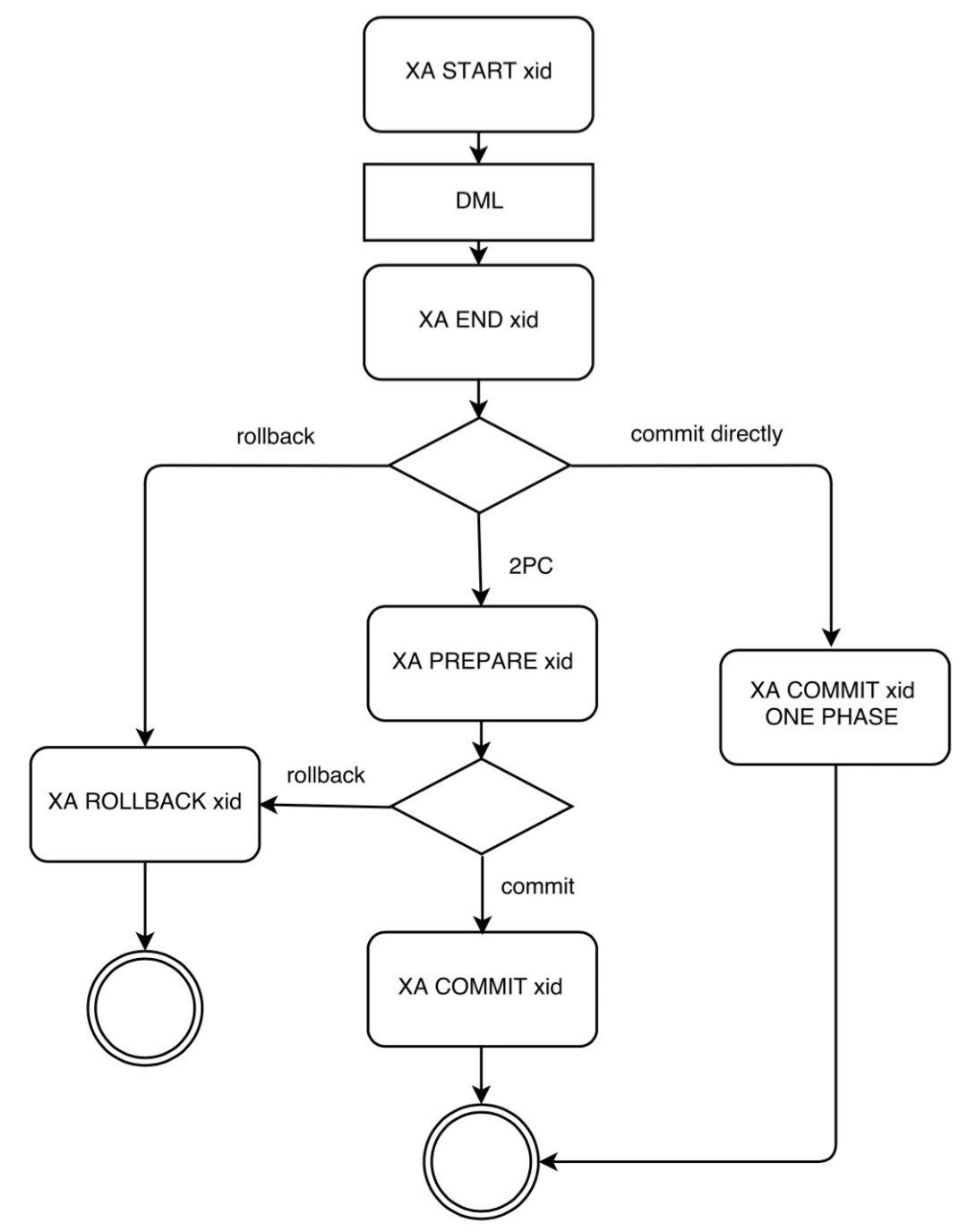
从这张图里我们可以看出,事务可以一步提交,也可以两阶段提交,都是支持的。如果是两阶段提交,prepare 之后,其实是在等其他的资源管理器(RM)反馈结果。
2.2 事务直接提交
松哥再给大家演示一下事务一步提交:
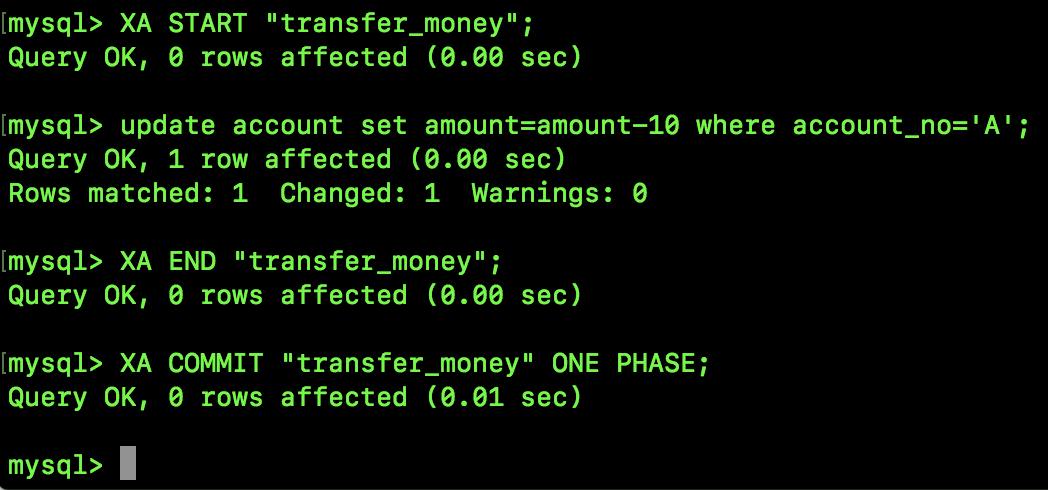
这个就比较简单,没啥好说的。
这块再跟大家介绍另外一个 XA 事务相关的命令 XA RECOVER,如下图:
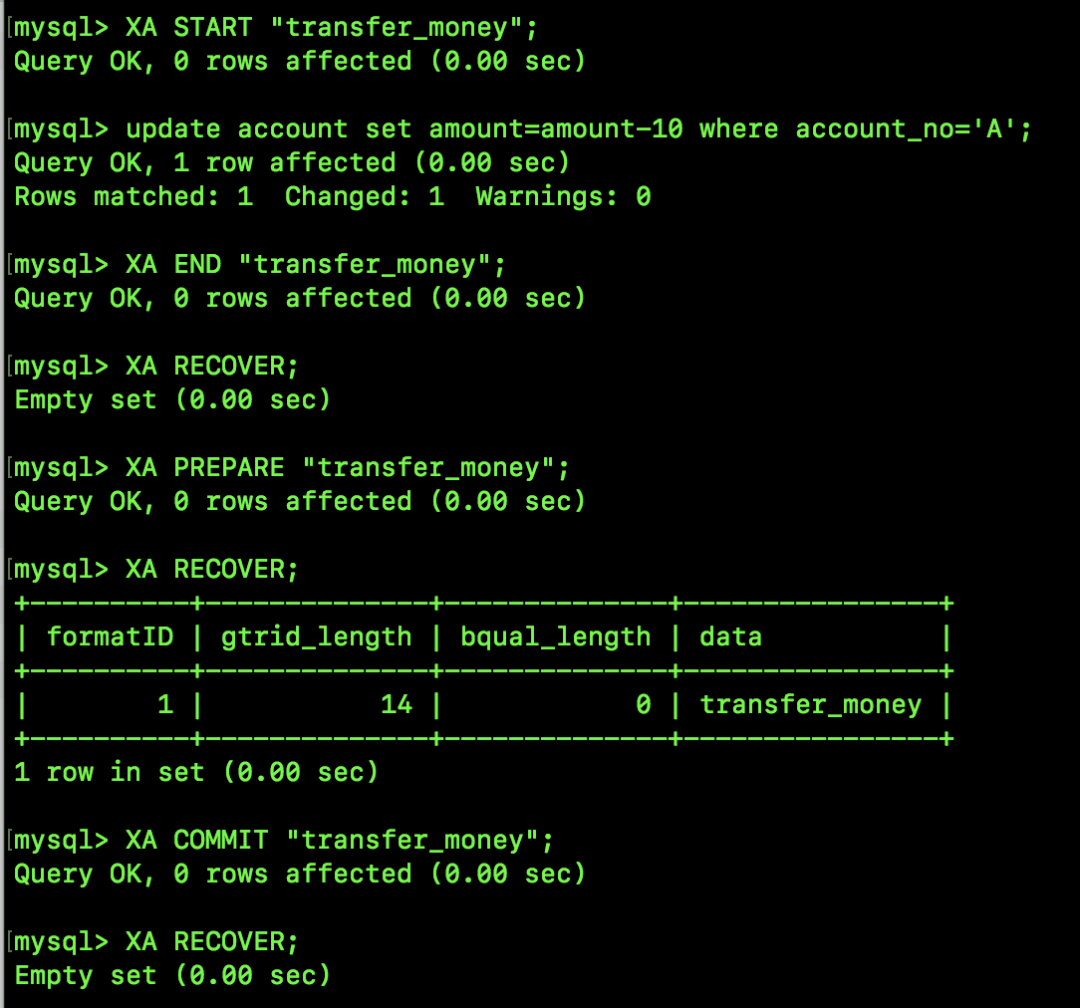
XA RECOVER 可以列出所有处于 PREPARE 状态的 XA 事务,其他状态的事务则都不会列出来,如上图。
2.3 事务回滚
再举一个事务回滚的例子:
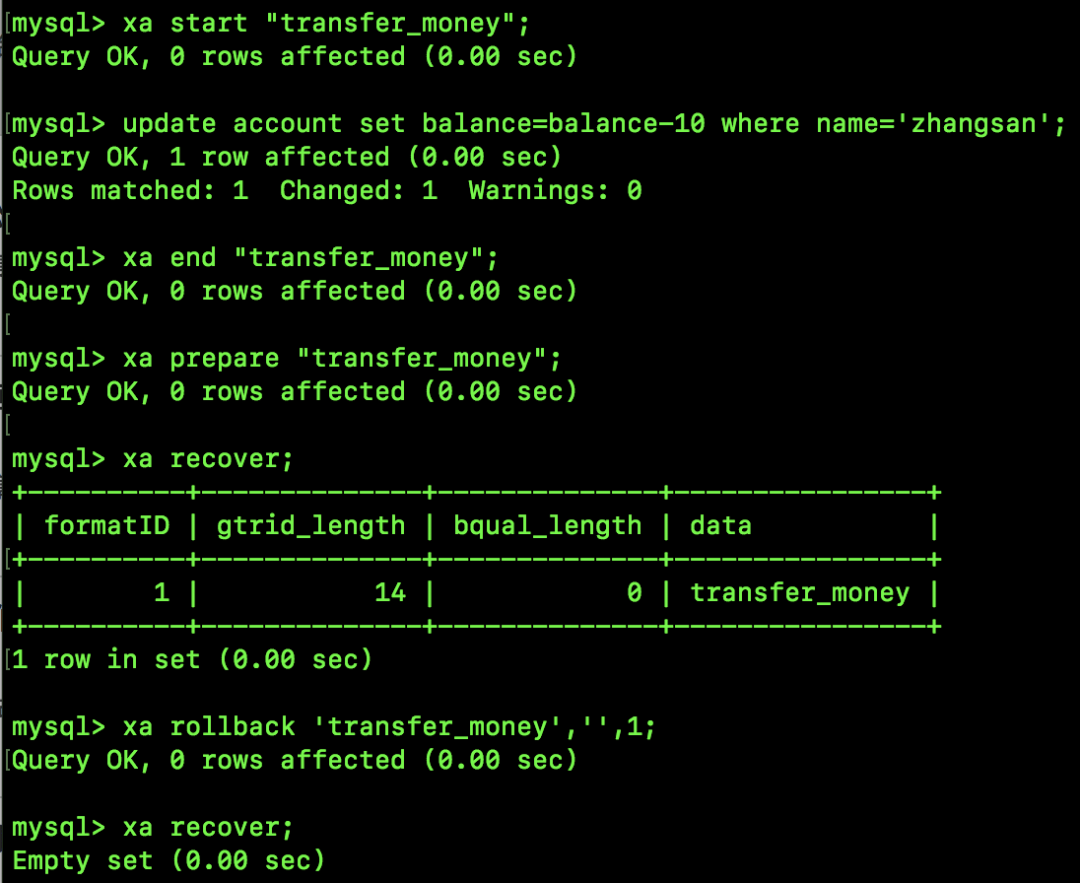
