
总结numpy中的ndarray,非常齐全
点击上方Python知识圈,设为星标
回复100获取100题PDF
阅读文本大概需要 5 分钟

# coding=utf-8import numpy as nparray_a = np.array([[1, 2, 3], [4, 5, 6]])print(array_a)print('ndarray的维度: ', array_a.ndim)print('ndarray的形状: ', array_a.shape)print('ndarray的元素数量: ', array_a.size)print('ndarray中的数据类型: ', array_a.dtype)print(type(array_a))
[[1 2 3][4 5 6]]ndarray的维度: 2ndarray的形状: (2, 3)ndarray的元素数量: 6ndarray中的数据类型: int32<class 'numpy.ndarray'>
二、ndarray的维度和形状
array_b = np.array([1, 1, 1])array_c = np.array([[2, 2, 2], [2, 2, 2]])array_d = np.array([[[3, 3, 3], [3, 3, 3]], [[3, 3, 3], [3, 3, 3]]])print(array_b, '\n{}'.format(array_c), '\n{}'.format(array_d))print(array_b.shape, array_c.shape, array_d.shape)
[][][]][][]][][]]](3,) (2, 3) (2, 2, 3)
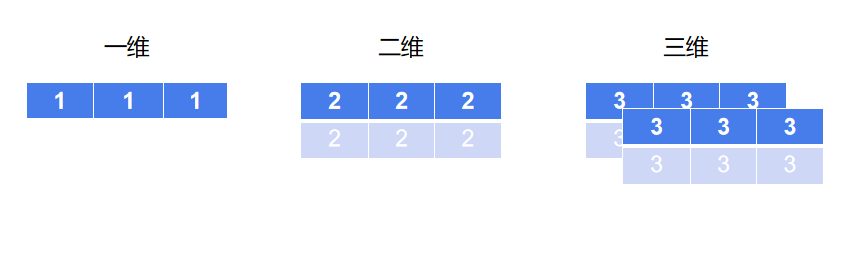
array_b是一个一维数组,数组中有三个数据。array_c是一个二维数组,数组中有2*3个数据。array_d是一个三维数组,数组中有2*2*3个数据。所以它们的形状分别是(3,) 、(2, 3)和 (2, 2, 3)。用图形表示如下:
| 名称 | 描述 | 简写 |
|---|---|---|
| np.bool | 用一个字节存储的布尔类型(True或False),在数据分析中很常用。 | 'b' |
| np.int8 | 一个字节大小,-128至127,不常用。 | 'i' |
| np.int16 | 整数,-32768至32767,不常用。 | 'i2' |
| np.int32 | 整数,-2^31至2^32-1,常用。 | 'i4' |
| np.int64 | 整数,-2^63至2^63-1,常用,一般整数默认为np.int64或np.int32。 | 'i8' |
| np.uint8 | 无符号整数,0至255,不常用。 | 'u' |
| np.uint16 | 无符号整数,0至65535,不常用。 | 'u2' |
| np.uint32 | 无符号整数,0至2^32-1,常用。 | 'u4' |
| np.uint64 | 无符号整数,0至2^64-1,常用。 | 'u8' |
| np.float16 | 16位半精度浮点数,正负号1位,指数5位,精度10位,不常用。 | 'f2' |
| np.float32 | 32位单精度浮点数,正负号1位,指数8位,精度23位,不常用。 | 'f4' |
| np.float64 | 64位双精度浮点数,正负号1位,指数11位,精度52位,常用。 | 'f8' |
| np.complex64 | 复数,分别用两个32位浮点数表示实部和虚部,基本不会用。 | 'c8' |
| np.complex128 | 复数,分别用两个64位浮点数表示实部和虚部,基本不会用。 | 'c16' |
| np.object_ | python对象,常用。 | 'O' |
| np.string_ | 字符串,常用。 | 'S' |
| np.unicode_ | unicode类型,不常用。 | 'U' |
四、修改ndarray的形状和数据类型
array_e = np.array([[1, 2, 3], [4, 5, 6]])print(array_e, array_e.shape)array_e1 = array_e.reshape((3, 2))print(array_e1, array_e1.shape)array_e2 = array_e.Tprint(array_e2, array_e2.shape)
[][]] (2, 3)[][][]] (3, 2)[][][]] (3, 2)
array_f = np.array([[1, 2, 3], [4, 5, 6]])print(array_f, array_f.dtype)array_f1 = array_f.astype(np.int64)print(array_f1, array_f1.dtype)
[][]] int32[][]] int64
五、ndarray的多种生成和创建方法
