
【多模态】详解:多模态知识图谱种类及其应用
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


知识图谱技术已经被广泛用于处理结构化数据(采用本体+D2R技术)和文本数据(采用文本信息抽取技术),但是还有一类非结构化数据,即视觉数据,则相对关注度较低,而且相缺乏有效的技术手段来从这些数据中提取结构化知识。最近几年,虽然有一些多模态视觉技术提出,这些技术主要还是为了提升图像分类、图像生成、图像问答的效果,不能很好地支撑多模态知识图谱的构建。视觉数据库通常是图像或视频数据的丰富来源,并提供关于知识图谱中实体的充分视觉信息。显然,如果可以在在更大范围内进行链接预测和实体对齐,进而进行实体关系抽取,可以使现有的模型在综合考虑文本和视觉特征时获得更好的性能,这也是我们研究多模态知识图谱(multi-modal knowledge graph)的意义所在。
目前,已经有很多开放知识图谱(见https://lod-cloud.net/和http://www.openkg.cn/),而且不少企业也有自己的企业知识图谱。然而,这些知识图谱很少有可视化的数据资源。图1所示为多模态知识图谱的发展过程。
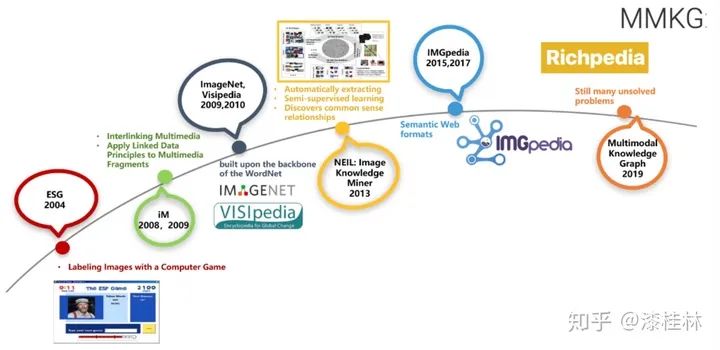
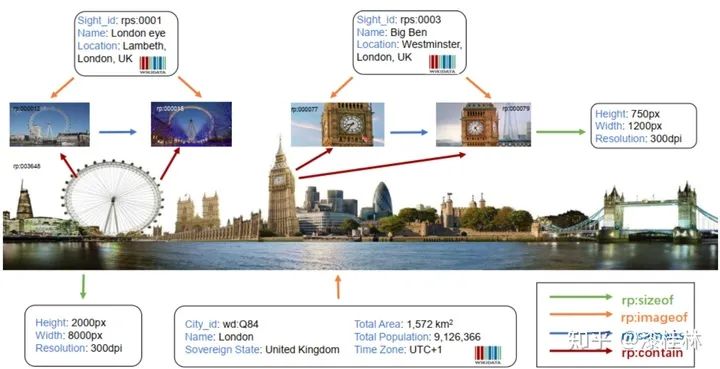
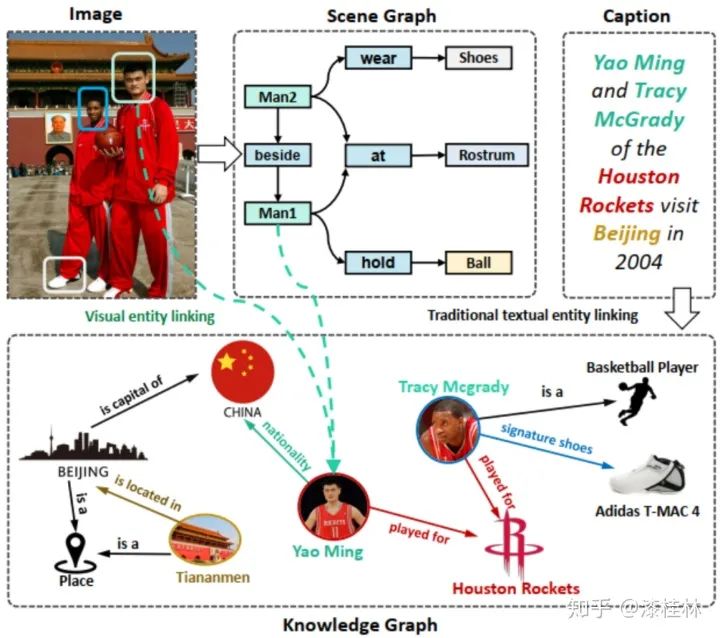
多模态知识图谱与传统知识图谱的主要区别是,传统知识图谱主要集中研究文本和数据库的实体和关系,而多模态知识图谱则在传统知识图谱的基础上,构建了多种模态(例如视觉模态)下的实体,以及多种模态实体间的多模态语义关系。例如在最新的一个多模态百科图谱Richpedia中(如下图2所示)[5],首先构建了图像模态伦敦眼图像与文本模态知识图谱实体(DBpedia实体:London eye)之间的多模态语义关系(rpo:imageof),之后还构建了图像模态实体伦敦眼与图像模态实体大本钟之间的多模态语义关系(rpo:nextTo)。
一、多模态知识图谱相关工作
随着人工智能技术的不断发展,知识图谱作为人工智能领域的知识支柱,以其强大的知识表示和推理能力受到学术界和产业界的广泛关注。近年来,知识图谱在语义搜索、问答、知识管理等领域得到了广泛的应用。其中在描述多媒体的可用数据集中,现有的工作重点是捕获多媒体文件的高级元数据(如作者、创建日期、文件大小、清晰度、持续时间),而不是多媒体内容本身的音频或视觉特性。以下会介绍几个重要的开源多模态知识图谱:
1.DBpedia[1]