小伙伴们看到,xa recover 可以查看处于 prepare 状态的事务,事务回滚有三个参数:第一个参数,是以 gtrid_length 为依据,从 data 字符串上截取下来的值;第二个参数,是第一个从 data 上截取下来值之后,data 剩余的值,在本案例中,第一次被截取之后,就不剩了,所以第二个参数是一个空字符串;第三个参数是 formatID 的值。
回滚之后,再执行 xa recover 就看不到东西了。
2.4 小结
在用一个客户端环境下,XA 事务和本地(非 XA )事务互相排斥,如果已经通过 XA START 来开启一个事务,则本地事务不会被启动,直到 XA 事务被提交或者被回滚为止。
相反的,如果已经使用 START TRANSACTION 启动一个本地事务,则 XA 语句不能被使用,直到该事务被提交或者回滚为止,而且 XA 事务仅仅被 InnoDB 存储引擎支持。
3. Seata 中的 XA
3.1 Seata 中的 XA 模式
我们先来看一点理论知识,3.3 小节我们再来看代码实践。
通过上面的介绍,大家已经知道了 MySQL 中的 XA 事务是怎么回事了,Seata 中的 XA 模式其实就是在 MySQL 中 XA 模式的基础上实现的。Seata 中的 XA 模式就是在 Seata 定义的分布式事务框架内,利用事务资源(数据库、消息服务等)对 XA 协议的支持,以 XA 协议的机制来管理分支事务的一种事务模式。
我们来看下面一张图:
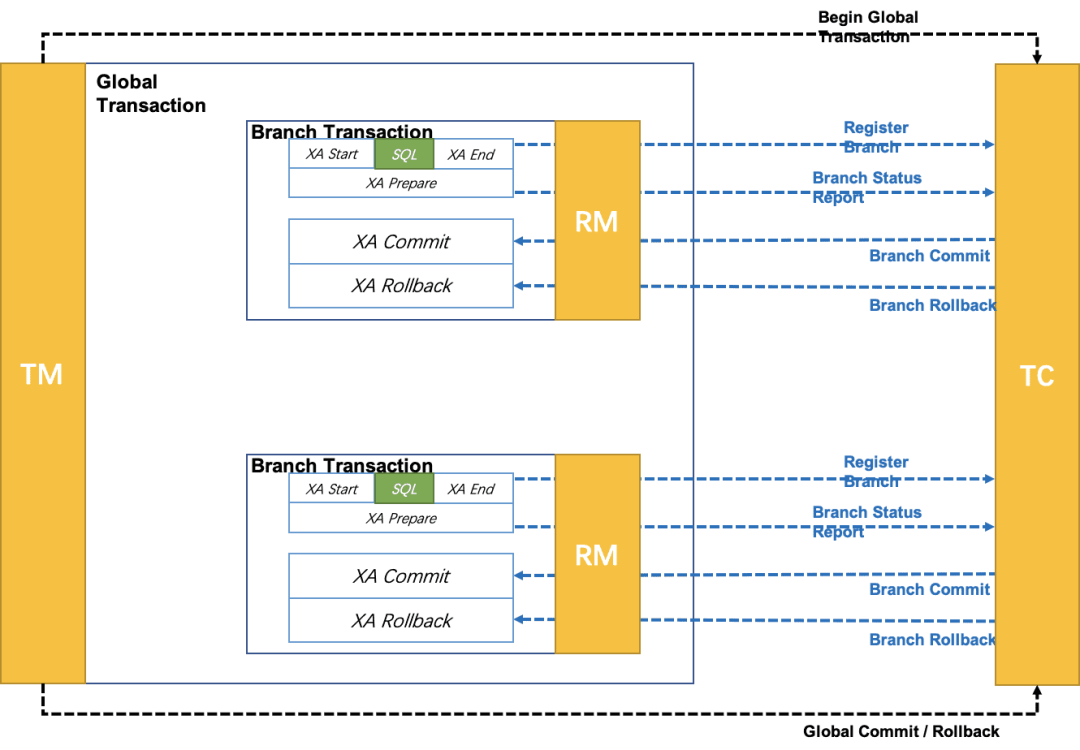
我来大概说一下这个执行步骤:
首先由 TM 开启全局分布式事务。
各个业务 SQL 分别放在不同的 XA 分支中进行,具体执行的流程就是XA Start->业务 SQL->XA End,这个流程跟我 2.1 小节和大家演示的 MySQL 中 XA 事务的流程是一致的。
