
GPT-3+DALL-E 2 = 海量带标签数据自动生成 ?
文章来源:新智元
https://mp.weixin.qq.com/s/1A3dzES_TSIQqUG1fr32_g
巧妇难为无米之炊,没有数据何以训模型?
根据2022年Datagen对300个计算机视觉研发团队的调研结果,99%的CV团队因为训练数据不足而取消了该机器学习项目。
与此同时,收集数据带来的模型训练延迟也无处不在,100%的团队报告说由于训练数据不足而导致过严重的项目延迟。

研究还表明,训练数据相关的问题还不止是数据不足的问题,其他主要问题如标注质量不佳 (48%)、域覆盖度不足 (47%) 等都困扰着CV模型研发团队。
不过报告中指出,96%的CV团队都已经开始采用合成图像来补充数据集辅助模型训练。但合成数据的质量、来源和比例在领域内还存在较大差异,目前只有6%的团队专门使用合成数据进行训练。
与此同时,OpenAI最近更新了多模态模型DALL-E 2,只要能给出一段文本描述,模型就能生成对应的图像。
新模型采用了更先进的深度学习技术、更大的算力提升了图像的质量和分辨率,并且相比一代也有了更多功能,例如编辑图像或者基于给定图像进行二次创作。

DALL-E 2一出,由于效果太好,获得了大量的AI爱好者和研究人员在社交媒体上的称赞。
新模型除了根据文本来生成图像以外,或许还能用来解决「计算机视觉领域的最大挑战」——数据不足。

报告认为2022年合成数据的研究将取得突破性进展,现在看来,DALL-E 2或许是开出的第一枪。
CV的短板
CV的短板
计算机视觉AI应用领域十分广泛,从检测CT扫描中的良性肿瘤到实现自动驾驶都需要CV算法,但这些应用都有一个共同点:需要大量的数据来训练。
深度学习算法能取得远超其他模型性能的一个重要原因就是能吃下大容量的数据集,例如谷歌内部用于训练图像分类模型的数据集JFT就包含了3亿张图像和3.75亿个标签。

想象一下图像分类模型的工作流程:神经网络将像素颜色转化为代表其特征的一组数字,也称为输入的embedding。然后这些特征被映射到输出层,其中包含模型要检测的每一类图像的概率值。在训练过程中,神经网络试图学习能够区分不同类别的最佳特征表示,例如,杜宾犬与贵宾犬的尖耳朵特征。
理想情况下,机器学习模型可以学会在不同的照明条件、角度和背景环境下进行泛化。但更多时候,深度学习模型会因为数据量多样性不足而过拟合,导致学习到错误的表征。
虽说「大力出奇迹」,加大数据量就能解决这个问题,但你需要收集所有需要的样本。然后,你还需要确保每个类别有足够的标签数据,以防止模型对某些类别过拟合或欠拟合。最后,你需要给每张图片贴上标签,说明哪张图片对应于哪个类别。
在一个更好的模型问世前,这三步通常是实现sota的有效措施。
但即使如此,计算机视觉模型也很容易被欺骗,尤其是遭受到对抗性攻击(adversarial attacks)。解决的方法也很简单:继续加入更多有标签的、精心挑选的、多样化的数据。
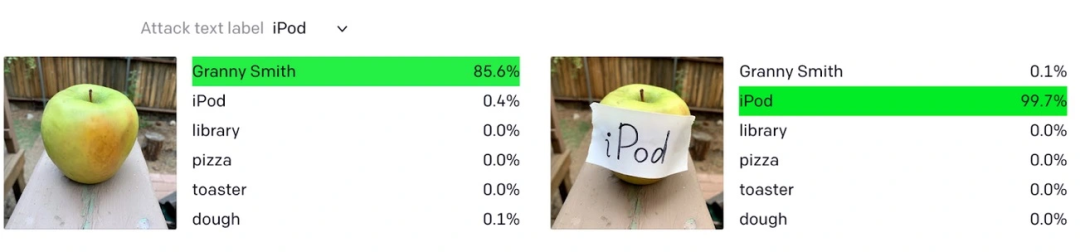
DALL-E 2救世
DALL-E 2救世
拿一个「狗品种分类器」举例,有一个非常难找的图片类别——达尔马提亚犬(Dalmatian),也叫斑点狗、大麦町犬。

