
浪尖以案例聊聊spark 3.0 sql的动态分区裁剪
浪尖聊大数据
共 1943字,需浏览 4分钟
· 2021-06-22
麻烦大家给浪尖投个票,主要是目前公共号名称太单一了,以后的分享的知识会扩充到数据智能,用户画像等领域。
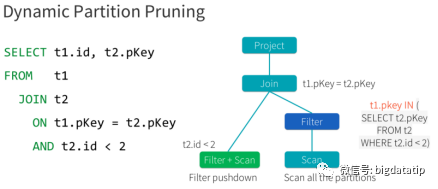
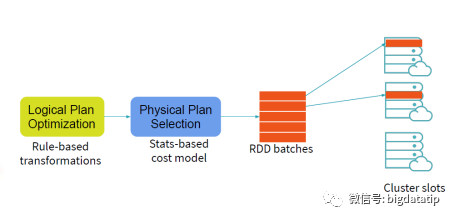
本文主要讲讲,spark 3.0之后引入的动态分区裁剪机制,这个会大大提升应用的性能,尤其是在bi等场景下,存在大量的where条件操作。
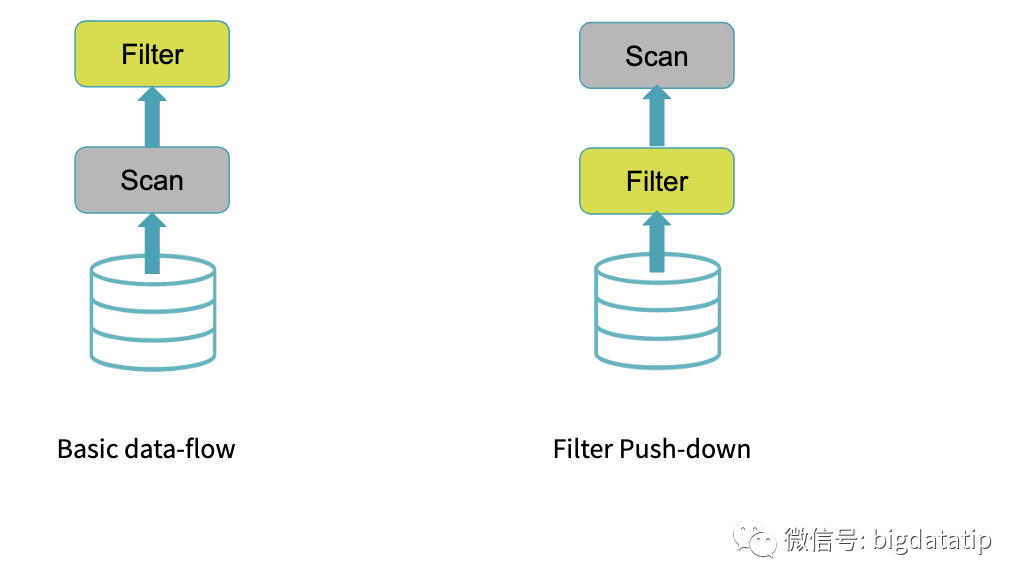
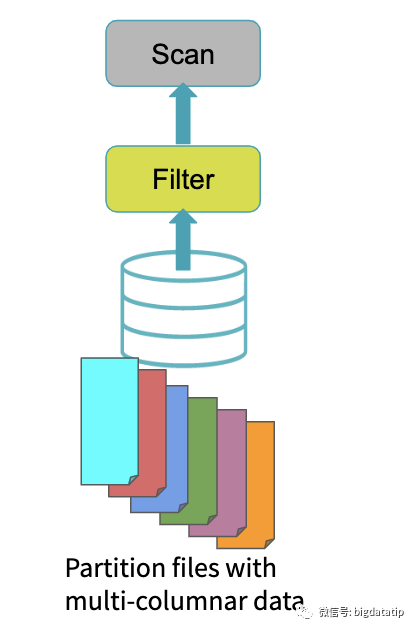
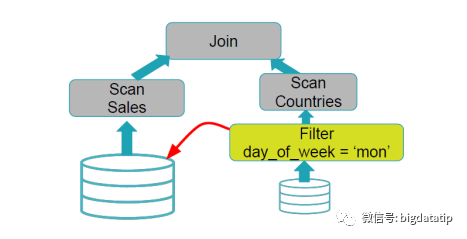
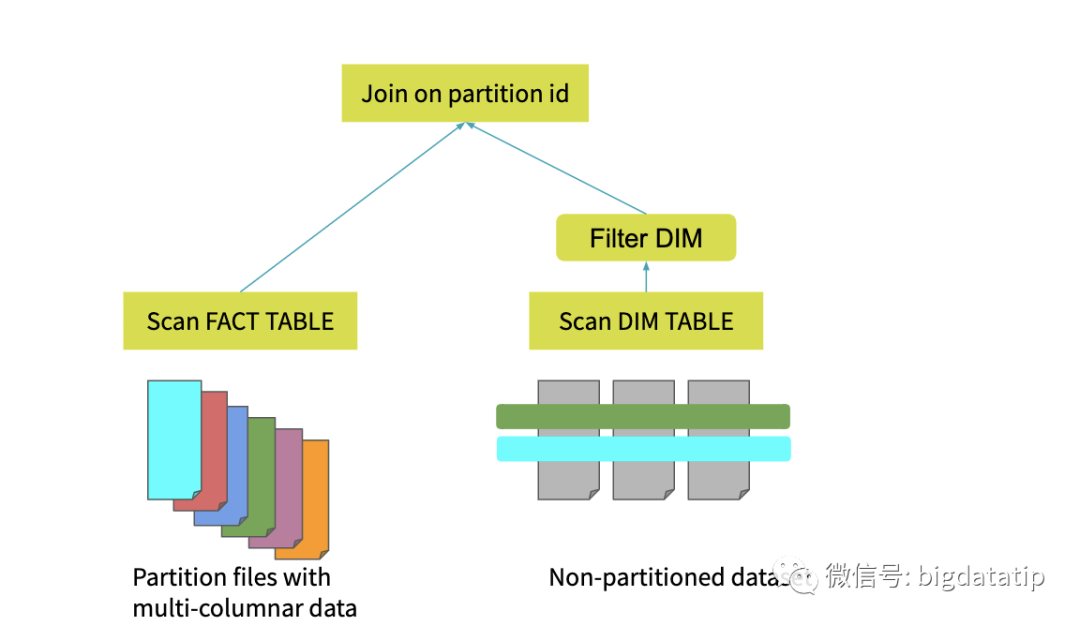
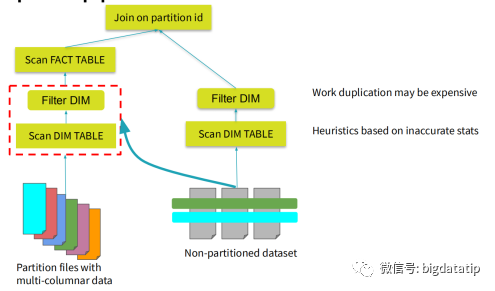
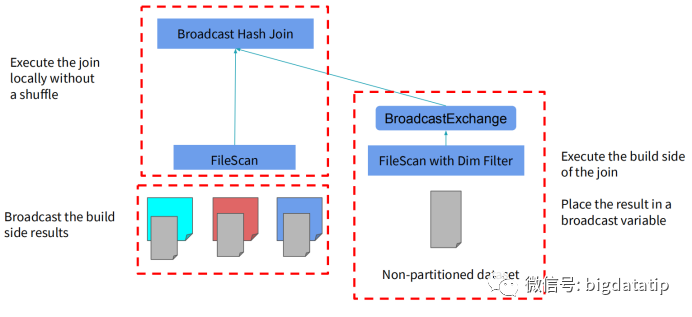
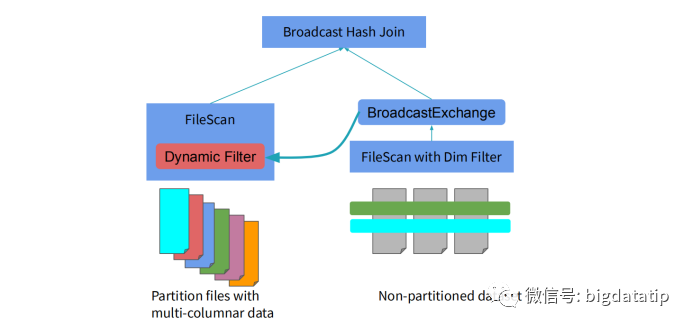
