
强推 | 人人都能看懂的LSTM介绍及反向传播算法推导(非常详细)
↑↑↑点击上方蓝字,回复资料,10个G的惊喜

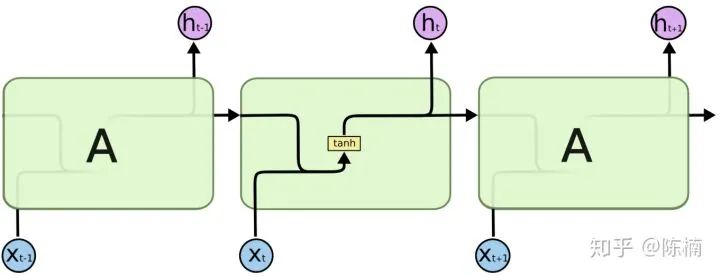
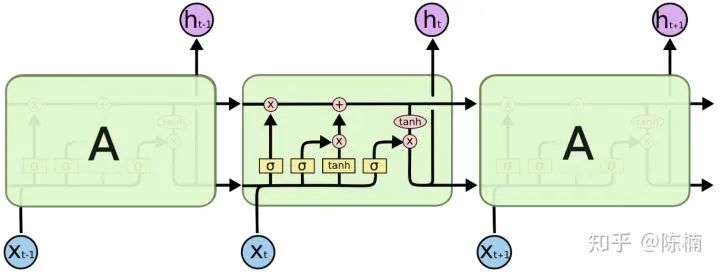