array_g = np.ones((2, 3), order='F')print(array_g, array_g.dtype)array_h = np.zeros((3, 3), dtype='int64')print(array_h, array_h.dtype)array_i = np.ones_like([[1, 2, 3], [4, 5, 6]])print(array_i, array_i.dtype)array_j = np.zeros_like([[1, 2, 3], [4, 5, 6]])print(array_j, array_j.dtype)
[][]] float64[][][]] int64[][]] int32[][]] int32
ones_like(a[, dtype, order, subok]): 生成全为1的ndarray,形状与已知数组相同。a为必传参数,传入一个形似array的数据(array_like,通常是嵌套列表或数组)。dtype表示数组中存储的数据类型,默认与传入的数组相同。另外两个参数通常不关注。
array_k = np.full((2, 3), 2)print(array_k, array_k.dtype)array_l = np.full_like([[1, 2, 3], [4, 5, 6]], 3)print(array_l, array_l.dtype)array_m = np.empty((2, 3))print(array_m, array_m.dtype)array_n = np.empty((2, 4))print(array_n, array_n.dtype)
[][]] int32[][]] int32[][]] float64[][]] float64
array_o = np.arange(1, 10, 2)array_p = np.linspace(0, 20, 5, retstep=True)array_q = np.linspace(array_o, 5, 3)array_r = np.logspace(0, 100, 6)print(array_o, '\n{}'.format(array_p), '\n{}'.format(array_q), '\n{}'.format(array_r))
[1 3 5 7 9](array([ 0., 5., 10., 15., 20.]), 5.0)[[1. 3. 5. 7. 9.][3. 4. 5. 6. 7.][5. 5. 5. 5. 5.]][1.e+000 1.e+020 1.e+040 1.e+060 1.e+080 1.e+100]
array_s = np.random.randint(1, 10, 5)array_t = np.random.rand(5)array_u = np.random.uniform(size=5)array_v = np.random.randn(5)array_w = np.random.normal(10, 1, 5)print(array_s, '\n{}'.format(array_t), '\n{}'.format(array_u), '\n{}'.format(array_v), '\n{}'.format(array_w))
[1 7 4 2 8][0.68173299 0.92899918 0.01771993 0.03010565 0.74799694][0.97895281 0.67811682 0.15493234 0.04435618 0.15152692][ 1.24094827 1.27898853 -1.42507622 1.97560767 -0.43269307][11.24927114 10.07827993 9.83908081 10.94827526 10.14160875]
array_x = np.array([(5, 5, 5), [5, 5, 5]])array_y = np.asarray(array_x)array_z = np.copy(array_x)print(array_x, '\n{}'.format(array_y), '\n{}'.format(array_z))
[[5 5 5][5 5 5]][[5 5 5][5 5 5]][[5 5 5][5 5 5]]
array_x[0][1] = 6print(array_x, '\n{}'.format(array_y), '\n{}'.format(array_z))
[[5 6 5][5 5 5]][[5 6 5][5 5 5]][[5 5 5][5 5 5]]
array1 = np.array([[[1, 2, 3, 4], [3, 4, 5, 6]], [[7, 8, 9, 10], [9, 10, 11, 12]]])print(array1, array1.shape)print(array1[1])print(array1[1][0])print(array1[1, 0])print(array1[0, :1, 1:3])
[][]][][]]] (2, 2, 4)[][]][][][]]
array2 = np.unique(array1)print(array2)
[ 1 2 3 4 5 6 7 8 9 10 11 12]七、ndarray的运算
1. 逻辑运算
array3 = np.array([[1, 2, 3], [4, 5, 6]])print(np.all(array3 > 1))print(np.any(array3 > 1))