分支中的 XA 事务执行完成后,执行XA prepare,并将自己执行的状态报告给 TC。
其他的分支事务均按照 2、3 步骤来执行。
当所有分支事务都执行完毕后,TC 也收到了各个分支事务报告上来的执行状态,如果所有状态都 OK,则 TC 通知所有 RM 执行XA Commit完成事务的最终提交,否则 TC 通知所有 RM 执行XA Rollback进行事务回滚。
这就是 Seata 中的 XA 模式!只要小伙伴们理解了 2.2 小节中 MySQL 的 XA 模式,那么 Seata 中的 XA 模式就很好理解了。
3.2 特色
前面小伙伴们已经学会了 AT 和 TCC 两种不同的分布式事务模式了,现在再加入一个 XA,我们再来把这三个放在一起比较下。
AT 和 TCC 都是通过反向补偿将数据复原的,也就是说,通过一条更新语句将数据复原;XA 因为是 MySQL 自己的功能,所以不是反向补偿,而是正儿八经的回滚(处于 prepare 状态的数据并没有 commit,将来在二阶段可以选择 commit 或者 rollback)。
AT 和 XA 模式是无侵入的分布式事务解决方案,适用于不希望对业务进行改造的场景,几乎0学习成本;TCC 则有一定的代码侵入。
AT 和 XA 都是一种全自动的,无论是提交呀,回滚呀(无论是真回滚还是反向补偿),都是全自动的,就是开发者基本上不需要额外做什么事情;TCC 则是一种手动的分布式事务,一阶段的 prepare、二阶段的 commit 或者 rollback,所有逻辑都是开发者自己写的。
松哥发前面文章的时候,有小伙伴提到分布式事务的一致性问题,XA 模式是分布式强一致性的解决方案,但是因为性能低而导致使用较少。
好啦,比较完啦,那就上代码吧!
