
Hadoop重点难点:可靠性/Failover/Shuffle
你需要先看这个系列:
HDFS – 可靠性
HDFS 的可靠性主要有一下几点:
冗余副本策略 机架策略 心跳机制 安全模式 效验和 回收站 元数据保护 快照机制
1.冗余副本策略
可以在 hdfs-site.xml 中设置复制因子指定副本数量 所有数据块都可副本 DataNode 启动时,遍历本地文件系统,产生一份 HDFS 数据块和本地文件的对应关系列表 (blockreport) 汇报给 Namenode
2.机架策略
HDFS 的”机架感知”,通过节点之间发送一个数据包,来感应它们是否在同一个机架 一般在本机架放一个副本,在其他机架再存放一个副本,这样可以防止机架失效时丢失数据,也可以提高带宽利用率
3.心跳机制
NameNode 周期性从 DataNode 接受心跳信息和块报告 NameNode 根据快报告验证元数据 没有按时发送心跳的 DataNode 会被标记为宕机,不会再给他任何 I/O 请求 如果 DataNode 失效造成副本数量下降,并且低于预先设定的值,NameNode 会检测出这些数据库,并在合适的时机从新复制 引发重新复制的原因还包括数据副本本身损坏,磁盘错误,复制因子被增大等
4.安全模式
NameNode 启动时会先经过一个 “安全模式” 阶段 安全模式阶段不会产生数据写 在此阶段 NameNode 收集各个 DataNode 的报告, 当数据块达到最小副本数以上时,会被认为是”安全”的 在一定比例(可设置) 的数据块被确定为”安全” 后 ,在过若干时间,安全模式结束 当检测到副本数不足的数据块是,该块会被复制,直到达到最小副本数
5.checksum
在文件创立时,每个数据块都产生checksum checksum会作为单独一个隐藏文件保存在命名空间下 客户端获取数据时可以检查checksum是否相同,从而发现数据块是否损坏 如果正在读取的数据块损坏,则可以继续读取其他副本
6.回收站
删除文件时,其实是放入回收站 /trash 回收站里的文件是可以快速恢复的 可以设置一个时间值,当回收站里文件的存放时间超过了这个值,就被彻底删除,并且释放占用的数据块
7.元数据保护
映像文件和事物日志是 NameNode 的核心数据.可以配置为拥有多个副本 副本会降低 NameNode 的处理速度,但增加安全性 NameNode 依然是单点,如果发生故障要手工切换
YARN – Failover
失败类型
程序问题 进程崩溃 硬件问题
失败处理
任务失败
运行时异常或者JVM退出都会报告给ApplicationMaster 通过心跳来检查挂住的任务(timeout),会检查多次(可配置)才判断该任务是否失效 一个作业的任务失败率超过配置,则认为该作业失败 失败的任务或作业都会有ApplicationMaster重新运行
ApplicationMaster失败
ApplicationMaster定时发送心跳信号到ResourceManager,通常一旦ApplicationMaster失败,则认为失败,但也可以通过配置多次后才失败 一旦ApplicationMaster失败,ResourceManager会启动一个新的ApplicationMaster 新的ApplicationMaster负责恢复之前错误的ApplicationMaster的状态(yarn.app.mapreduce.am.job.recovery.enable=true),这一步是通过将应用运行状态保存到共享的存储上来实现的,ResourceManager不会负责任务状态的保存和恢复 Client也会定时向ApplicationMaster查询进度和状态,一旦发现其失败,则向ResouceManager询问新的ApplicationMaster
NodeManager失败