FalseTrue
array4 = np.where(array3 > 3, 1, 0)print(array4)array5 = np.where(np.logical_and(array3 > 2, array3 < 5), 1, 0)print(array5)array6 = np.where(np.logical_or(array3 < 2, array3 > 5), 1, 0)print(array6)
[[0 0 0][1 1 1]][[0 0 1][1 0 0]][[1 0 0][0 0 1]]
array7 = np.array([[1, 3, 5], [7, 9, 11]])print('最小值:', np.min(array7), np.min(array7, axis=0))print('最大值:', np.max(array7), np.max(array7, axis=1))print('中位数:', np.median(array7))print('平均值:', np.mean(array7))print('标准差:', np.std(array7))print('方差:', np.var(array7))print('最小值的索引:', np.argmin(array7))print('最大值的索引:', np.argmax(array7))
最小值:1 [1 3 5]最大值:11 [ 5 11]中位数:6.0平均值:6.0标准差:3.415650255319866方差:11.666666666666666最小值的索引:0最大值的索引:5
八、ndarray之间的运算
array8 = np.array([[1, 2, 3], [4, 5, 6]])print(array8 + 2)array9 = np.array([[2, 2, 2], [2, 2, 2]])print(array8 * array9)
[[3 4 5][6 7 8]][[ 2 4 6][ 8 10 12]]
array10 = np.array([[[1, 1, 1], [1, 1, 1]], [[1, 1, 1], [1, 1, 1]]])print(array8 * array10)
[[[1 2 3][4 5 6]][[1 2 3][4 5 6]]]
array11 = np.array([[1, 1, 1, 1], [1, 1, 1, 1]])print(array8 * array11)
ValueError: operands could not be broadcast together with shapes (2,3) (2,4)array12 = np.array([[1, 10]])array13 = np.array([[1, 2, 3], [4, 5, 6]])print(array12.shape, array13.shape)print(np.mat(array12) * np.mat(array13))print(np.matmul(array12, array13))print(np.dot(array12, array13))
(1, 2) (2, 3)[]][]][]]
array14 = np.array([[1, 2, 3], [4, 5, 6]])array15 = np.array([[1, 1, 1], [2, 2, 2]])print(np.concatenate([array14, array15], axis=1))print(np.concatenate([array14, array15], axis=0))print(np.hstack([array14, array15]))print(np.vstack([array14, array15]))
[[1 2 3 1 1 1][4 5 6 2 2 2]][[1 2 3][4 5 6][1 1 1][2 2 2]][[1 2 3 1 1 1][4 5 6 2 2 2]][[1 2 3][4 5 6][1 1 1][2 2 2]]
array16 = np.array([1, 2, 3, 4, 5, 6])print(np.split(array16, 2))print(np.split(array16, [2, 3, 5]))
[array([1, 2, 3]), array([4, 5, 6])][array([1, 2]), array([3]), array([4, 5]), array([6])]
十、ndarray读写文件
data1,data2,data3,data41,2,3,45,6,,78,,9,10
array17 = np.genfromtxt('array.csv', delimiter=',', skip_header=1)print(array17)np.savetxt('save.csv', array17, fmt='%.0f', delimiter=',')
[[ 1. 2. 3. 4.][ 5. 6. nan 7.][ 8. nan 9. 10.]]
1,2,3,45,6,nan,78,nan,9,10
总结
往期推荐 01 02 03
↓点击阅读原文查看pk哥原创视频
我就知道你“在看” 
评论