
避免分布式系统的级联故障 | IDCF

来源:DevOpsXP 作者:XP 原文:How to Avoid Cascading Failures in Distributed Systems 发表于 2020年2月20日 https://www.infoq.com/articles/anatomy-cascading-failure/ 原作者:Laura Nolan
级联故障与混沌工程有什么关系?混沌工程能发现级联故障吗?
译者语:本文虽然与混沌工程无直接相关,但是其中提到的各种真实发生的事故,故障都是混沌工程致力于发现和解决的。发掘问题的本质能够帮助我们在分析系统架构,详细周密的设计混沌工程实验的时候更有针对性。很多掩盖在表面现象之下的根本原因往往都需要深入分析各种内在外在的条件,而不是仅仅的把一台实例的CPU负载提高到100%!通过了解和科学的学习分析级联故障发生的原因,我们将能够更缜密的进行混沌工程实验。
译者再次精炼了本文要点:
级联故障是系统中正反馈循环引起的使原始问题越来越严重的灾难。 有时候添加资源并不会解除故障。 有时候人为介入关闭系统重启是唯一解决方案。 分布式系统的级联故障风险与生俱来。
级联故障是牵涉到某些类型的反馈机制的故障。在分布式软件系统中级联故障通常涉及到反馈机制的循环回路,它们通常会引起能力下降,延迟增加或者一连串错误。而它们从系统其他组件得到的响应使得原始的问题变得更加严重。 向你的服务系统中添加资源和扩展能力通常很难使你逃脱级联故障。健康的新实例会被过量的负载立刻冲击而达到负载的饱和状态。在这样的情况下,服务能力始终无法处理现有的负载。 有些时候关闭整个系统并重新引入流量是惟一修复这个问题的办法。 潜在的级联故障,虽然不是大部分,但是在很多分布式系统中是与生俱来的。如果你并没有在你的系统中遇到,并不代表你的系统会幸免于此,因为你的系统也许仅仅在它的安全舒适范围之内运行而并没有到达其极限。对于明天或是下周是否发生,并没有任何保证。
作者语:在这篇文章中我将讨论生产事故的公开解释。我对于所有有关的工程组织致以最崇高的敬意。分布式系统的运行者都经历过系统的宕机,对于生产环境的事故,并不是所有组织都愿意开放并足够诚实的记录清晰的公开解释。而那些能够分享的企业和组织,真是值得感激和尊敬的(有时候还有我们的同情!)。
一、什么是级联故障


二、为什么级联故障如此糟糕
三、反馈循环:级联故障是怎么干掉我们的系统的
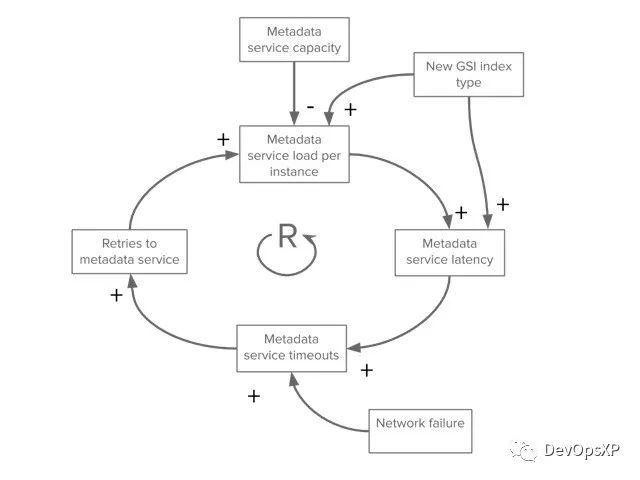
四、从级联故障中恢复
五、六种级联故障的反例
const MAX_RETRIES = 500
for i := 0; i < MAX_RETRIES; i++ {
_, err := doServerRequest()
if err == nil {
break
}
}当Square的工程师们推出了一个减小重试次数的修复之后,这个回馈循环立刻结束并且他们的服务也变得正常了。
客户端在重试之间应该使用一个指数退避的方式。为退避的等待时间增加一个小的随机噪音或者震动也是很好的实践。这个实践使得重试在时间上产生了一些波动,这样服务就不会被正常的两次重试负载同时的访问到,因为上述的波动使得服务有几毫秒的‘暂时故障’。重试的次数和等待时间是应用程序独有的。面向用户的请求应该快速失败或者返回某些降级的结果,而批处理或者异步处理的结果则可以等待长一些时间。