DBpedia作为近十年来语义网研究的中心领域,其丰富的语义信息也将会成为今后多模态知识图谱的链接端点,其完整的本体结构对于构建多模态知识图谱提供了很大的便利。DBpedia项目是一个社区项目,旨在从维基百科中提取结构化信息,并使其可在网络上访问。DBpedia知识库目前描述了超过260万个实体。对于每个实体,DBpedia定义了一个唯一的全局标识符,可以将其解引用为网络上一个RDF描述的实体。DBpedia提供了30种人类可读的语言版本,与其他资源形成关系。在过去的几年里,越来越多的数据发布者开始建立数据集链接到DBpedia资源,使DBpedia成为一个新的数据web互联中心。目前,围绕DBpedia的互联网数据源网络提供了约47亿条信息,涵盖地理信息、人、公司、电影、音乐、基因、药物、图书、科技出版社等领域。
2.Wikidata[2]
Wikidata中也存在大量的多模态资源,Wikidata是维基媒体基金会(WMF)联合策划的一个知识图谱,是维基媒体数据管理策略的核心项目。充分利用Wikidata的资源,主要挑战之一是提供可靠并且强大的数据共享查询服务,维基媒体基金会选择使用语义技术。活动的SPARQL端点、常规的RDF转储和链接的数据api是目前Wikidata的核心技术,Wikidata的目标是通过创造维基百科全球管理数据的新方法来克服数据不一致性。Wikidata的主要成就包括:Wikidata提供了一个可由所有人共享的免费协作知识库;Wikidata已经成为维基媒体最活跃的项目之一;越来越多的网站在浏览页面时都从Wikidata获取内容,以增加大数据的可见性和实用性。
3.IMGpedia[3]
IMGpedia是一个大型的链接数据集,它从Wikimedia Commons数据集中的图像中收集大量的可视化信息。它构建并生成了1500万个视觉内容描述符,图像之间有4.5亿个视觉相似关系,此外,在IMGpedia中单个图像与DBpedia之间还有链接。IMGpedia旨在从维基百科发布的图片中提取相关的视觉信息,从Wikimedia中收集所有术语和所有多模态数据(包括作者、日期、大小等)的图像,并为每张图像生成相应的图像描述符。链接数据很少考虑多模态数据,但多模态数据也是语义网络的重要组成部分。为了探索链接数据和多模态数据的结合,构建了IMGpedia,计算Wikipedia条目中使用的图像描述符,然后将这些图像及其描述与百科知识图谱链接起来。
IMGpedia是一个多模态知识图谱的先例。将语义知识图谱与多模态数据相结合,面对多种任务下的挑战和机遇。IMGpedia使用四种图像描述符进行基准测试,这些描述符的引用和实现是公开的。IMGpedia提供了Wikidata的链接。由于DBpedia中的分类对一些可视化语义查询不方便,所以IMGpedia旨在提供一个更好的语义查询平台。IMGpedia在多模态方向上是一个很好的先例,但也存在一些问题,比如关系类型稀疏,关系数量少,图像分类不清晰等,也是之后需要集中解决的问题。
4.MMKG[4]
MMKG主要用于联合不同知识图谱中的不同实体和图像执行关系推理,MMKG是一个包含所有实体的数字特征和(链接到)图像的三个知识图谱的集合,以及对知识图谱之间的实体对齐。因此,多关系链接预测和实体匹配社区可以从该资源中受益。MMKG有潜力促进知识图谱的新型多模态学习方法的发展,作者通过大量的实验验证了MMKG在同一链路预测任务中的有效性。