 和
和  ,并且对细胞状态
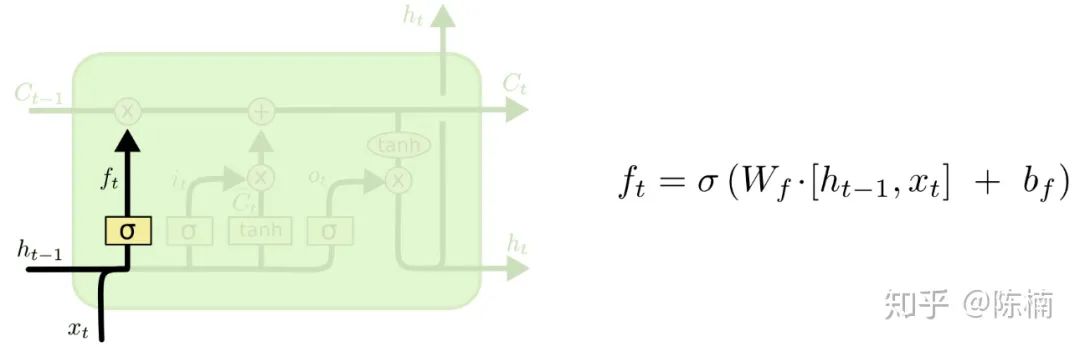
,并且对细胞状态  中的每一个数来说输出值都介于 0 和 1 之间。1 表示“完全接受这个”,0 表示“完全忽略这个”。
中的每一个数来说输出值都介于 0 和 1 之间。1 表示“完全接受这个”,0 表示“完全忽略这个”。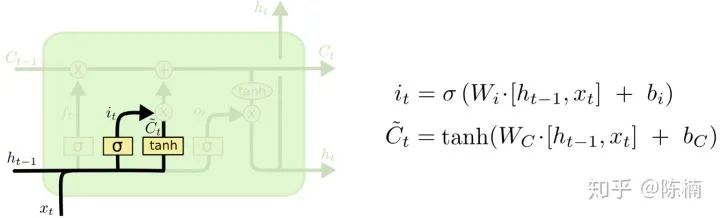
 形网络层创建一个新的备选值向量——
形网络层创建一个新的备选值向量——  ,可以用来添加到细胞状态。在下一步中我们将上面的两部分结合起来,产生对状态的更新。
,可以用来添加到细胞状态。在下一步中我们将上面的两部分结合起来,产生对状态的更新。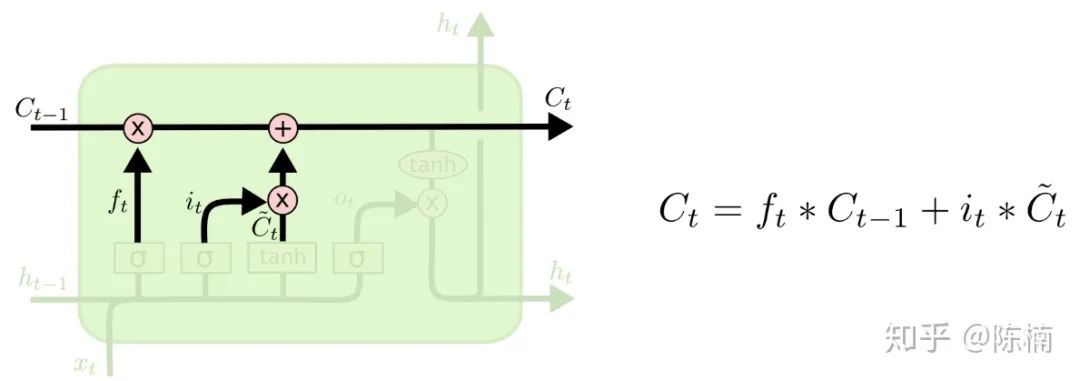 更新到
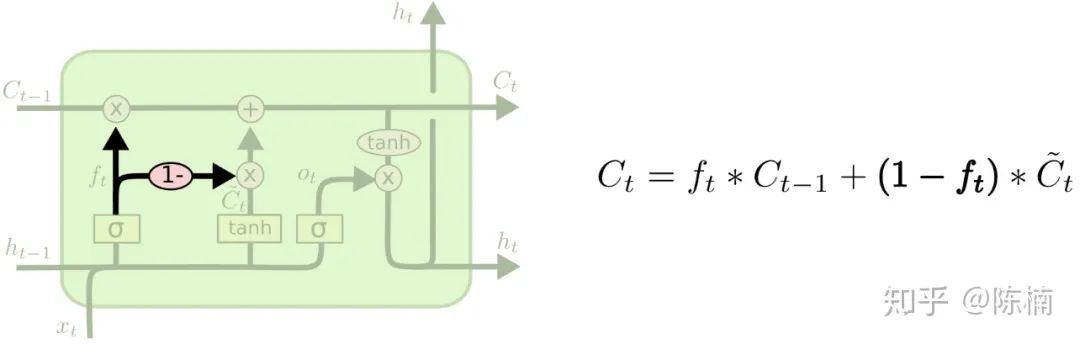
更新到  。先前的步骤已经决定要做什么,我们只需要照做就好。
。先前的步骤已经决定要做什么,我们只需要照做就好。 ,用来忘记我们决定忘记的事。然后我们加上
,用来忘记我们决定忘记的事。然后我们加上  ,这是新的候选值,根据我们对每个状态决定的更新值按比例进行缩放。
,这是新的候选值,根据我们对每个状态决定的更新值按比例进行缩放。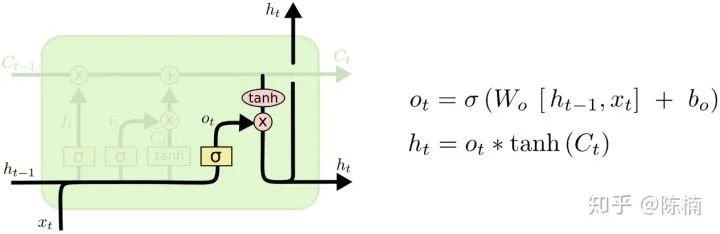
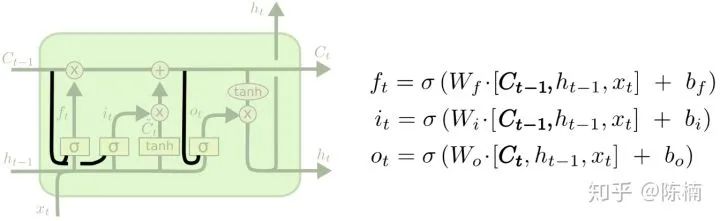
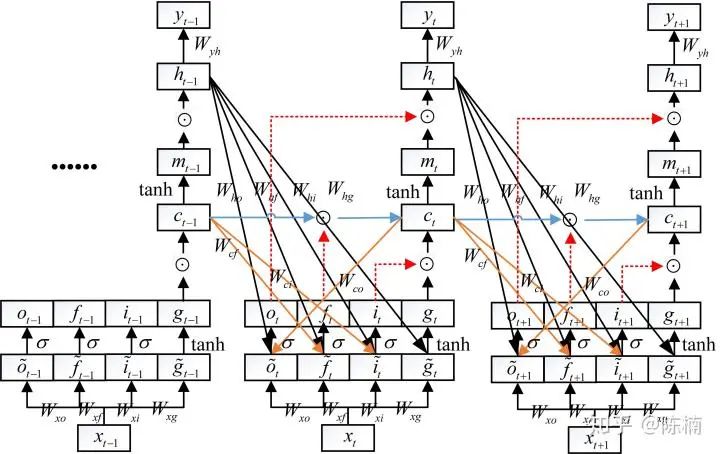