这就是Golang的带有指数退避和抖动的重试代码示例:
const MAX_RETRIES = 5
const JITTER_RANGE_MSEC = 200
steps_msec := []int{100, 500, 1000, 5000, 15000}
rand.Seed(time.Now().UTC().UnixNano())
for i := 0; i < MAX_RETRIES; i++ {
_, err := doServerRequest()
if err == nil {
break
}
time.Sleep(time.Duration(steps_msec[i] + rand.Intn(JITTER_RANGE_MSEC)) *
time.Millisecond)
}现代的最佳实践超越了指数退避和抖动。Circuit Breaker[10]应用模式包裹了外部调用的请求并且跟踪其随时间推移的成功和失败。一系列的失败调用会使断路器触发,也就是说不能再有外部服务的失败调用,一旦客户端再有失败的请求便会立即得到一个错误。断路器会定期地允许一个请求通过用于探测外部服务。一旦探针请求成功,断路器会重置并且恢复开始对外部请求的调用。
断路器非常强大因为他能在来自客户端的请求中分享所有请求的状态给统一的后端,而指数退避只能针对单独一个具体的请求。断路器比起其他途径更能减轻挣扎中的后台服务的负载。这是一个Golang的断路器实施[11]。Netflix的Hystrix包含了一个Java断路器[12]。
反例模式3:非法输入导致崩溃-"死亡查询"
所谓"死亡查询"是能够造成你系统崩溃的请求。客户端会发送死亡请求,使得服务的一个实例崩溃,然后(客户端)会重试使得更多的实例宕机。由于所剩无几的实例会在正常的负载下变得超载,所以减少的能力会使得你的整体服务进而崩溃。
这种场景可以是你服务被攻击的一种结果,但是也许并不是恶意的,仅仅是运气不好。这也是为什么非预期的输入从不会造成退出或崩溃是一个最佳实践。一个程序应该仅在内部状态看起来不正确的时候非预期的退出并且不再安全的继续服务。
模糊测试(Fuzz Testing)是一种自动化测试的实践,用来帮助我们探测程序是否在恶意的输入中崩溃。模糊测试在所以暴露给非信任的输入(任何你组织外部的)的服务上尤其重要。
反例模式4:接邻故障切换和多米诺效应
当整个数据中心或者可用区都宕机的时候你的系统会怎么样呢?如果你的答案是“故障切换到下一个最近的(数据中心或可用区)”那么你的系统就会有潜在的级联事故风险。

(图3 - 数据中心地图)
如果你失去了拓扑学上美国东海岸的数据用心,像上图所示,那么另一个在该地区的数据中心就会粗略的接收到两倍的负载。如果剩下的这个东海岸数据中心无法处理负载从而崩溃,那么负载就会主要地去向西海岸的数据中心(通常会比发往欧洲便宜)。如果西海岸的数据中心也崩溃,那么你剩下地区的数据中心也会一个接一个的崩溃:像多米诺骨牌一样。你预期用来提高系统稳定性故障切换计划引发了整个服务的宕机。
地理均衡系统需要从两个事情中抉择:要么确保故障切换负载不会使得其他数据中心过载,要么确保所有地方有很高的能力冗余。
基于IP Anycast(和大部分DNS服务和CDN相似)的系统通常产能过剩,特别地因为无限传播,它从英特网的多个地方为一个IP提供服务,使得你无法控制入境流量。
