
分布式数据库系统面临的问题和挑战
分布式数据库系统在逻辑上可以看作一个完整的系统,用户如同在使用单机数据库系统;但是,从物理角度看,其为一个网络系统,包含若干个物理意义上的分散的节点,而节点之间通过网络进行连接,通过网络协议进行数据交换。
分布式数据系统需要应对网络故障、节点故障。网络故障会直接导致分区事件(CAP
原理中的P,即网络发生故障使得网络被分为多个子部分)发生,系统的可用性会受到影响;节点故障可能会引发单点故障,也就是在数据为单副本的情况下节点故障会直接导致部分数据不能被访问。为避免单点故障,数据需要有多个副本,从而使系统的可用性得到较大提高。节点故障也可能引发分区事件。
除了上述问题外,分布式数据库系统还可能带来不一致问题。比如旧读(stale read)问题,即读操作发生于数据项更新之后,此时本应该读取到的是该数据项的最新值,但是却读到了旧值。产生该问题的原因是,分布式数据库系统没有一个统一的时钟,这会导致反序读取数据的情况出现。这种情况在单机系统中是不存在的。这里所说的不一致现象,以及与其类似的不一致性现象,在这里称为数据读取序不符合数据生成序,简称分布式不一致。
为了解决分布式不一致问题,诸多学者经过大量的研究提出了多种分布式一致性的概念,如线性一致性(linearizability)、顺序一致性(sequential consistency)、因果一致性(causal consistency),以及Google Spanner的外部一致性(external consistency)等。
分布式数据库系统需要解决分布式不一致问题,使观察者能读取到满足一致性的数据,以确保数据之间的逻辑一直是有序的。本节后续内容将针对这个问题展开讨论:首先讨论通用的分布式系统所面临的问题,然后讨论因数据异常引发的一致性问题,最后讨论与分布式数据库相关的其他问题。
分布式数据库系统面临的问题
单机数据库系统为了应对事务故障和对事务进行管理,专门提供了UNDO日志、回滚段等措施,目的就是实现事务的回滚;为了应对系统故障,采用了WAL技术做日志,目的是先于事务进行持久化存储;为了应对介质故障,专门提供了逻辑备份、物理备份等多种手段,目的是在数据层面、日志层面和物理数据块层面实现数据冗余存储。
相对于单机数据库系统而言,除了上述问题外,分布式数据库系统面临着更多的挑战。这些挑战源自分布式数据库系统的架构,其和单机数据库系统不同,因而在技术层面上存在差异。
1. 架构异常
架构异常是指用户因数据库的架构而产生的数据异常,严格地讲,这不属于数据库系统领域的数据异常。从用户的角度看,事务一直在执行中,但是读写数据时产生了类似前述的顺序问题、数据异常等,本书统称这种异常为架构异常。架构异常和分布式架构相关,分布式架构包括一主一备架构、一主多备架构、多主多备架构等。在分布式架构中,前端可能都有一个类似代理(proxy)的组件面向用户提供透明的高可用服务,代理组件屏蔽了后端多个单机系统故障,所以在用户看来,分布式架构上的所有操作都是在一个事务中进行的,而因架构引发的异常也是数据异常。
