Django提速手册:为Django应用提速
英文原文:https://openfolder.sh/django-faster-speed-tutorial
译者:桃夭
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包

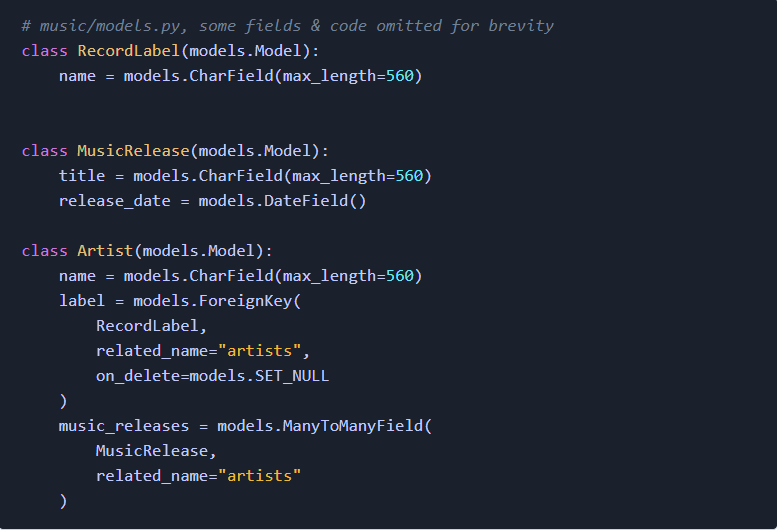





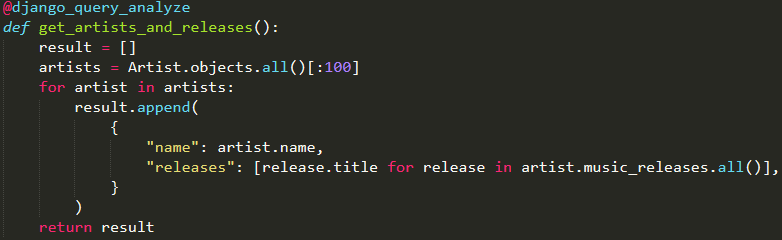


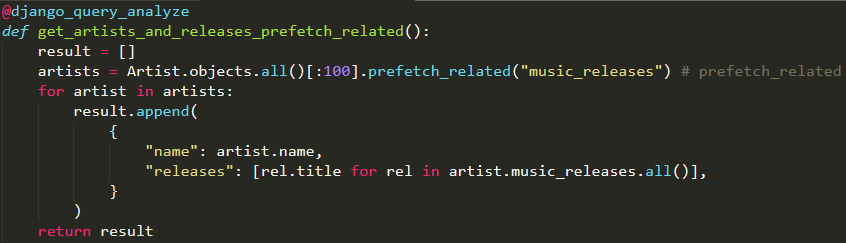

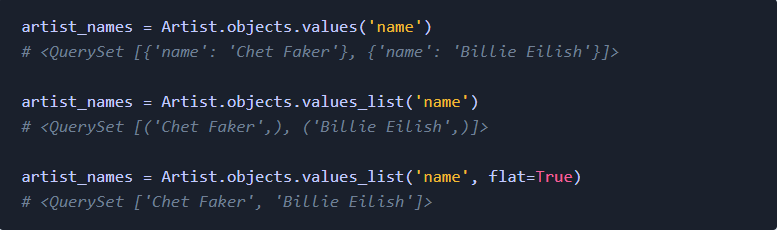






















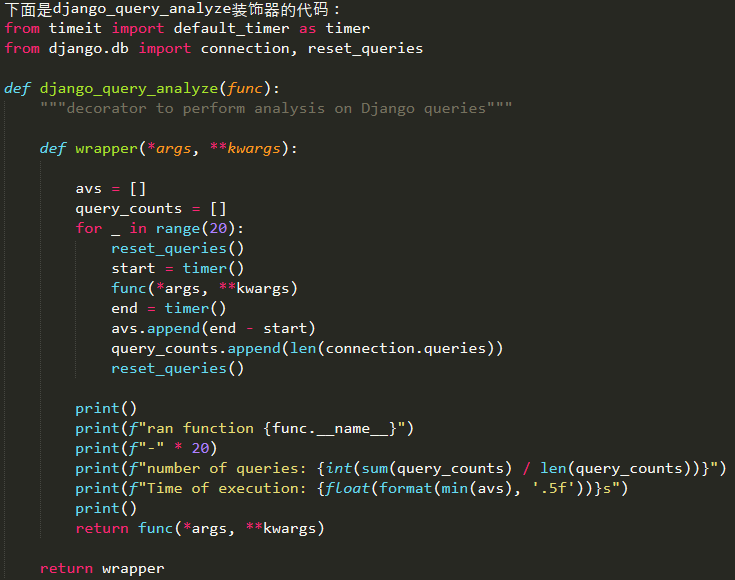
推荐阅读
点分享 点收藏 点点赞 点在看




评论
 下载APP
下载APP
英文原文:https://openfolder.sh/django-faster-speed-tutorial
译者:桃夭
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
推荐阅读
点分享 点收藏 点点赞 点在看