3.3 代码实践
小伙伴们只需要搞明白前面的 AT 模式后,XA 模式其实跟 AT 模式差不多!就是替换一下数据源即可!话是这么说,不过真做起来,还是有很多坑,我们一起来看下。
为了方便大家理解,本文我就不重新搞案例了,咱们还用上篇文章那个下订单的案例来演示。
这是一个商品下单的案例,一共有五个服务,我来和大家稍微解释下:
eureka:这是服务注册中心。
account:这是账户服务,可以查询/修改用户的账户信息(主要是账户余额)。
order:这是订单服务,可以下订单。
storage:这是一个仓储服务,可以查询/修改商品的库存数量。
bussiness:这是业务,用户下单操作将在这里完成。
这个案例讲了一个什么事呢?
当用户想要下单的时候,调用了 bussiness 中的接口,bussiness 中的接口又调用了它自己的 service,在 service 中,首先开启了全局分布式事务,然后通过 feign 调用 storage 中的接口去扣库存,然后再通过 feign 调用 order 中的接口去创建订单(order 在创建订单的时候,不仅会创建订单,还会扣除用户账户的余额),在这个过程中,如果有任何一个环节出错了(余额不足、库存不足等导致的问题),就会触发整体的事务回滚。
本案例具体架构如下图:
这个案例就是一个典型的分布式事务问题,storage、order 以及 account 中的事务分属于不同的微服务,但是我们希望他们同时成功或者同时失败。
这个案例的基本架构我这里就不重复搭建了,这里我们主要来看 XA 事务如何添加进来。
3.3.1 数据库配置
由于 XA 模式利用的是 MySQL 自身对 XA 规范的实现,所以 XA 机制实际上是不需要 undo_log 表的,小伙伴们可以把你 AT 模式中的 undo_log 表删除啦~ 如果删除后运行 Java 程序报错,那说明你的 XA 模式使用的不地道!注意看松哥后面的讲解哦。
接下来我就来说几个要点。
数据库驱动
这是一个坑。松哥经过反复测试,seata 中的 XA 模式和最新版的 MySQL 驱动不兼容,运行时候会有错误,经过测试,MySQL 8.0.11 这个版本的驱动是没问题的,所以在 account、storage 以及 order 三个需要数据库调用的服务上,记得修改一下数据库驱动依赖的版本号:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
<version>8.0.11</version>
</dependency>
druid 依赖
有的小伙伴们看到这里用到了阿里的 Druid 数据库连接池,就赶紧加入这个依赖!殊不知,这又掉入版本兼容的坑了,spring-cloud-starter-alibaba-seata 依赖中实际上包含了 druid 依赖,而且版本号是没有问题的!所以小伙伴们千万别自己手动加 druid 依赖,可能会因为版本号问题掉坑。
关掉数据源代码
接下来就是关闭掉 seata 数据源代理了,account、storage 以及 order 里边都改一下,加入如下配置:
seata.enable-auto-data-source-proxy=false
配置自定义数据源
接下来就是配置自定义数据源了,account、order 以及 storage 都要配置,如下:
@Configuration
public class DataSourceConfiguration {
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DruidDataSource druidDataSource() {
return new DruidDataSource();
}
@Bean("dataSourceProxy")
@Primary
public DataSource dataSource(DruidDataSource druidDataSource) {
return new DataSourceProxyXA(druidDataSource);
}
@Bean
public SqlSessionFactory sqlSessionFactory(DataSource dataSourceProxy)throws Exception{
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSourceProxy);
sqlSessionFactoryBean.setTransactionFactory(new SpringManagedTransactionFactory());
return sqlSessionFactoryBean.getObject();
}
}
先配置 DruidDataSource,但这不是我们最终目的,最终目的是配置 DataSourceProxyXA,看名字就知道,这就会把事务切换为 XA 模式,最后,还需要基于 DataSourceProxyXA 来配置一下 MyBatis,都是常规操作,不多说。
好啦,就这样,我们的 seata XA 模式就配置好啦~其他的代码都和 AT 模式一样,不再赘述。