MMKG选择在知识图谱补全文献中广泛使用的数据集FREEBASE-15K (FB15K)作为创建多模态知识图谱的起点。知识图谱三元组是基于N-Triples格式的,这是一种用于编码RDF图的基于行的纯文本格式。MMKG同时也创建了基于DBpedia和YAGO的版本,称为DBpedia-15K(DB15K)和YAGO15K,通过将FB15K中的实体与其他知识图谱中的实体对齐。其中对于基于DBpedia的版本,主要构建了sameAs关系,为了创建DB15K,提取了FB15K和DBpedia实体之间的对齐,通过sameAs关系链接FB15K和DBpedia中的对齐实体;构建关系图谱,来自FB15K的很大比例的实体可以与DBpedia中的实体对齐。但是,为了使这两个知识图谱拥有大致相同数量的实体,并且拥有不能跨知识图谱对齐的实体,在DB15K中包括了额外的实体;构建图像关系,MMKG从三大搜索引擎中获取相应文本实体的图像实体,生成对应的文本-图像关系。但是,它是专门为文本知识图谱的完成而构建的,主要针对小数据集(FB15K, DBPEDIA15K, YAGO15K)。MMKG在将图像分发给相关文本实体时也没有考虑图像的多样性。
二、基于百科多模态知识图谱Richpedia
虽说之前的一些工作如IMGpedia和MMKG融合了多模态的知识,构建了多模态知识图谱,但其中也存在一些问题,例如在IMGpedia中关系类型稀疏,关系数量少,图像分类不清晰等,在MMKG中图像并没有作为单独的图像实体存在,而是依赖于相应的传统文本实体。这些问题对于多模态任务的发展有着较大制约,东南大学认知智能研究所基于解决如上存在的问题的动机,提出了多模态知识图谱Richpedia[5]。
Richpedia多模态知识图谱的定义如下:实体集合E包括文本知识图谱实体EKG和图像实体EIM,R表示一系列关系的集合,其中E和R利用统一资源标识符(IRIs)表示。L是文字的集合(例如:“伦敦”,“750px”),B表示为一系列的空白节点。Richpedia三元组t表示格式为<subject, predicate, object>,是(E∪B)×R×(E∪L∪B),Richpedia多模态知识图谱是Richpedia三元组的集合。
在构建多模态知识图谱中,总体模型如图3所示。接下来我们会逐步介绍构建Richpedia的流程。
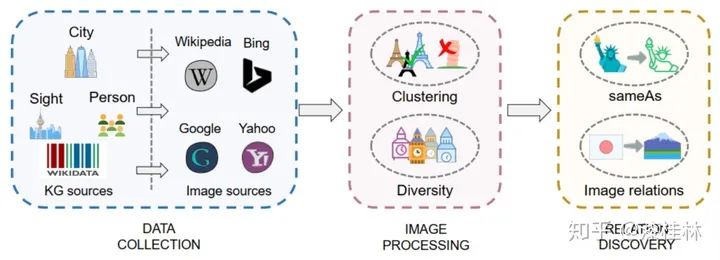
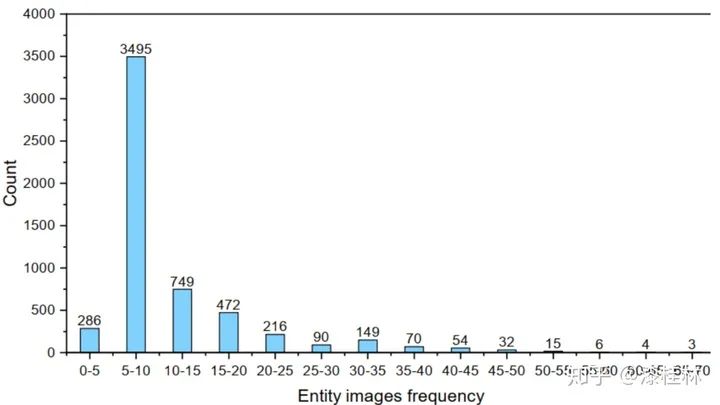
