
一次性汇总了 30+ 字符串常用处理方法
今天这篇推文我们就汇总下Python中常用的字符串处理小技巧,字符串在Python数据处理中是非常常见且极易忽略的常用数据类型,且Python本身也提供大量运算符、函数和方法来处理字符串。话不多说,接下来我们就汇总下字符串处理小技巧(ps:都是小编经常用到的处理技巧,可能不是很全哦)
字符串常用操作
1、+ 操作
这个操作相对简单,就是对字符串进行组合,如下:
a = "Data"
b = "Charm"
print(a+b)
# DataCharm
2、* 操作
* 操作一般都是重复字符串的个数,举例如下:
a="DataCharm"
print(a*3)
# DataCharmDataCharmDataCharm
3、in 操作
这个操作在我的数据处理过程中经常使用到,用于判断某个字符是否在指定的字符串中,进而进行下一步的操作,这个和pandas数据筛选结合使用,可以快速选择出对应的数据。
s = "DataCharm"
print(s in "The best place to learn Python is DataCharm")
#True
根据返回的 True 或False 结果就可以灵活进数据判断和数据选择了(结合pandas布尔类型),而 not in 则是 in 的反操作,其他都是一样的。
4、[] 和[:] 通过索引获取字符串中字符
这两个字符串操作是使用频次较多的操作了:
[] 可通过具体的索引号选择字符串中的字符;
[:] 可以拆分字符串,进而获取字符串中的一部分。
下面我们通过具体例子进讲解,首先,有字符串如下(标注了索引号和反索引号,注意:python正序索引是从0开始,倒序索引从-1开始)
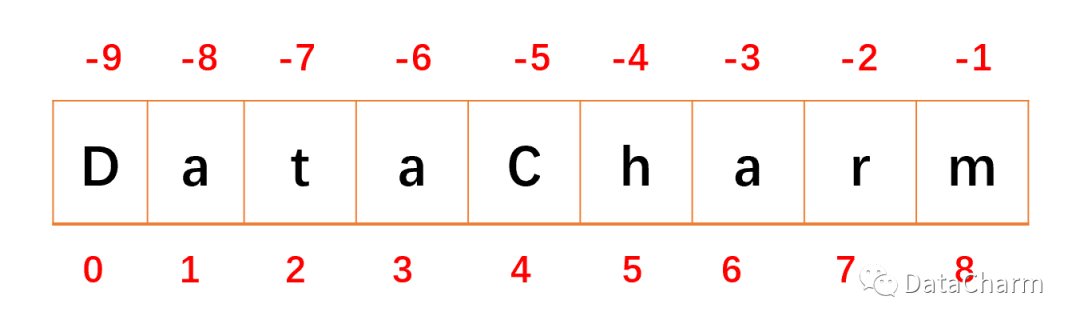
接下来的内容我们将直接通过代码进行展示:
正序取数
s = "DataCharm"
s[0]
#'D'
s[1]
#'a'
# 一旦取值超过索引范围,则会显示出错,如下:
s[9]
#IndexError: string index out of range
倒序取数
s = "DataCharm"
s[-1]
#'m'
字符串的切片处理这一部分为字符串常用部分,希望小伙伴们可以仔细阅读理解
s = "DataCharm"
s[0:4]
#'Data'
s[:4]
#'Data'
还可以:
s[:4] + s[4:]
#'DataCharm'
s[:4] + s[4:] == s
#True
对于倒序:
s = "DataCharm"
s[-5:-2]
#'Cha'
#相当于正序取数如下:
s[4:7]
#'Cha'
s[-5:-2] == s[4:7]
#True
切片中我们还可以指定步长
s = "DataCharm"
s[0:6:2] # 索引位置0~5,每隔1个进行取数
#'DtC'
将第一个和第二个索引可以省略,并且分别默认为第一个和最后一个字符:
s = "DataCharm"
s[::2]# 忽略第一个和第二个索引
# 'DtCam'
s[2::2]# 忽略第二个索引,默认为最后一个字符
# 'tCam'
指定一个负的步长,这种情况下,字符串将倒序取值,且第一个索引应大于第二个索引:
s = "DataCharm"
s[9:0:-2]
# 'maCt'
s[::-2]
# 'maCtD'
当设置为-1时,则将原字符串进行反转,这也是较常用的操作之一哦,如下:
s = "DataCharm"
s[::-1]
# 'mrahCataD'
字符串常用内置方法
python 字符串操作内置了许多处理方法,这里我们只列举出我在实际使用中常用的的内置方法。
s.capitalize():把字符串的第一个字符大写,其他字符串小写
s = "dataCharm"
s.capitalize()
#'Datacharm'
s.lower():转换 string 中所有大写字符为小写
s = "DataCharm"
s.lower()
#'datacharm'
s.swapcase():将字符串中大写的变小写,小写的变大写
s = "DataCharm"
s.swapcase()
# 'dATAcHARM'
s.title():将所有单词都是以大写开始,其余字母均为小写
s = "data charm"
s.title()
#'Data Charm'
