
榨干服务器:一次惨无人道的性能优化
背景
做过2B类系统的同学都知道,2B系统最恶心的操作就是什么都喜欢批量,这不,我最近就遇到了一个恶心的需求——50个用户同时每人导入1万条单据,每个单据七八十个字段,请给我优化。
Excel导入技术选型
说起Excel导入的需求,很多同学都做过,也很熟悉,这里面用到的技术就是POI系列了。
但是,原生的POI很难用,需要自己去调用POI的API解析Excel,每换一个模板,你都要写一堆重复而又无意义的代码。
所以,后面出现了EasyPOI,它基于原生POI做了一层封装,使用注解即可帮助你自动解析Excel到你的Java对象。
EasyPOI虽然好用,但是数据量特别大之后呢,会时不时的来个内存溢出,甚是烦恼。
所以,后面某里又做了一些封装,搞出来个EasyExcel,它可以配置成不会内存溢出,但是解析速度会有所下降。
如果要扣技术细节的话,就是DOM解析和SAX解析的区别,DOM解析是把整个Excel加载到内存一次性解析出所有数据,针对大Excel内存不够用就OOM了,而SAX解析可以支持逐行解析,所以SAX解析操作得当的话是不会出现内存溢出的。
因此,经过评估,我们系统的目标是每天500万单量,这里面导入的需求非常大,为了稳定性考虑,我们最后选择使用EasyExcel来作为Excel导入的技术选型。
导入设计
我们以前也做过一些系统,它们都是把导入的需求跟正常的业务需求耦合在一起的,这样就会出现一个非常严重的问题:一损俱损,当大导入来临的时候,往往系统特别卡。
导入请求同其它的请求一样只能打到一台机器上处理,这个导入请求打到哪台机器哪台机器倒霉,其它同样打到这台机器的请求就会受到影响,因为导入占用了大量的资源,不管是CPU还是内存,通常是内存。
还有一个很操蛋的问题,一旦业务受到影响,往往只能通过加内存来解决,4G不行上8G,8G不行上16G,而且,是所有的机器都要同步调大内存,而实际上导入请求可能也就几个请求,导致浪费了大量的资源,大量的机器成本。
另外,我们导入的每条数据有七八十个字段,且在处理的过程中需要写数据库、写ES、写日志等多项操作,所以每条数据的处理速度是比较慢的,我们按50ms算(实际比50ms还长),那1万条数据光处理耗时就需要 10000 * 50 / 1000 = 500秒,接近10分钟的样子,这个速度是无论如何都接受不了的。
所以,我一直在思考,有没有什么方法既可以缩减成本,又可以加快导入请求的处理速度,同时,还能营造良好的用户体验?
经过苦思冥想,还真被我想出来一种方案:独立出来一个导入服务,把它做成通用服务。
导入服务只负责接收请求,接收完请求直接告诉前端收到了请求,结果后面再通知。
然后,解析Excel,解析完一条不做其它处理直接就把它扔到Kafka中,下游的服务去消费,消费完了,再发一条消息给Kafka告诉导入服务这条数据的处理结果,导入服务检测到所有行数都收到了反馈,再通知前端这次导入完成了。(前端轮询)
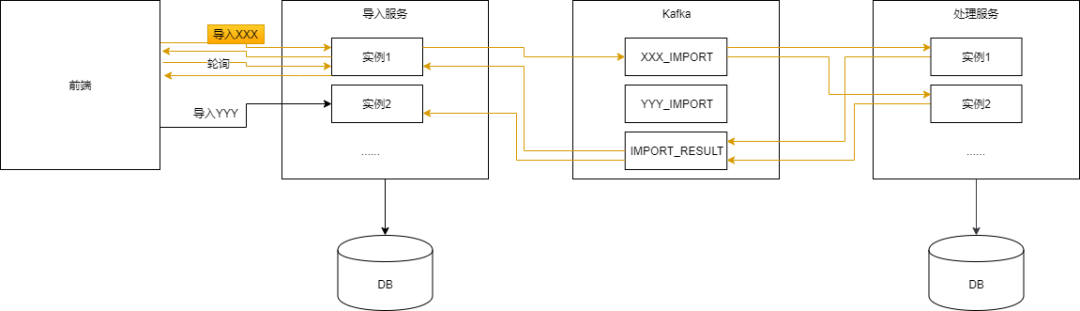
如上图所示,我们以导入XXX为例描述下整个流程:
前端发起导入XXX的请求;
后端导入服务接收到请求之后立即返回,告诉前端收到了请求;