如下讨论一种已知的架构异常,该架构异常会导致读取到的数据不一致。我们以MySQL的主备架构Master-Slave为例进行说明(其他数据库的同类架构存在类似隐患)。此类不一致是这样产生的。MySQL支持Master-Slave架构。假设在Master上执行事务T,此时先按条件“score>90”进行查询,发现没有符合条件的事务,故成功写入Binlog File的数据,假设其为95(事务提交),然后在复制的过程中宕机,导致复制失败。Master重启时,会直接对数据95进行提交操作,之后Master会将数据95异步复制到Slave。但是,此时原来的Slave可能已经切换为主机并开始提供服务,比如新事务写入数据98,而原来Master上的95没有被复制到新Master上,这就会造成两台MySQL主机的数据不一致。
如果在主备MySQL服务前端还有一个代理服务器,对用户而言,这会屏蔽后台的主备服务,用户就会认为“只有一个MySQL”提供服务,因此数据95丢失对用户而言是不可接受的。
还有一种情况,如果代理服务器在原始的Master宕机后没有结束用户的事务T,而是把事务T连接到原备机,并将原备机变更为新Master。这时,对于新Master而言,会发生两个事务,一个新事务T1在一定WHERE条件下写入98,另一个是继续执行的原事务T,若此时原事务T再次发起读操作(逻辑上还在同一个事务内),就会发现自己写过的数据95消失了,这对于用户而言是不可接受的。从分布式一致性的角度看,这违背了“Read-your-writes”(读你所写)原则。从事务的角度看,可能出现“幻读”,即再次按条件“score>90”查询,额外读到事务T1写入的98,所以出现了事务的数据异常。
与上述相似,官方对MySQL上出现Master-Slave之间数据不一致的情况,也进行了描述。
如下图1所示,如果把数据扩展到多副本,把读操作扩展到允许从任何副本读取数据,把写操作扩展到允许向任何副本写入数据,如果是去中心化的架构(即没有单一的全局事务管理机制)且发生了网络分区或延,则在事务一致性视角、分布式一致性视角下去观察数据的读或写操作,会发现存在更为复杂的问题。
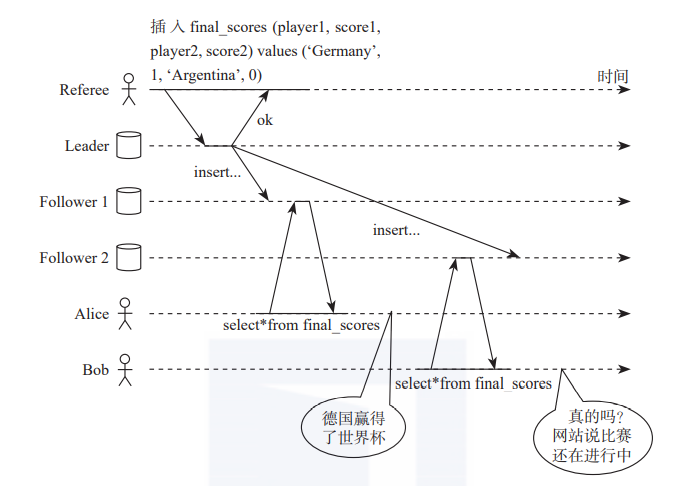 图1 多副本异常图
图1 多副本异常图
Distributed algorithms and protocols讨论了一种在多副本情况下,副本间数据同步与数据可见性的异常情况,其所用的示例如图1所示:足球世界杯比赛结果出炉,比赛结果经过Leader节点记录到数据库。事实结果是德国赢得了世界杯冠军。但是,数据从Leader节点同步到两个不同的Follower节点的时候,Alice和Bob同处一室,从不同的Follower节点上查询世界杯的比赛消息,结果Alice得知德国夺冠,而Bob却得到比赛还没有结束的消息。二人得到了不同的消息,产生了不一致。这也是分布式架构下因多副本支持Follower读带来的不一致的问题。
2. 分布式一致性和事务一致性
为了帮助大家充分理解分布式系统中存在的问题,我们不妨做一个类比。
若是世界上只有一个人,那么这个世界的关系是非常简单的,但是一旦有多个人,“社会”就会形成。其中,社会关系指的就是人与人之间建立的关系,这种关系会随着人的数量的增加而不断复杂化。这种复杂的社会关系与数据库结合到一起得到的就是分布式数据库系统,社会中的人就相当于分布式数据库系统中的一个物理节点或者一个物理节点中的一份数据副本。图2以一个NewSQL系统的架构为例描述分布式数据库中存在的多个问题。
因为分布式数据库要存储海量数据,要对数据分而治之,所以引入了数据分片的概念。从逻辑的角度看,每个节点的数据都是一个或多个数据分片,但是数据库要满足“高可用、高可靠”以及在线实时提供服务的特性,因此每个数据分片就有了多个副本。数据多副本使得分布式数据库的“一致性”问题变得更为复杂。