NodeManager定时发送心跳到ResourceManager,如果超过一段时间没有收到心跳消息,ResourceManager就会将其移除 任何运行在该NodeManager上的任务和ApplicationMaster都会在其他NodeManager上进行恢复 如果某个NodeManager失败的次数太多,ApplicationMaster会将其加入黑名单(ResourceManager没有),任务调度时不在其上运行任务
ResourceManager失败
通过checkpoint机制,定时将其状态保存到磁盘,然后失败的时候,重新运行 通过zookeeper同步状态和实现透明的HA 可以看出,一般的错误处理都是由当前模块的父模块进行监控(心跳)和恢复。而最顶端的模块则通过定时保存、同步状态和zookeeper来ֹ实现HA
Hadoop Shuffle
MapReduce – Shuffle
对Map的结果进行排序并传输到Reduce进行处理 Map的结果并不是直接存放到硬盘,而是利用缓存做一些预排序处理 Map会调用Combiner,压缩,按key进行分区、排序等,尽量减少结果的大小 每个Map完成后都会通知Task,然后Reduce就可以进行处理。
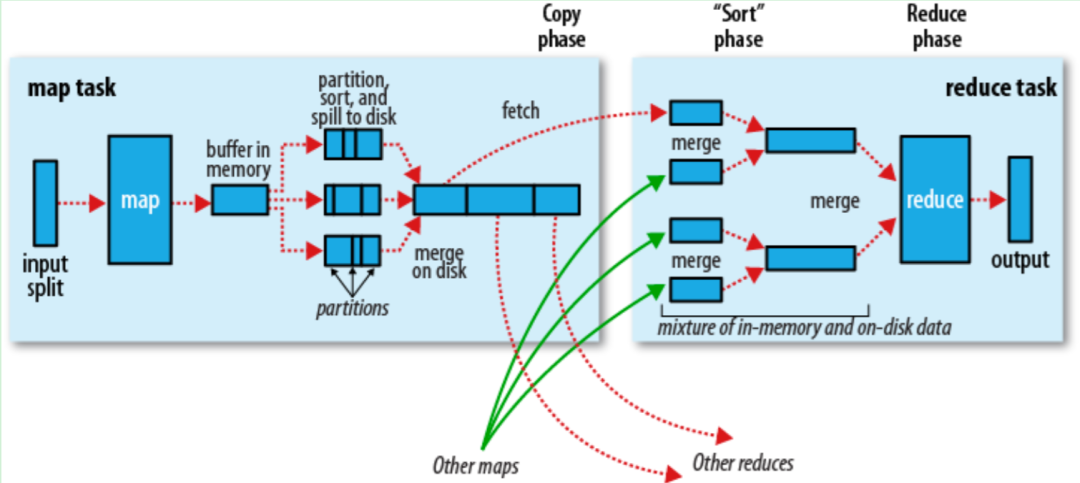
Map端
当Map程序开始产生结果的时候,并不是直接写到文件的,而是利用缓存做一些排序方面的预处理操作 每个Map任务都有一个循环内存缓冲区(默认100MB),当缓存的内容达到80%时,后台线程开始将内容写到文件,此时Map任务可以继续输出结果,但如果缓冲区满了,Map任务则需要等待 写文件使用round-robin方式。在写入文件之前,先将数据按照Reduce进行分区。对于每一个分区,都会在内存中根据key进行排序,如果配置了Combiner,则排序后执行Combiner(Combine之后可以减少写入文件和传输的数据) 每次结果达到缓冲区的阀值时,都会创建一个文件,在Map结束时,可能会产生大量的文件。在Map完成前,会将这些文件进行合并和排序。如果文件的数量超过3个,则合并后会再次运行Combiner(1、2个文件就没有必要了) 如果配置了压缩,则最终写入的文件会先进行压缩,这样可以减少写入和传输的数据 一旦Map完成,则通知任务管理器,此时Reduce就可以开始复制结果数据
Reduce端
Map的结果文件都存放到运行Map任务的机器的本地硬盘中 如果Map的结果很少,则直接放到内存,否则写入文件中 同时后台线程将这些文件进行合并和排序到一个更大的文件中(如果文件是压缩的,则需要先解压) 当所有的Map结果都被复制和合并后,就会调用Reduce方法 Reduce结果会写入到HDFS中
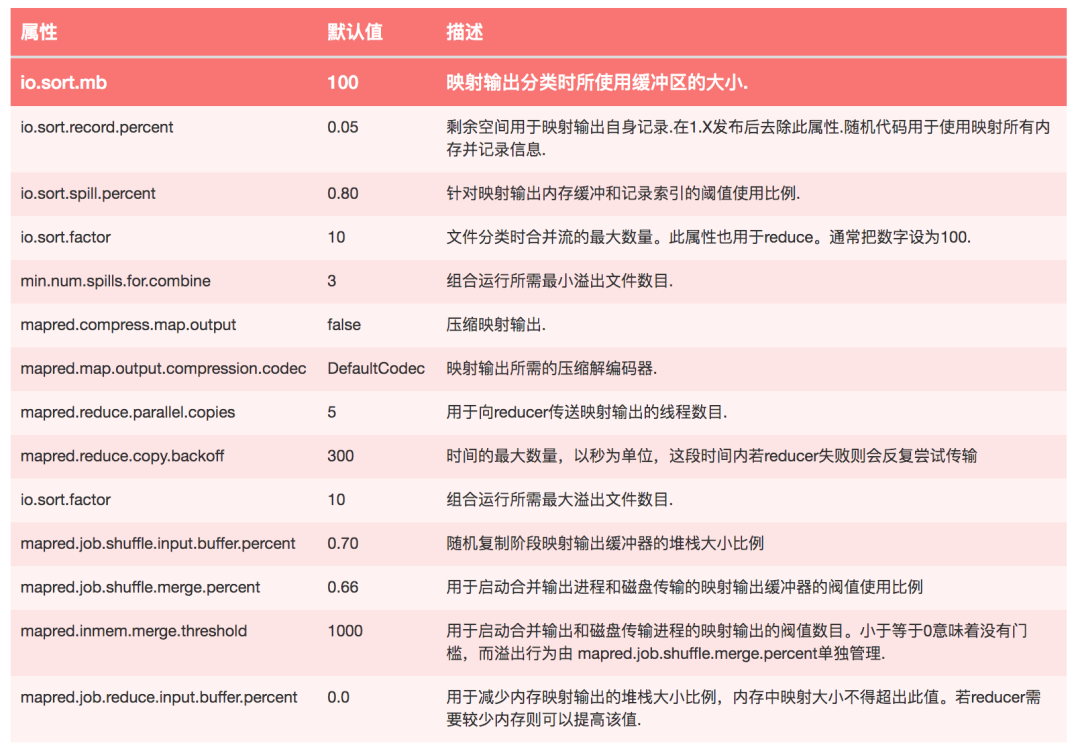
调优
一般的原则是给shuffle分配尽可能多的内存,但前提是要保证Map、Reduce任务有足够的内存 对于Map,主要就是避免把文件写入磁盘,例如使用Combiner,增大io.sort.mb的值 对于Reduce,主要是把Map的结果尽可能地保存到内存中,同样也是要避免把中间结果写入磁盘。默认情况下,所有的内存都是分配给Reduce方法的,如果Reduce方法不怎么消耗内存,可以mapred.inmem.merge.threshold设成0,mapred.job.reduce.input.buffer.percent设成1.0 在任务监控中可通过Spilled records counter来监控写入磁盘的数,但这个值是包括map和reduce的 对于IO方面,可以Map的结果可以使用压缩,同时增大buffer size(io.file.buffer.size,默认4kb)

你好,我是王知无,一个大数据领域的硬核原创作者。
做过后端架构、数据中间件、数据平台&架构&、算法工程化。
专注大数据领域实时动态&技术提升&个人成长&职场进阶,欢迎关注。
评论