导入服务每解析一条数据就写入一行数据到数据库,同时发送该数据到Kafka的XXX_IMPORT分区;
处理服务的多个实例从XXX_IMPORT的不同分区拉取数据并处理,这里的处理可能涉及数据合规性检查,调用其他服务补齐数据,写数据库,写ES,写日志等;
待一条数据处理完成后给Kafka的IMPORT_RESULT发送消息说这条数据处理完了,或成功或失败,失败需要有失败原因;
导入服务的多个实例从IMPORT_RESULT中拉取数据,更新数据库中每条数据的处理结果;
前端轮询的接口在某一次请求的时候发现这次导入全部完成了,告诉用户导入成功;
用户可以在页面上查看导入失败的记录并下载;
这就是整个导入的过程,下面就开始了踩坑之旅,你准备好了吗?
初步测试
经过上面的设计,我们测试导入1万条数据只需要20秒,比之前预估的10分钟快了不止一星半点。
但是,我们发现一个很严重的问题,当我们导入数据的时候,查询界面卡到爆,需要等待10秒的样子查询界面才能刷出来,从表象来看,是导入影响了查询。
初步怀疑
因为我们查询只走了ES,所以,初步怀疑是ES的资源不够。
但是,当我们查看ES的监控时发现,ES的CPU和内存都还很充足,并没有什么问题。
然后,我们又仔细检查了代码,也没有发现明显的问题,而且服务本身的CPU、内存、带宽也没有发现明显的问题。
真的神奇了,完全没有了任何思路。
而且,我们的日志也是写ES的,日志的量比导入的量还更大,查日志的时候也没有发现卡过。
所以,我想,直接通过Kibana查询数据试试。
说干就干,在导入的同时,在Kibana上查询数据,并没有发现卡,结果显示只需要几毫秒数据就查出来了,更多的耗时是在网络传输上,但是整体也就1秒左右数据就刷出来了。
因此,可以排除是ES本身的问题,肯定还是我们的代码问题。
此时,我做了个简单的测试,我把查询和导入的处理服务分开,发现也不卡,秒级返回。
答案已经快要浮出水面了,一定是导入处理的时候把ES的连接池资源占用完了,导致查询的时候拿不到连接,所以,需要等待。
通过查看源码,最终发现ES的连接数是在RestClientBuilder类中写死的,DEFAULT_MAX_CONN_PER_ROUTE=10,DEFAULT_MAX_CONN_TOTAL=30,每个路由最大10,总连接数最大30,而且更操蛋的是,这两个配置是写死在代码里面的,没有参数可以配置,只能通过修改代码来实现了。
这里也可以做个简单的估算,我们的处理服务部署了4台机器,每台机器一共可以建立30条连接,4台机器就是120条连接,导入一万单如果平均分配,每条连接需要处理 10000 / 120 = 83条数据,每条数据处理100ms(上面用的50ms,都是估值)就是8.3秒,所以,查询的时候需要等待10秒左右,比较合理。
直接把这两个参数调大10倍到100和300,(关注公号彤哥读源码一起学习一起浪)再部署服务,测试发现导入的同时,查询也正常了。
接下来,我们又测试了50个用户同时导入1万单,也就是并发导入50万单,按1万单20秒来算,总共耗时应该在 50*20=1000秒/60=16分钟,但是,测试发现需要耗时30分钟以上,这次瓶颈又在哪里呢?
