
人人都能看懂的 LSTM
这是在看了台大李宏毅教授的深度学习视频之后的一点总结和感想。看完介绍的第一部分RNN尤其LSTM的介绍之后,整个人醍醐灌顶。本篇博客就是对视频的一些记录加上了一些个人的思考。
0. 从RNN说起
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好地解决这类问题。
1. 普通RNN
先简单介绍一下一般的RNN。
其主要形式如下图所示(图片均来自台大李宏毅教授的PPT):
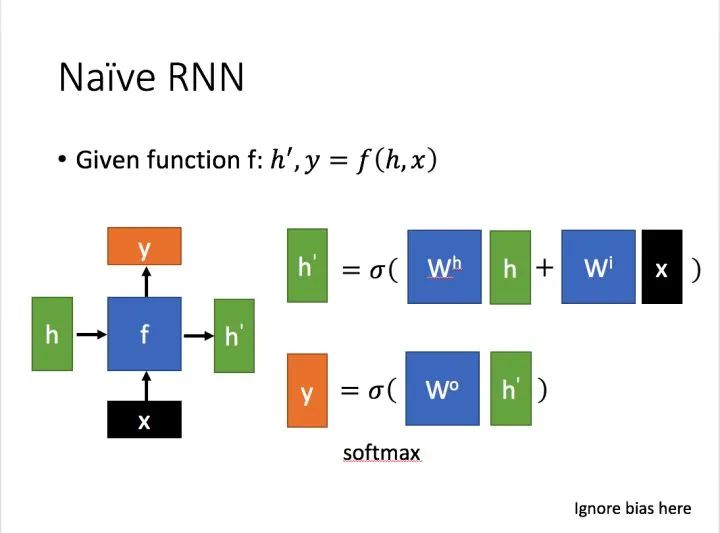
这里:
 为当前状态下数据的输入,
为当前状态下数据的输入,  表示接收到的上一个节点的输入。
表示接收到的上一个节点的输入。
 为当前节点状态下的输出,而
为当前节点状态下的输出,而  为传递到下一个节点的输出。
为传递到下一个节点的输出。
通过上图的公式可以看到,输出 h' 与 x 和 h 的值都相关。
而 y 则常常使用 h' 投入到一个线性层(主要是进行维度映射)然后使用softmax进行分类得到需要的数据。
对这里的y如何通过 h' 计算得到往往看具体模型的使用方式。
通过序列形式的输入,我们能够得到如下形式的RNN。

2. LSTM
2.1 什么是LSTM
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
LSTM结构(图右)和普通RNN的主要输入输出区别如下所示。
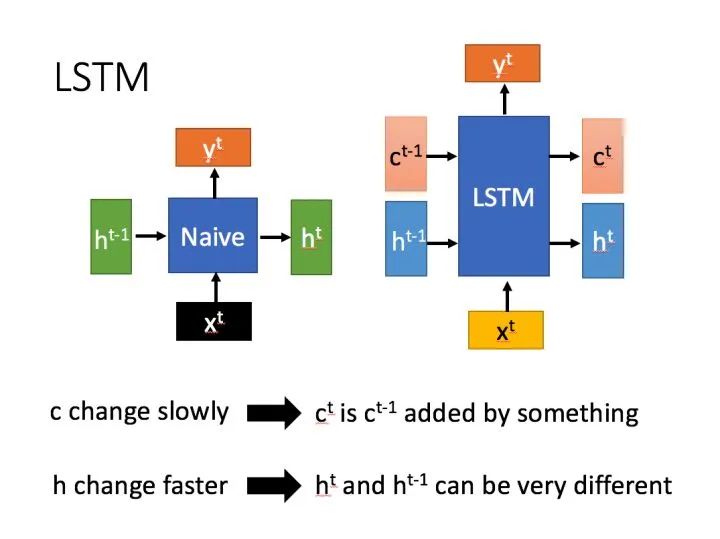
相比RNN只有一个传递状态  ,LSTM有两个传输状态,一个
,LSTM有两个传输状态,一个  (cell state),和一个 (hidden state)。(Tips:RNN中的 对于LSTM中的 )
(cell state),和一个 (hidden state)。(Tips:RNN中的 对于LSTM中的 )
其中对于传递下去的 改变得很慢,通常输出的 是上一个状态传过来的  加上一些数值。
加上一些数值。
而 则在不同节点下往往会有很大的区别。
2.2 深入LSTM结构
 和上一个状态传递下来的
和上一个状态传递下来的  拼接训练得到四个状态。
拼接训练得到四个状态。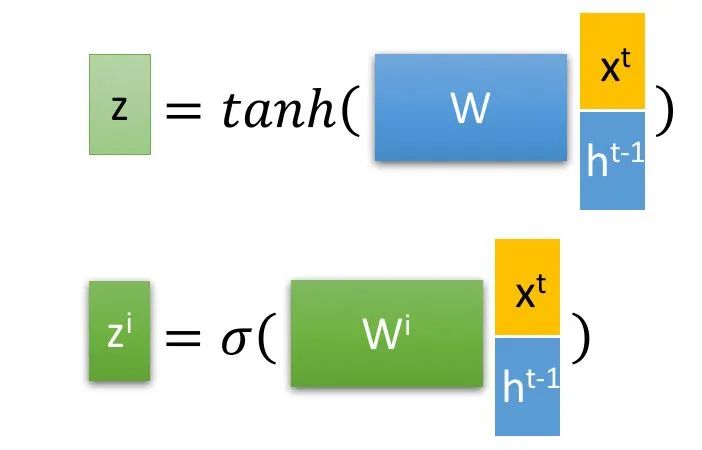
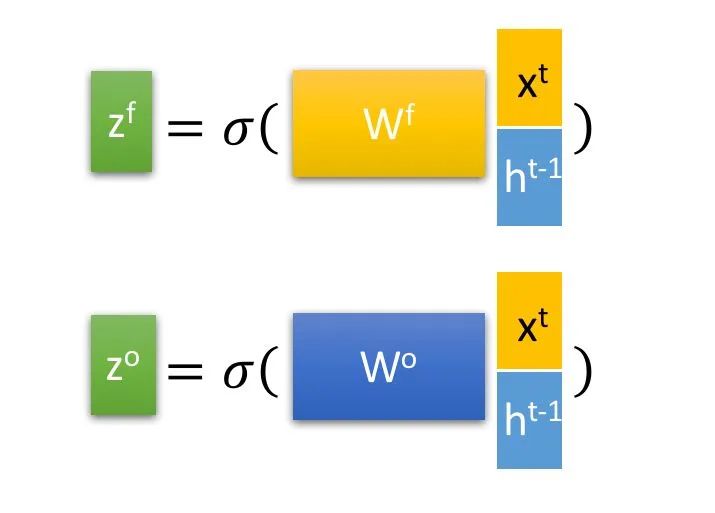