动态分区裁剪比谓词下推更复杂点,因为他会整合维表的过滤条件,生成filterset,然后用于事实表的过滤,从而减少join。当然,假设数据源能直接下推执行就更好了,下推到数据源处,是需要有索引和预计算类似的内容。
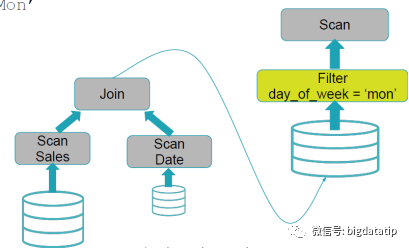
SELECT * FROM Sales WHERE day_of_week = ‘Mon’
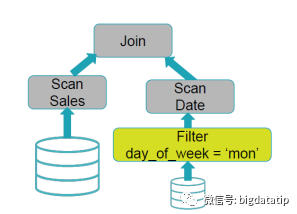
SELECT * FROM Sales JOIN Date WHERE Date.day_of_week = ‘Mon’;
评论
Astro Spark SQLHBase 的 Spark SQL
华为2015年7月20日在O'Reilly Open Source Convention (OSCO
Astro Spark SQLHBase 的 Spark SQL
0
Astro Spark SQLHBase 的 Spark SQL
华为2015年7月20日在O'ReillyOpenSourceConvention(OSCON)上宣布SparkSQLonHBasepackage正式开源。SparkSQLonHBasepackage
Astro Spark SQLHBase 的 Spark SQL
0