再次怀疑
我们之前的压测都是基于单用户1万单来测试的,当时的服务器配置是导入服务4台机器,处理服务4台机器,根据上面我们的架构图,按理说导入服务和处理服务都是可以无限扩展的,只要加机器,性能就能上去。
所以,首先,我们把处理服务的机器加到了25台(我们基于k8s,扩容非常方便,改个数字的事),跑一下50万单,发现没有任何效果,还是30分钟以上。
然后,我们把导入服务的机器也加到25台,跑了一下50万单,同样地,发现也没有任何效果,此时,有点怀疑人生了。
通过查看各组件的监控,发现,此时导入服务的数据库有个指标叫做IOPS,已经达到了5000,并且持续的在5000左右,IOPS是什么呢?
它表示一秒读写IO多少次,跟TPS/QPS差不多,说明MySQL一秒与磁盘的交互次数,一般来说,5000已经是非常高的了。
目前来看,瓶颈可能在这里,再次查看这个MySQL实例的配置,发现它使用的是超高IO,实际上还是普通的硬盘,想着如果换成SSD会不会好点呢。
说干就干,联系运维重新购买一个磁盘是SSD的MySQL实例。
切换配置,重新跑50万单,这次的时间果然降下来了,只需要16分钟了,接近降了一半。
所以,SSD还是要快不少的,查看监控,当我们导入50万单的时候,SSD的MySQL的IOPS能够达到12000左右,快了一倍多。
后面,我们把处理服务的MySQL磁盘也换成SSD,时间再次下降到了8分钟左右。
你以为到这里就结束了嘛(关注公号彤哥读源码一起学习一起浪)?
思考
上面我们说了,根据之前的架构图,导入服务和处理服务是可以无限扩展的,而且我们已经分别加到了25台机器,但是性能并没有达到理想的情况,让我们来计算一下。
假设瓶颈全部在MySQL,对于导入服务,我们一条数据大概要跟MySQL交互4次,整个Excel分成头表和行表,第一条数据是插入头表,后面的数据是更新头表、插入行表,等处理完了会更新头表、更新行表,所以按12000的IOPS来算的话,MySQL会消耗我们 500000 * 4 / 12000 / 60= 2.7分钟,同样地,处理服务也差不多,处理服务还会去写ES,但处理服务没有头表,所以时间也按2.7分钟算,但是这两个服务本质上是并行的,没有任何关系,所以总的时间应该可以控制在4分钟以内,因此,我们还有4分钟的优化空间。
再优化
经过一系列排查,我们发现Kafka有个参数叫做kafka.listener.concurrency,处理服务设置的是20,而这个Topic的分区是50,也就是说实际上我们25台机器只使用了2.5台机器来处理Kafka中的消息(猜测)。
找到了问题点,就很好办了,先把这个参数调整成2,保持分区数不变,再次测试,果然时间降下来了,到5分钟了,后面经过一系列调整测试,发现分区数是100,concurrency是4的时候效率是最高的,最快可以达到4分半的样子。
至此,整个优化过程告一段落。
总结
现在我们来总结一下一共优化了哪些地方:
导入Excel技术选型为EasyExcel,确实非常不错,从来没出现过OOM;
导入架构设计修改为异步方式处理,参考秒杀架构;
Elasticsearch连接数调整为每个路由100,最大连接数300;
MySQL磁盘更换为SSD;
Kafka优化分区数和kafka.listener.concurrency参数;
另外,还有很多其它小问题,限于篇幅和记忆,无法一一讲出来。
后期规划
通过这次优化,我们也发现了当数据量足够大的时候,瓶颈还是在存储这块,所以,是不是优化存储这块,性能还可以进一步提升呢?
答案是肯定的,比如,有以下的一些思路:
导入服务和处理服务都修改为分库分表,不同的Excel落入不同的库中,减轻单库压力;
写MySQL修改为批量操作,减少IO次数;
导入服务使用Redis来记录,而不是MySQL;
但是,这次要不要把这些都试一遍呢,其实没有必要,通过这次压测,我们至少能做到心里有数就可以了,真的等到量达到了那个级别,再去优化也不迟。