
2020第二届厦门国际银行数创金融杯建模大赛冠军方案
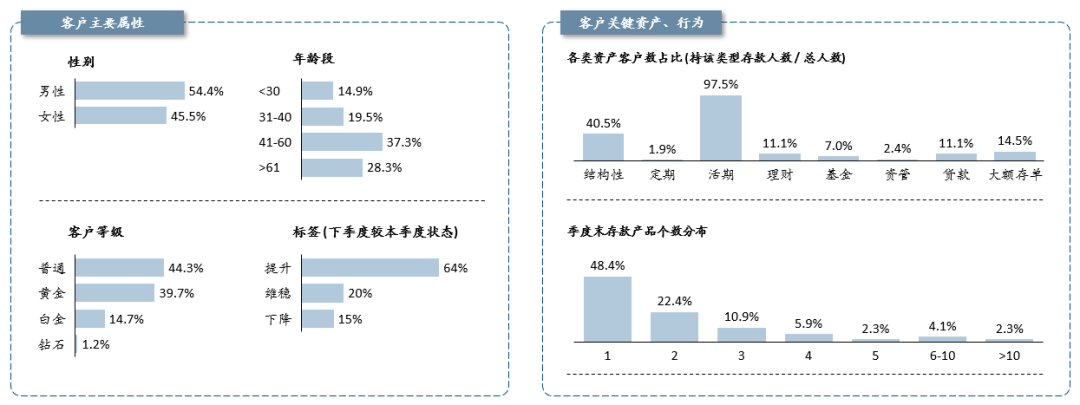
1.客群中主要以41-60的中年人为主,高等级的白金与钻石客户占了总体的约15%,3个需预存的标签类别中,提升人群高达64%,最少的是下降人群,占15%;
拥有活期存款的客户占比最大,为总体的97.5%,其次为结构性存款,占40.5%;占比最少的是资管与定期类产品,分别占总客户数的2.4%与1.9%。
季度末存款产品个数主要以1-2个为主,约占70%。
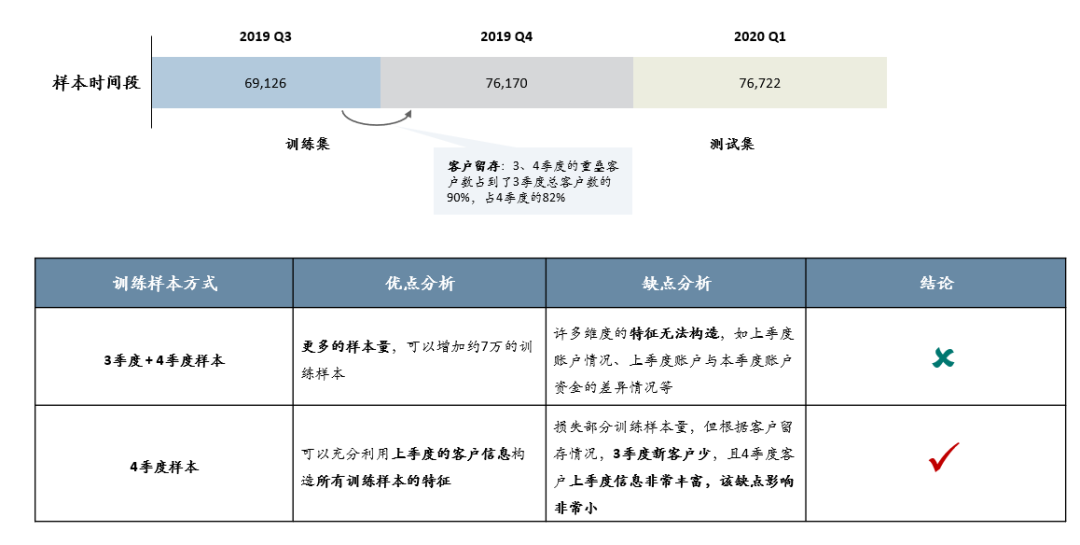
若线下训练时将3 季度的样本包含在内,3 季度样本会有相当大一部分特征无法构造,如客户上季度的资金、特征情况、上季度与当前季度差异等。
若线下训练不包含3 季度样本,则会损失一些训练样本,而优势是4、1季度样本特征可以都包含客户上季度的特征情况。
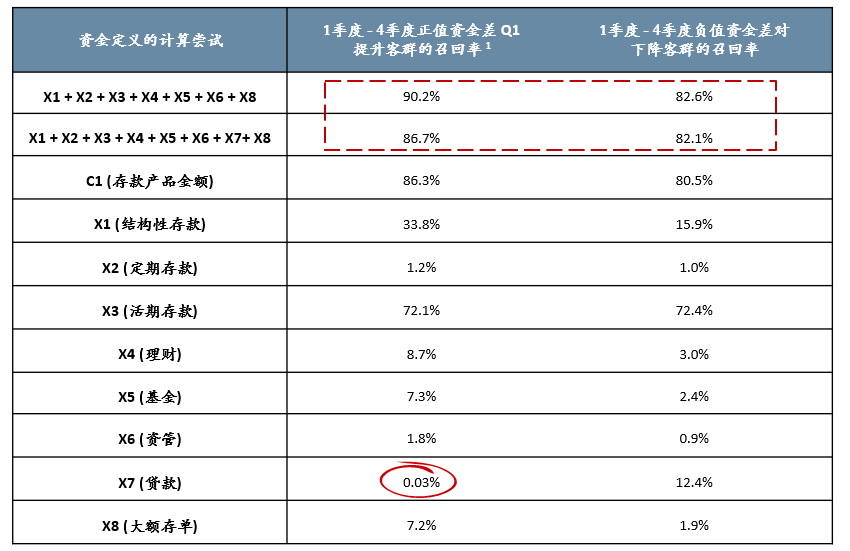
计算尝试的结果非常符合业务逻辑:定义中的“资金”一词,最接近的是客户X1-X8的资产加和(且去除X7),即客户账户中所有正向资金的加和;
另一方面,经分析,贷款金额初步可以认定对于客户趋向于提升客群是起反作用的;
基于以上发现,后续构造特征时,优先构造最接近标签定义的特征,即优先构造正向总金额类的特征,且需与贷款金额作区分,从而避免构造冗余特征,使模型波动太大。
特征值必须在不同样本间公平可比这一思想,在构造客户各类统计特征时需要使用滑动窗口的方法
所构造特征不能引入未来信息,造成信息泄露;可以辅助PSI等特征稳定性指标评估所构造的特征组
构造特征时,尽可能以总金额代替各类子金额,使特征的信息更全面、泛化




多分类模型对于每一个样本,都会给出各个类别的概率,在预测时,通常直接选取概率最大的那个类别作为模型对样本的预测类别;而对于kappa 评估指标,后处理的优化空间是,给3 个类别的概率不同权重,找到加权后的最大概率值,作为样本的预测类别,从而使得Out of fold 整体样本的kappa 结果最优。那么如何寻找3 个类别各自的概率权重,成为了后处理的关键。
我们认为,后处理必须以线下Out of fold 为依据;
后处理存在着一定不稳定性,必须在构造特征完后,再进行该部操作,不能以后处理结果作为新特征组的好坏判断依据;
单次对Out of fold 整体样本的权重搜索,可能存在过拟合的问题,为了更为泛化,尝试使用在每折中各自搜索权重,并将5 次权重取平均,作为泛化后的3 个类别的权重。
——END——