 ,
,  ,
, 是由拼接向量乘以权重矩阵之后,再通过一个
是由拼接向量乘以权重矩阵之后,再通过一个  激活函数转换成0到1之间的数值,来作为一种门控状态。而
激活函数转换成0到1之间的数值,来作为一种门控状态。而  则是将结果通过一个
则是将结果通过一个  激活函数将转换成-1到1之间的值(这里使用 是因为这里是将其做为输入数据,而不是门控信号)。
激活函数将转换成-1到1之间的值(这里使用 是因为这里是将其做为输入数据,而不是门控信号)。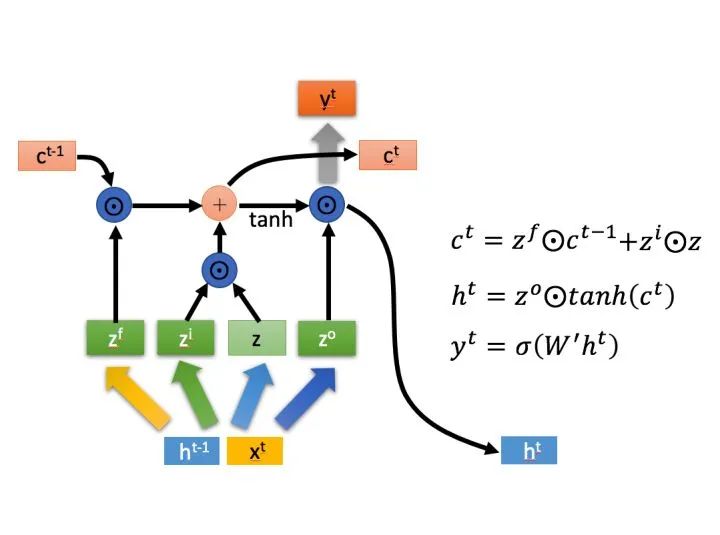
 是Hadamard Product,也就是操作矩阵中对应的元素相乘,因此要求两个相乘矩阵是同型的。
是Hadamard Product,也就是操作矩阵中对应的元素相乘,因此要求两个相乘矩阵是同型的。  则代表进行矩阵加法。 (f表示forget)来作为忘记门控,来控制上一个状态的 哪些需要留哪些需要忘。 进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的 表示。而选择的门控信号则是由 (i代表information)来进行控制。
则代表进行矩阵加法。 (f表示forget)来作为忘记门控,来控制上一个状态的 哪些需要留哪些需要忘。 进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的 表示。而选择的门控信号则是由 (i代表information)来进行控制。将上面两步得到的结果相加,即可得到传输给下一个状态的
3. 输出阶段。这个阶段将决定哪些将会被当成当前状态的输出。主要是通过 来进行控制的。并且还对上一阶段得到的  进行了放缩(通过一个tanh激活函数进行变化)。
进行了放缩(通过一个tanh激活函数进行变化)。
与普通RNN类似,输出  往往最终也是通过 变化得到。
往往最终也是通过 变化得到。
3. 总结
以上,就是LSTM的内部结构。通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息;而不像普通的RNN那样只能够“呆萌”地仅有一种记忆叠加方式。对很多需要“长期记忆”的任务来说,尤其好用。
但也因为引入了很多内容,导致参数变多,也使得训练难度加大了很多。因此很多时候我们往往会使用效果和LSTM相当但参数更少的GRU来构建大训练量的模型。
转自:AI有道