我们从读和写两个不同的角度来感性了解一下分布式数据库中存在哪些不一致的问题。
首先,图2所示的分布式数据库系统存在4个数据分片—A、B、C、D,每个分片又存在3个副本,且每个分片的3个副本中有一个是Leader,另外两个是Follower(比如Raft分布式协议中的Leader和Follower)。
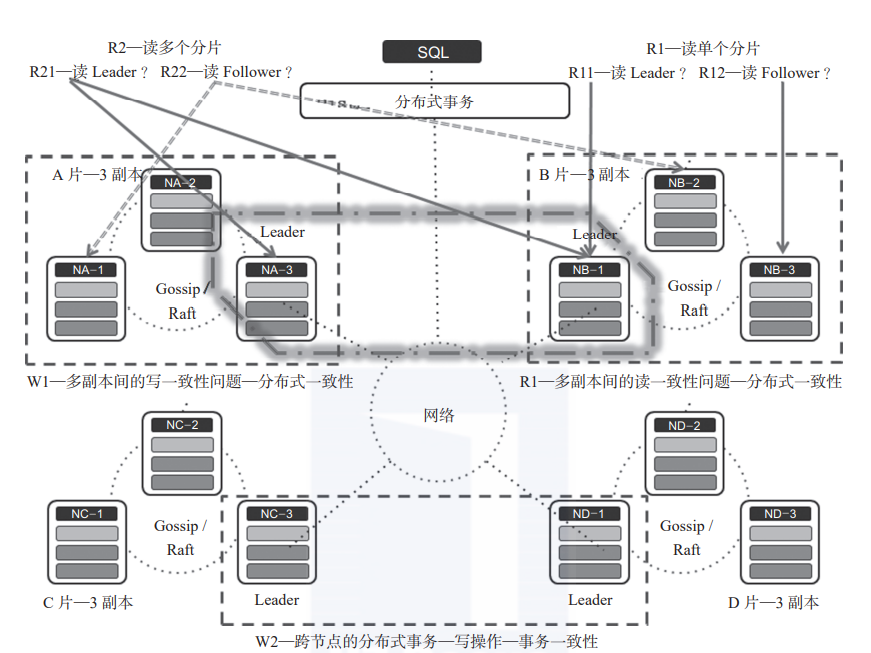
图2 分布式数据库的一致性问题关系图
其次,对于写操作,图2所示有如下两种情况。
1)写单个数据分片—W1:在这种情况下,一个事务不能针对多个节点进行操作,所以这样的事务是典型的单节点事务,类似于单机数据库系统中的事务。写单个数据分片可以由单个节点上的事务处理机制来确保其具有ACID特性。为了实现写单个数据分片的数据一致性,可只使用数据库系统中的并发访问控制技术,如2PL(Two-phase Locking,两阶段封锁)、TO(Timestamp Ordering,时间戳排序)、MVCC(Multi Version Concurrency Control,多版本并发控制)等。
2)写多个数据分片—W2:通过一个事务写多个数据分片,这就是典型的分布式事务了,此时需要借助诸如分布式并发访问控制等技术来保证分布式事务的一致性,需要借助2PC(Two-phase Commit,两阶段提交)技术保证跨节点写操作的原子性。另外,如果需要实现强一致性(详见5.6节),还需要考虑在分布式数据库范围内,确保ACID中的C和CAP中的C的强一致性相结合(即可串行化和线性一致性、顺序一致性的结合)。诸如Spanner等很多数据库系统,都使用线性一致性、SS2PL(Strong Strict 2PL)技术和2PC技术来实现分布式写事务的强一致性。CockroachDB、Percolator等分布式数据库则使用了OCC类的技术做并发访问控制来确保事务一致性(可串行化),并使用2PC来确保分布式提交的原子性,但它们没有实现强一致性,其中CockroachDB只实现了顺序可串行化。保证分布式事务一致性的技术还有很多,第4章将详细讨论。
对于写多个数据分片的情况来说,因为在每个数据分片内部存在多个副本,所以如何保证副本之间的数据一致性,也是一个典型的分布式系统一致性问题(第2章会详细讨论分布式系统的一致性问题,第3章会详细讨论多副本在共识算法加持下的一致性问题),著名的Paxos、Raft等协议就是用来解决分布式系统的多副本共识问题的。此种情况下,通常没有写操作会发生在图1-6所示的A的Leader和B的Follower这样的组合中。
如果一个系统支持多写操作,则多写会同时发生在多个数据分片的Leader上。
对于读操作,图2所示也有如下两种情况。
1)读单个数据分片—R1:如果一个事务只涉及单个节点,则这个事务读取操作的数据一致性一定能保障(通过节点上的事务机制来保障)。如果涉及多个节点,那么此时的R1就会被分为R11和R12两种读取方式。
R11方式用于读取Leader:因为进行写操作时首先写的是Leader,所以如果写事务已经提交,那么一定能够保证R11读取的数据是已经提交了的最新数据。如果写事务没有提交,那么此时Leader上若是采用MVCC技术,则R11读取的会是一个旧数据,这样的读取机制可以保证R11读数据的一致性;Leader上若是采用封锁并发访问控制机制,则读操作会被阻塞直至写事务提交,因而在这种机制下R11读取的是提交后的值,从而保证读数据的一致性,换句话说,这种情况下,保证数据一致性依赖的是单节点上的事务并发访问控制机制。同时,这也意味着一个分布式数据库系统中单个节点的事务处理机制应该具备完备的事务处理功能。