这个级别的产能过量失败是非常昂贵的。在很多系统中,使得有能力的数据中心直接处理负载是更合理的方式。这种方式往往通过DNS负载均衡来实现(比如NS1的intelligent traffic distribution[13])
反例模式5:故障导致工作升级
有的时候我们的服务在错误发生的时候确实也能工作。考虑一个假想的分布式数据存储系统,它把我们的数据分隔成块。我们想要每一块都有最小数量的备份,并且我们会定时周期的检查其数量是否正确。如果不正确,那么我们开始新的备份。这是一个伪代码片段:
replicaChecker()
while true {
for each block in filesystem.GetAllBlocks() {
if block.replicasHeartbeatedOK() < minReplicas {
block.StartCopyNewReplica()
}
}
}
}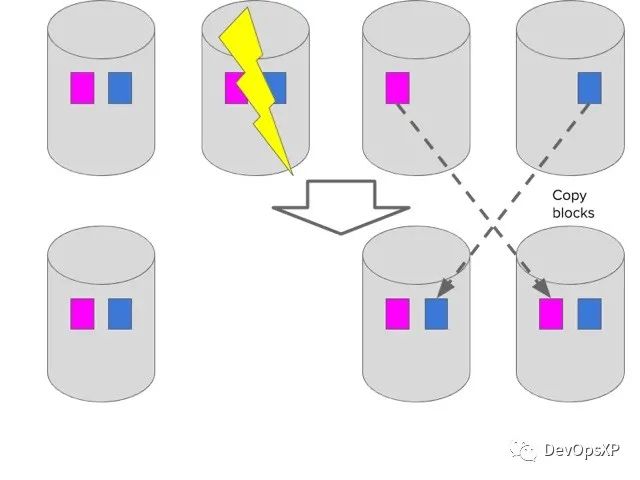
(图4 - 失败后数据块复制)
这个途径在我们失去一块儿数据的时候大概还能工作,或者失去很多服务器中的一个。那么如果我们失去了很大比例的服务器呢?一整个机柜呢?服务能力会下降,剩下的服务器则要变得十分忙碌因为要重新备份数据。我们没有给同时复制设置任何限制。这是该反馈循环的CLD图。
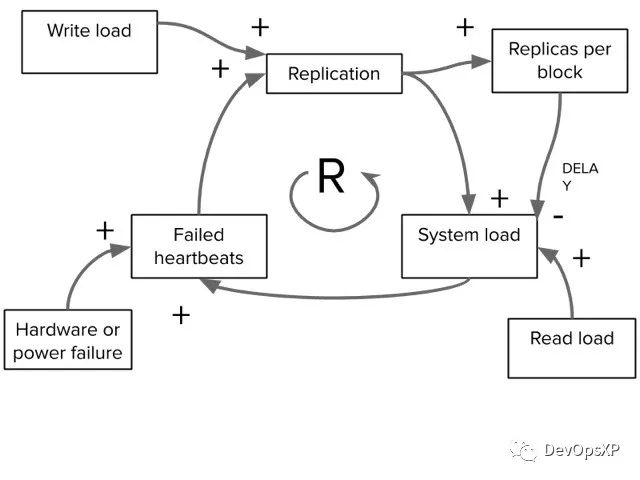
(图5 - 带有反馈回路的因果图)
通常围绕这个的做法是延迟复制(因为故障通常是短暂的),并且通过类似token bucket[14]的算法限制正在复制的进程数。下面的因果循环图描述了它是怎么改变系统的:我们仍然有反馈回路,但是现在这里有了一个内部平衡回路来防止反馈回路超速。
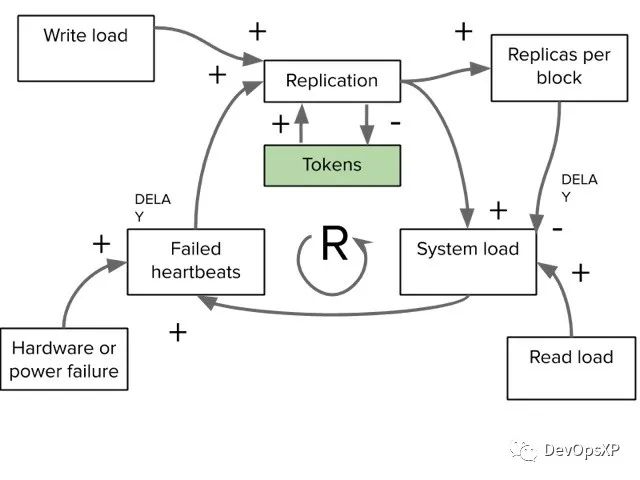
(图6 - 带有复制速率限制的因果图)
反例模式6: 长启动时间
有些时候服务设计启动时有许多工作要进行,比如从缓存中越多很多数据。这种模式最好要避免,有两个原因。首先这会造成任何形式的自动缩扩容非常困难:当你已经探测到一个实例的负载增加并且开启了一个你的启动慢(slow-to-start-up)的服务,你会陷入困境。第二方面,如果你的服务由于某些原因而失败(内存不足,或者死亡查询造成的崩溃),他会使得你需要很长时间让你的系统恢复到正常服务能力。这两种条件会让你的服务很容易的过载。
六、减少级联事故风险
潜在的级联故障,虽然不是大部分,但是在很多分布式系统中是与生俱来的。如果你并没有在你的系统中遇到,并不代表你的系统会幸免于此,因为你的系统也许仅仅在它的安全舒适范围之内运行而并没有到达其极限。对于明天或是下周是否发生,并没有任何保证。
我们已经列出了一些反例来帮助你避免和减小发生级联故障的风险。没有服务可以抵御不受控制的一串串负载。没有人想让他们的服务为错误服务,但是当你看到另一面是整个服务被每一个入境的请求按在地上摩擦的逐渐停顿下来的时候,这就没有那么邪恶了。
更多阅读
'Addressing Cascading Failures,' by Mike Ulrich, in Site Reliability Engineering: How Google runs Production Systems. 'Stability Patterns' chapter in Release It! by Michael T Nygard. 'Handling Overload' chapter by Alejandro Forero Cuervo in Site Reliability Engineering: How Google runs Production Systems.