与一般的文本知识图谱不同,Richpedia的出发点是构造一个多模态知识图谱,其中包含了全面的图像实体及其之间的关系。但是,如图4所示,文本知识图谱实体的图像资源有很大一部分是长尾分布。换句话说,平均每一个文本知识图谱实体在Wikipedia中只有很少的视觉信息。因此,我们考虑借助外部来源来填充Richpedia,首先我们基于现有的传统文本实体,从维基百科,谷歌,必应和雅虎四大图像搜索引擎中获取相应的图像实体,每一个图像作为知识图谱中的一个实体存储于Richpedia中。Wikidata已经为每个文本知识图谱实体定义了唯一的统一资源标识符,我们将这些统一资源标识符添加到Richpedia作为文本知识图谱实体。在目前的版本中,我们主要收集了30,638个关于城市、景点和名人的实体。对于图像实体,我们可以直观地从Wikipedia上收集图像,然后在Richpedia中创建相应的统一资源标识符。
在收集完图像实体之后,我们需要对图像实体进行预处理和筛选。因为我们的数据来自于开放资源,它们会被搜索引擎基于与查询字段的相关性评分进行排名。从多模态知识图谱的角度而言,文本知识图谱实体所包含的图像实体不仅要相关性高而且还要具有多样性,如图5所示,对于中间的图像实体,右侧的图像实体因为较高的相似性从而被系统过滤掉,保留左侧相似性较低的图像实体。因为从搜索引擎中获取的图像实体难免存在重复问题,接下来我们通过一系列的预处理操作,使得每个图像实体都与相应的传统文本实体具有较高的相关度。其中预处理操作包括去噪操作和多样性检测,去噪操作的目的是去除不相关的图像实体,多样性检测的目的是使得图像实体具有尽可能高的多样性。

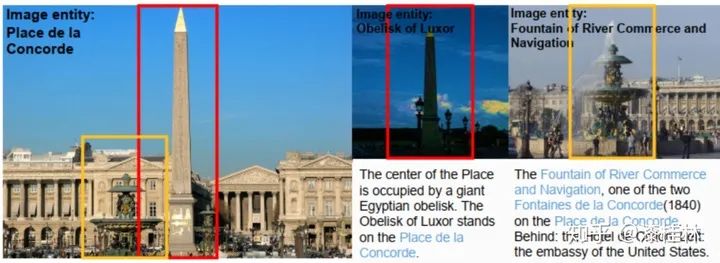
因为很难基于不同图像的像素特征直接检测出这些语义关系,所以我们利用基于规则的关系抽取模板,借助Wikipedia图像描述中的超链接信息,生成图像实体间的多模态语义关系。在图6中,我们以rpo:contain和rpo:nearBy为例说明如何发现协和广场,卢克索方尖碑和航运喷泉图像实体间的语义关系。如图6所示,我们在中文维基百科中协和广场词条中获取到包含卢克索方尖碑和航运喷泉的图像实体,从语义视觉关系的角度上看,协和广场包括了卢克索方尖碑和航运喷泉,卢克索方尖碑就在航运喷泉的旁边。为了发现这些关系,我们收集这些图像的文本描述,并提出三个有效的规则来提取多模态语义关系:
规则1. 如果在描述中有一个超链接,其指向的对应Wikipedia实体的概率很高。我们利用Stanford CoreNLP检测描述中的关键字。然后,通过字符串映射算法发现预定义关系。例如,如果我们在两个实体之间的文本描述中得到单词‘left’,我们将得到‘nearBy’关系。
规则2. 如果描述中有多个超链接,我们基于语法分析器和语法树检测核心知识图谱实体(即描述的主体)。然后,我们以核心知识图谱实体作为输入,将这种情况简化为规则1。
规则3. 如果在描述中没有指向其他词条的超链接,我们使用Stanford CoreNLP来查找描述中包含的Wikipedia知识图谱实体,并将这种情况简化为规则1和规则2。因为规则3依赖于NER结果,准确率低于相应的预标注超链接信息,所以它的优先级低于前两个规则。
三、基于Richpedia的多模态知识服务网站