R12的方式用于读取Follower:读取Follower时又分为如下两种情况。
在一个分片内部,主副本和从副本(即Leader和Follower)之间是强同步的(Leader向所有Follower同步数据并在应用成功之后向客户端返回结果)。这种情况下不管是读Leader还是读Follower,数据一定是完全相同的,读取的数据一定是一致的。
Leader和Follower之间是弱同步的(Leader没有等所有Follower同步数据并应用成功之后,就向客户端返回结果),如采用多数派协议就可实现弱同步。此时Leader和Follower之间会存在写数据延时,即从Follower上读取到的可能是一个旧数据,但是因为事务的读操作只涉及一个节点,所以也不会产生读操作数据不一致的问题。这就如同MySQL的主备复制系统中备机可以提供只读服务一样。
2)读多个数据分片—R2:注意这种情况下的读操作会跨多个分片/节点,如果事务处理机制不妥当,会产生不一致的问题。而这样的不一致问题,既可能是事务的不一致,也可能是分布式系统的不一致。下面还是以图1-6所示为例进行介绍。假设只读取A、B两个数据分片,这时有如下4种情况。
读A的Leader和B的Leader,这种情况简称全L问题。
事务的一致性:如果存在全局的事务管理器,那么此时读多个数据分片的操作如同在单机系统进行数据的读操作,通过封锁并发访问控制协议或者MVCC(全局快照点)等技术,可以确保读操作过程中不发生数据异常。因为其他事务的写操作会为本事务的读操作带来数据不一致的问题,所以通过全局的并发访问控制协议(如全局封锁并发访问控制协议等技术),能够避免出现事务层面的数据不一致问题。但是,如果没有全局的并发访问控制协调者,则容易出现跨节点的数据异常,所以需要由特定的并发访问控制协议加以控制。
分布式系统的一致性:这类问题只在“读A的Leader和B的Leader”这种结构中存在,分布式数据库需要通过实现“强一致性”来规避因分布和并发带来的分布式事务型数据系统的一致性问题。具体可能出现的问题会在第2章介绍。
读A的Leader和B的Follower,这种情况简称LF问题。B的Leader和Follower之间存在时延,即传输存在时延,从而带来主备复制之间的数据不一致问题。如果支持“读A的Leader和B的Follower”这样的方式,需要确保所读取的节点(A的Leader节点、B的Follower节点)上存在共同的事务状态。
读A的Follower和B的Leader,这种情况简称FL问题。问题的分析和解决方法同上。
读A的Follower和B的Follower,这种情况简称全F问题。问题的分析和解决方法同上。
若是在读数据时,同时存在事务的一致性和分布式系统的一致性问题,那么就需要通过强一致性来解决。
总体来说,事务的一致性是因并发的事务间并发访问(读写、写读、写写冲突)同一个数据项造成的,而分布式一致性是因多个节点分散、节点使用各自的时钟,以及没有对各个节点上发生的操作进行排序造成的。
本书摘编自《分布式数据库原理、架构与实践》,经出版方授权发布。
推荐阅读