s.upper():将 string 中的小写字母为大写
s = "datacharm"
s.upper()
#'DATACHARM'
s.endswith(obj)和 s.startswith(obj):检查字符串是否是以 obj 开头(开头),是则返回 True,否则返回 False
这两个字符串内置方法为常用方法,特别是数据选择过程中,当然和pandas结合,实现高效取数。
s = "DataCharm"
s.startswith("Data")
#True
s.endswith("Data")
#False
s.strip([chars])、 s.lstrip([chars])和 s.rstrip([chars]):删除 string 字符串开头和结尾、开头、结尾的指定的字符(chars)(默认为空格)
该方法为较常使用在数据清洗过程中,如爬取的字符串数据需要去除多余空格。
s = " DataCharm "
s.strip()
#'DataCharm'
s.lstrip()
#'DataCharm '
s.rstrip()
#' DataCharm'
s.find(str, beg=0, end=len(s)):检测str是否包含在s 中,如果在 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1。
s.count(str, beg=0, end=len(s)):返回 str 在 s 里面出现的次数,如果 在beg 或者 end 指定指定范围内,则返回 str 出现的次数
s.split("str"):以指定字符(str)分割字符串,返回多个字符串组成的列表。
字符串和列表之间的转换
这个小技巧也是我在数据处理过程中经常使用的,所以单独进行讲解。
将列表转换成字符串,我们可以使用 .join() 方法操作
list_test = ['foo', 'bar', 'baz', 'qux']
str_from_list = " ".join(list_test)
str_from_list
# 'foo bar baz qux'
type(str_from_list)
# str
将字符串转换成列表,则直接使用s.split()方法即可
str_test = "foo bar baz qux"
list_from_str = str_test.split(" ")
list_from_str
#['foo', 'bar', 'baz', 'qux']
type(list_from_str)
#list
字符串格式化处理
这里建议大家使用str.format() 方法进行字符串格式化输出。str.format()基本格式为
"xxx{ }xxx".format(参数)
这里我们列出几种常见的形式,具体详细的大家可自行搜索(主要是太多,我列出常用的几个即可)
#方式一:
'{0}, {1}, {2}'.format('a', 'b', 'c')
#方式二:
'{}, {}, {}'.format('a', 'b', 'c')
指定数字类型
b: 输出整数的二进制方式;
c: 输出整数对应的Unicode字符;
d: 输出整数的十进制方式;
o: 输出整数的八进制方式;
x: 输出整数的小写十六进制方式;
X: 输出整数的大写十六进制方式;
保留两位小数(使用较多)
'π is {:.2f}'.format(3.1415926)
# 'π is 3.14'
数字千位符格式
'{:,}'.format(123456789)
#'123,456,789'
百分比表示
"{:.0%}".format(3/10)
#'30%'
"{:.3%}".format(3/10)
#'30.000%'
日期格式表示
import datetime
date = datetime.datetime(2020, 2, 1, 23, 20, 58)
'{:%Y-%m-%d %H:%M:%S}'.format(date)
#'2020-02-01 23:20:58'
总结
以上就是关于我在实际使用过程中常用的Python字符串操作方法,由于是小编常用到的,可能不是很全,但绝对是常用操作,希望对大家有所帮助,更多Python 字符串操作,小伙伴们可自行搜索哦!
推荐阅读 误执行了rm -fr /*之后,除了跑路还能怎么办?! 程序员必备58个网站汇总 大幅提高生产力:你需要了解的十大Jupyter Lab插件