
NumPy库入门教程:基础知识总结

视学算法 | 作者
知乎专栏 | 来源
1

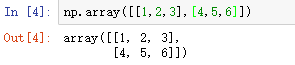






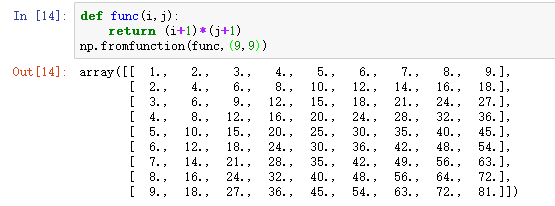
2


3
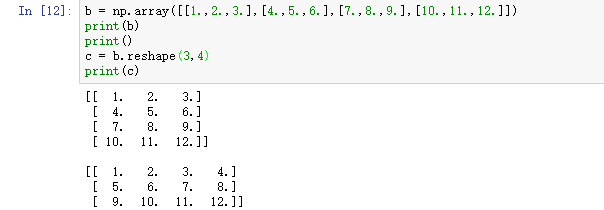

4



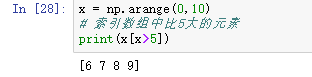

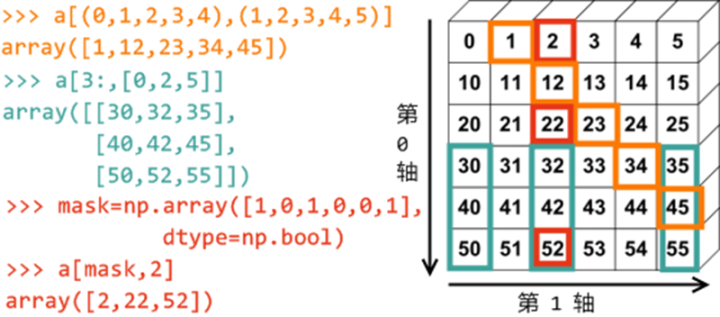
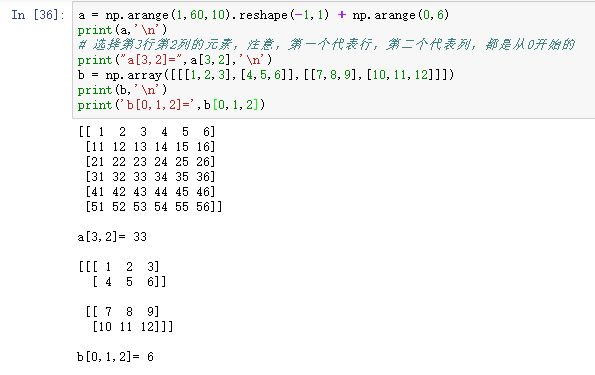
5

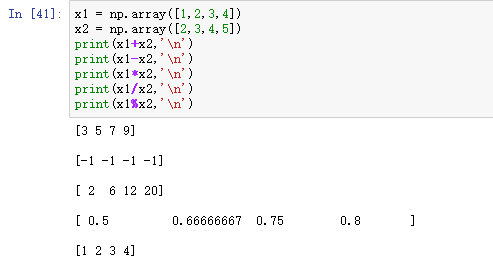
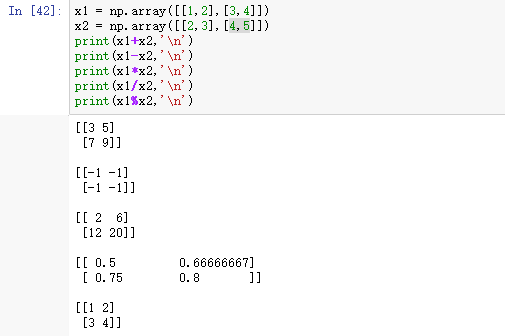

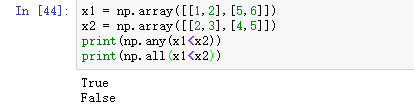





6

7

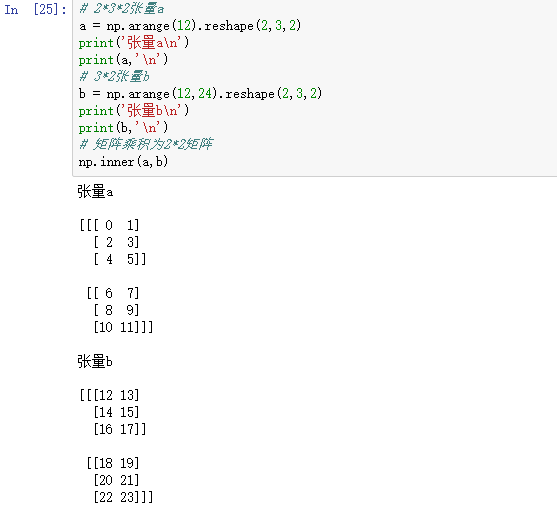


8
np.save(“a.npy”, a) # 将array a存入a.npy文件中c = np.load( “a.npy” ) # 从a.npy文件中读回array a
np.savetxt(“a.txt”, a) # 将array a存入a.txt文件中np.loadtxt(“a.txt”) # 从a.txt文件中读回array a--end-- 如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「hych666」,欢迎添加我的微信,更多精彩,尽在我的朋友圈。 ↓扫描二维码添加小编↓ 推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓
评论