Richpedia网站(http://rich.wangmengsd.com/)是为Richpedia多模态知识图谱开发的一个网站,其提供了对Richpedia数据库的介绍,查询,资源检索,使用教程以及数据下载服务。其中包括:
a) Homepage:主要对Richpedia数据库进行了概述。
b) Download:提供了image文件和三元组关系N-Triples文件的下载链接。

c) SPARQL:实现了对Richpedia数据库中的实体和视觉关系的SPARQL查询。
d) Query:提供了对地名和人物的直接查询相关图片功能。

e) Tutorial:提供了网站的使用教程。
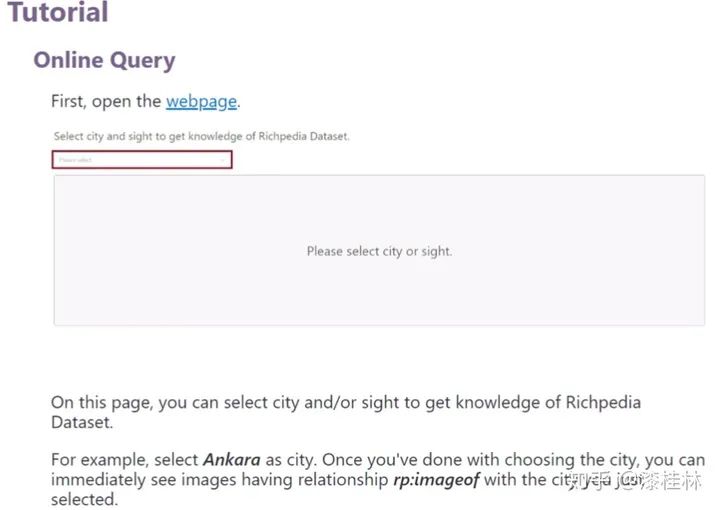
首先,我们可以在Richpedia中查询实体信息,包括图像实体实体和文本知识图谱实体。第一步是选择查询的实体类别,然后选择要具体查询的实体。例如,如果我们要查询安卡拉城市实体的文本知识图谱实体和图像实体,可以在下拉选择器中选择对应的安卡拉城市标签。之后出现的页面中上半部分是安卡拉的文本知识图谱实体,下半部分是安卡拉的图像实体。
其次,我们可以通过Richpedia的在线访问平台查询图像实体之间的视觉语义关系。选择查询文本知识图谱实体后,点击对应的图像实体,可以查看图像实体的视觉语义关系。例如,当我们想查询一个与北京动物园图像实体具有rpo:sameAs关系的图像实体时,我们可以点击相应的北京动物园图像实体,得到相应的结果。
f) Ontology:提供了Ontology的相关信息。

g) Resource:提供了对所有图片资源的访问地址。
h) Github链接以及页面底端:提供了friendly link,联系人邮箱,Github主页以及分享协议。
四、多模态知识图谱应用
多模态知识图谱的应用场景十分广泛,首先一个完备的多模态知识图谱会极大地帮助现有自然语言处理和计算机视觉等领域的发展,同时对于跨领域的融合研究也会有极大的帮助,多模态结构数据虽然在底层表征上是异构的,但是相同实体的不同模态数据在高层语义上是统一的,所以多种模态数据的融合有利于推进语言表示等模型的发展,对于在语义层级构建多种模态下统一的语言表示模型提出数据支持。其次多模态知识图谱技术可以服务于各种下游领域,例如多模态实体链接技术可以融合多种模态下的相同实体,可以广泛应用于新闻阅读,时事推荐,明星同款等场景中如图14,多模态知识图谱补全技术可以通过远程监督补全多模态知识图谱,完善现有的多模态知识图谱,利用动态更新技术使其更加的完备,多模态对话系统的应用就更加的广泛,现阶段电商领域中集成图像和文本的多模态对话系统的研究蒸蒸日上,多模态对话系统对于电商推荐,商品问答领域的进步有着重大的推进作用。
多模态知识图谱是一个新兴领域,受益于近些年通讯技术的发展,多模态数据越来越成为人们生活中触手可及的信息,种种多模态技术也成为当下研究的热门方向。
参考文献
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!