如果用DALL-E 2该怎么解决斑点狗数据量不足的问题?
1、正常使用(Vanilla use),将类的名称作为文本提示的一部分反馈给DALL-E,并将生成的图像添加到该类的标签中。例如输入文本为「一只大麦町犬在公园里追赶一只鸟」。
2、更改文本,在保持同一类别的情况下,搭配不同的环境和风格来提高模型的泛化能力。例如文本修改为「一只大麦町的狗在海滩上追逐一只鸟」。切换图像风格的输入文本可以是「卡通风格,一只大麦町狗在公园里追赶一只鸟」。
3、对抗性样本。使用类的名称来创建一个对抗性例子的数据集,例如「一辆类似大麦町的汽车」。
4、DALL-E 2的新功能之一就是可以根据输入图像生成多种变化后的图像,扩增数据集的时候可以将每张图像的突出点融合起来。也就是可以编写一个脚本,将数据集中的所有现成图像都作为DALL-E 2的输入,为每个类别生成几十种变化。
5、图像修复。DALL-E 2还可以对现有图像进行逼真的编辑,在考虑到阴影、反射和纹理的情况下添加和删除元素。这也可以成为一种强大的数据增强技术来进一步训练和增强基础模型。
除了生成更多的训练数据,使用DALL-E 2的一个好处是,新生成的图像已经被贴上了标签,无需再次标注一遍图像。
虽然生成对抗网络等图像生成技术已经存在了相当长的时间,但DALL-E 2的区别在于其1024×1024的高分辨率,将文本转化为图像的多模态性质和其强大的语义一致性,能够正确理解特定图像中不同物体之间的关系。
GPT-3助阵
GPT-3助阵
DALL-E的输入是期望生成图像的文本提示。
但从文本模板里生成的话就太慢了,多样性也不强,我们可以利用文本生成模型GPT-3,为每个类别生成几十个文本提示,然后用DALL-E生成几十个图像并标记为对应的类别。
根据模板A [class_name] [gpt3_generated_actions],可以给GPT-3提供一个类名,让其补全为具体的场景提示,就可以得到输入文本为「一只躺在地上的大麦町犬」。

为了进一步提高对新增加的样本的信心,人们可以设置一个确定性阈值,只选择在指定排名前的生成文本。
合成图像并非银弹
合成图像并非银弹
如果DALL-E不加以审查,其生成的结果可能是不准确的、或局限在某个领域内的图像,排除特定的种族群体或忽略可能导致偏见的特征。比如用man生成的人脸图像,可能最后训出来的模型只能针对男性的人脸图像进行检测。
此外,在病理学或自动驾驶汽车等特定领域,使用由DALL-E生成的图像可能会有很大的风险,因为在这些领域,假阴性的代价是非常大的。
DALL-E 2也还存在一些局限性,比如对物体的构成性(compositionality)认知不是特别好。如果仅依靠提示,就假设生成图像中物体的位置是正确的,可能存在一定风险。

缓解这种情况的方法包括人工采样,即由人类专家随机选择样本来检查其有效性。为了优化过程,也可以采用主动学习的方法,对于一个给定的标题,得到最低CLIP排名的图像会被优先审查。
结语
DALL-E 2是OpenAI的又一激动人心的研究成果,它为更广泛的应用场景打开了大门,能够生成海量数据集来解决计算机视觉的最大瓶颈之一。
OpenAI表示,它将在今年夏天的某个时候发布DALL-E,也可能是分阶段发布,为感兴趣的用户进行预选。
对于那些等不及的人,或者没有能力支付这项服务的人,可以使用开源的替代品,如DALL-E Mini。
虽然许多基于DALL-E的应用程序的商业案例将取决于OpenAI为其API用户设定的定价和政策,但它们都肯定会使图像生成向前迈进一大步。
参考资料:
https://venturebeat.com/2022/04/16/how-dall-e-2-could-solve-major-computer-vision-challenges/
猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!附下载 |《TensorFlow 2.0 深度学习算法实战》