[1] 2015年9月20日亚马逊DynamoDB在美东1区的持续了四个多小时的事故: https://aws.amazon.com/message/5467D2/ [2] Parsely's Kafkapocalyspe: https://blog.parse.ly/post/1738/kafkapocalypse/ [3] Kubernetes liveness probes: https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/ [4] Sptify在2013年的事故: https://labs.spotify.com/2013/06/04/incident-management-at-spotify/ [5] 接近不可接受的负载边界: https://www.usenix.org/conference/srecon18americas/presentation/schwartz [6] 2018年有一个故障的例子: https://status.duo.com/incidents/4w07bmvnt359 [7] Loadshedding: https://www.usenix.org/conference/srecon17europe/program/presentation/cruz [8] concurrency-limits: https://github.com/Netflix/concurrency-limits [9] Square在2017年三月的故障: https://medium.com/square-corner-blog/incident-summary-2017-03-16-2f65be39297 [10] Circuit Breaker: https://www.martinfowler.com/bliki/CircuitBreaker.html [11] 一个Golang的断路器实施: https://github.com/matttproud/golang_circuitbreaker [12] 一个Java断路器: https://github.com/Netflix/Hystrix/wiki/How-it-Works#CircuitBreaker [13] NS1的intelligent traffic distribution: https://ns1.com/blog/using-load-shedding-for-intelligent-traffic-distribution-1 [14] token bucket: https://en.wikipedia.org/wiki/Token_bucket [15] USENIX SREcon: https://www.usenix.org/srecon

大连站6月11-12日,北京站7月23-24日将举办线下公开课挑战赛,36小时内从0到1打造并发布一款产品。
企业组队参赛&个人参赛均可,赶紧上车~👇