 ,求某个节点梯度时,首先应该找到该节点的输出节点,然后分别计算所有输出节点的梯度乘以输出节点对该节点的梯度,最后相加即可得到该节点的梯度。如计算
,求某个节点梯度时,首先应该找到该节点的输出节点,然后分别计算所有输出节点的梯度乘以输出节点对该节点的梯度,最后相加即可得到该节点的梯度。如计算  时,找到
时,找到  节点的所有输出节点
节点的所有输出节点 

 ,然后分别计算输出节点的梯度(如
,然后分别计算输出节点的梯度(如  )与输出节点对 的梯度的乘积(如
)与输出节点对 的梯度的乘积(如  ),最后相加即可得到节点 的梯度:
),最后相加即可得到节点 的梯度:


 和重置门
和重置门  ,如下图所示。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多;重置门控制前一时刻状态有多少信息被写入到当前的候选集
,如下图所示。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多;重置门控制前一时刻状态有多少信息被写入到当前的候选集  上,重置门越小,前一状态的信息被写入的越少。这样做使得 GRU 比标准的 LSTM 模型更简单,因此正在变得流行起来。
上,重置门越小,前一状态的信息被写入的越少。这样做使得 GRU 比标准的 LSTM 模型更简单,因此正在变得流行起来。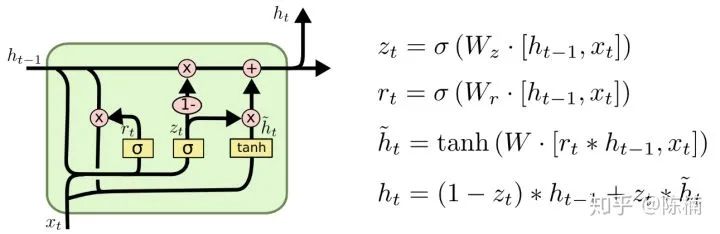
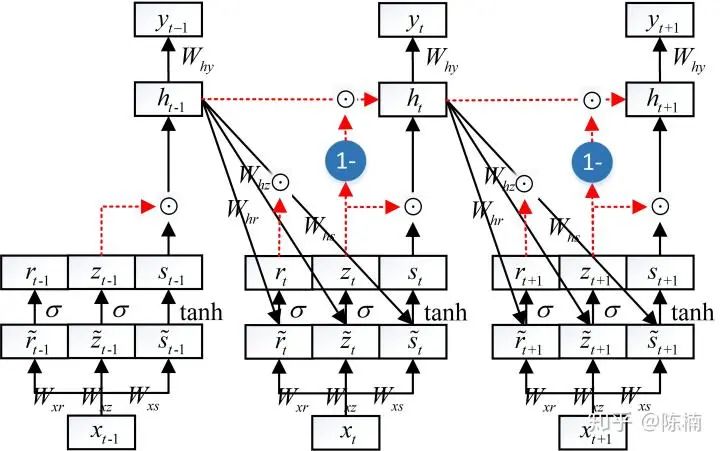



参考资料:【翻译】理解 LSTM 网络 - xuruilong100 - 博客园

老铁,三连支持一下,好吗?↓↓↓
评论